 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Delta Learning
Jan 01, 