 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCambrian-P: Pose-Grounded Video Understanding
May 21, 2026Camera pose matters. The position and orientation of each viewpoint define a shared spatial coordinate frame that relates observations across video frames. Yet this signal is largely absent from multimodal LLMs (MLLMs) for video understanding, which process frames as isolated 2D snapshots, instead of the persistent scene humans perceive. We revisit pose as a lightweight supervisory signal and introduce Cambrian-P, a video MLLM augmented with per-frame learnable camera tokens and a pose regression head. With a carefully designed sampling scheme, the model achieves substantial gains of 4.5-6.5% on spatial reasoning benchmarks such as VSI-Bench, generalizes across eight additional spatial and general video QA benchmarks, and, as a byproduct, achieves state of the art streaming pose estimation on ScanNet. Surprisingly, training on pseudo-annotated poses from in-the-wild video further improves general video QA benchmarks, showing pose helps beyond spatial reasoning. Together, these results position camera pose as a fundamental signal for video models that reason about the physical world.
DMGD: Train-Free Dataset Distillation with Semantic-Distribution Matching in Diffusion Models
May 05, 2026Dataset distillation enables efficient training by distilling the information of large-scale datasets into significantly smaller synthetic datasets. Diffusion based paradigms have emerged in recent years, offering novel perspectives for dataset distillation. However, they typically necessitate additional fine-tuning stages, and effective guidance mechanisms remain underexplored. To address these limitations, we rethink diffusion based dataset distillation and propose a Dual Matching Guided Diffusion (DMGD) framework, centered on efficient training-free guidance. We first establish Semantic Matching via conditional likelihood optimization, eliminating the need for auxiliary classifiers. Furthermore, we propose a dynamic guidance mechanism that enhances the diversity of synthetic data while maintaining semantic alignment. Simultaneously, we introduce an optimal transport (OT) based Distribution Matching approach to further align with the target distribution structure. To ensure efficiency, we develop two enhanced strategies for diffusion based framework: Distribution Approximate Matching and Greedy Progressive Matching. These strategies enable effective distribution matching guidance with minimal computational overhead. Experimental results on ImageNet-Woof, ImageNet-Nette, and ImageNet-1K demonstrate that our training-free approach achieves significant improvements, outperforming state-of-the-art (SOTA) methods requiring additional fine-tuning by average accuracy gains of 2.1%, 5.4%, and 2.4%, respectively.
TaoBench: Do Automated Theorem Prover LLMs Generalize Beyond MathLib?
Mar 13, 2026Automated theorem proving (ATP) benchmarks largely consist of problems formalized in MathLib, so current ATP training and evaluation are heavily biased toward MathLib's definitional framework. However, frontier mathematics is often exploratory and prototype-heavy, relying on bespoke constructions that deviate from standard libraries. In this work, we evaluate the robustness of current ATP systems when applied to a novel definitional framework, specifically examining the performance gap between standard library problems and bespoke mathematical constructions. We introduce TaoBench, an undergraduate-level benchmark derived from Terence Tao's Analysis I, which formalizes analysis by constructing core mathematical concepts from scratch, without relying on standard Mathlib definitions, as well as by mixing from-scratch and MathLib constructions. For fair evaluation, we build an agentic pipeline that automatically extracts a compilable, self-contained local environment for each problem. To isolate the effect of definitional frameworks, we additionally translate every problem into a mathematically equivalent Mathlib formulation, yielding paired TaoBench-Mathlib statements for direct comparison. While state-of-the-art ATP models perform capably within the MathLib framework, performance drops by an average of roughly 26% on the definitionally equivalent Tao formulation. This indicates that the main bottleneck is limited generalization across definitional frameworks rather than task difficulty. TaoBench thus highlights a gap between benchmark performance and applicability, and provides a concrete foundation for developing and testing provers better aligned with research mathematics.
LoGeR: Long-Context Geometric Reconstruction with Hybrid Memory
Mar 03, 2026Feedforward geometric foundation models achieve strong short-window reconstruction, yet scaling them to minutes-long videos is bottlenecked by quadratic attention complexity or limited effective memory in recurrent designs. We present LoGeR (Long-context Geometric Reconstruction), a novel architecture that scales dense 3D reconstruction to extremely long sequences without post-optimization. LoGeR processes video streams in chunks, leveraging strong bidirectional priors for high-fidelity intra-chunk reasoning. To manage the critical challenge of coherence across chunk boundaries, we propose a learning-based hybrid memory module. This dual-component system combines a parametric Test-Time Training (TTT) memory to anchor the global coordinate frame and prevent scale drift, alongside a non-parametric Sliding Window Attention (SWA) mechanism to preserve uncompressed context for high-precision adjacent alignment. Remarkably, this memory architecture enables LoGeR to be trained on sequences of 128 frames, and generalize up to thousands of frames during inference. Evaluated across standard benchmarks and a newly repurposed VBR dataset with sequences of up to 19k frames, LoGeR substantially outperforms prior state-of-the-art feedforward methods--reducing ATE on KITTI by over 74%--and achieves robust, globally consistent reconstruction over unprecedented horizons.
VisGym: Diverse, Customizable, Scalable Environments for Multimodal Agents
Jan 23, 2026Modern Vision-Language Models (VLMs) remain poorly characterized in multi-step visual interactions, particularly in how they integrate perception, memory, and action over long horizons. We introduce VisGym, a gymnasium of 17 environments for evaluating and training VLMs. The suite spans symbolic puzzles, real-image understanding, navigation, and manipulation, and provides flexible controls over difficulty, input representation, planning horizon, and feedback. We also provide multi-step solvers that generate structured demonstrations, enabling supervised finetuning. Our evaluations show that all frontier models struggle in interactive settings, achieving low success rates in both the easy (46.6%) and hard (26.0%) configurations. Our experiments reveal notable limitations: models struggle to effectively leverage long context, performing worse with an unbounded history than with truncated windows. Furthermore, we find that several text-based symbolic tasks become substantially harder once rendered visually. However, explicit goal observations, textual feedback, and exploratory demonstrations in partially observable or unknown-dynamics settings for supervised finetuning yield consistent gains, highlighting concrete failure modes and pathways for improving multi-step visual decision-making. Code, data, and models can be found at: https://visgym.github.io/.
Spherical Geometry Diffusion: Generating High-quality 3D Face Geometry via Sphere-anchored Representations
Jan 19, 2026A fundamental challenge in text-to-3D face generation is achieving high-quality geometry. The core difficulty lies in the arbitrary and intricate distribution of vertices in 3D space, making it challenging for existing models to establish clean connectivity and resulting in suboptimal geometry. To address this, our core insight is to simplify the underlying geometric structure by constraining the distribution onto a simple and regular manifold, a topological sphere. Building on this, we first propose the Spherical Geometry Representation, a novel face representation that anchors geometric signals to uniform spherical coordinates. This guarantees a regular point distribution, from which the mesh connectivity can be robustly reconstructed. Critically, this canonical sphere can be seamlessly unwrapped into a 2D map, creating a perfect synergy with powerful 2D generative models. We then introduce Spherical Geometry Diffusion, a conditional diffusion framework built upon this 2D map. It enables diverse and controllable generation by jointly modeling geometry and texture, where the geometry explicitly conditions the texture synthesis process. Our method's effectiveness is demonstrated through its success in a wide range of tasks: text-to-3D generation, face reconstruction, and text-based 3D editing. Extensive experiments show that our approach substantially outperforms existing methods in geometric quality, textual fidelity, and inference efficiency.
Selfi: Self Improving Reconstruction Engine via 3D Geometric Feature Alignment
Dec 21, 2025Novel View Synthesis (NVS) has traditionally relied on models with explicit 3D inductive biases combined with known camera parameters from Structure-from-Motion (SfM) beforehand. Recent vision foundation models like VGGT take an orthogonal approach -- 3D knowledge is gained implicitly through training data and loss objectives, enabling feed-forward prediction of both camera parameters and 3D representations directly from a set of uncalibrated images. While flexible, VGGT features lack explicit multi-view geometric consistency, and we find that improving such 3D feature consistency benefits both NVS and pose estimation tasks. We introduce Selfi, a self-improving 3D reconstruction pipeline via feature alignment, transforming a VGGT backbone into a high-fidelity 3D reconstruction engine by leveraging its own outputs as pseudo-ground-truth. Specifically, we train a lightweight feature adapter using a reprojection-based consistency loss, which distills VGGT outputs into a new geometrically-aligned feature space that captures spatial proximity in 3D. This enables state-of-the-art performance in both NVS and camera pose estimation, demonstrating that feature alignment is a highly beneficial step for downstream 3D reasoning.
Breaking Android with AI: A Deep Dive into LLM-Powered Exploitation
Sep 09, 2025The rapid evolution of Artificial Intelligence (AI) and Large Language Models (LLMs) has opened up new opportunities in the area of cybersecurity, especially in the exploitation automation landscape and penetration testing. This study explores Android penetration testing automation using LLM-based tools, especially PentestGPT, to identify and execute rooting techniques. Through a comparison of the traditional manual rooting process and exploitation methods produced using AI, this study evaluates the efficacy, reliability, and scalability of automated penetration testing in achieving high-level privilege access on Android devices. With the use of an Android emulator (Genymotion) as the testbed, we fully execute both traditional and exploit-based rooting methods, automating the process using AI-generated scripts. Secondly, we create a web application by integrating OpenAI's API to facilitate automated script generation from LLM-processed responses. The research focuses on the effectiveness of AI-enabled exploitation by comparing automated and manual penetration testing protocols, by determining LLM weaknesses and strengths along the way. We also provide security suggestions of AI-enabled exploitation, including ethical factors and potential misuse. The findings exhibit that while LLMs can significantly streamline the workflow of exploitation, they need to be controlled by humans to ensure accuracy and ethical application. This study adds to the increasing body of literature on AI-powered cybersecurity and its effect on ethical hacking, security research, and mobile device security.
Visual Imitation Enables Contextual Humanoid Control
May 07, 2025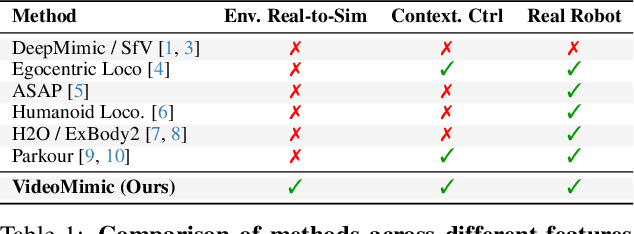
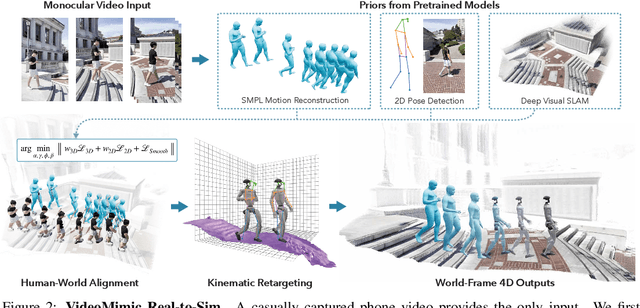


How can we teach humanoids to climb staircases and sit on chairs using the surrounding environment context? Arguably, the simplest way is to just show them-casually capture a human motion video and feed it to humanoids. We introduce VIDEOMIMIC, a real-to-sim-to-real pipeline that mines everyday videos, jointly reconstructs the humans and the environment, and produces whole-body control policies for humanoid robots that perform the corresponding skills. We demonstrate the results of our pipeline on real humanoid robots, showing robust, repeatable contextual control such as staircase ascents and descents, sitting and standing from chairs and benches, as well as other dynamic whole-body skills-all from a single policy, conditioned on the environment and global root commands. VIDEOMIMIC offers a scalable path towards teaching humanoids to operate in diverse real-world environments.
St4RTrack: Simultaneous 4D Reconstruction and Tracking in the World
Apr 17, 2025



Dynamic 3D reconstruction and point tracking in videos are typically treated as separate tasks, despite their deep connection. We propose St4RTrack, a feed-forward framework that simultaneously reconstructs and tracks dynamic video content in a world coordinate frame from RGB inputs. This is achieved by predicting two appropriately defined pointmaps for a pair of frames captured at different moments. Specifically, we predict both pointmaps at the same moment, in the same world, capturing both static and dynamic scene geometry while maintaining 3D correspondences. Chaining these predictions through the video sequence with respect to a reference frame naturally computes long-range correspondences, effectively combining 3D reconstruction with 3D tracking. Unlike prior methods that rely heavily on 4D ground truth supervision, we employ a novel adaptation scheme based on a reprojection loss. We establish a new extensive benchmark for world-frame reconstruction and tracking, demonstrating the effectiveness and efficiency of our unified, data-driven framework. Our code, model, and benchmark will be released.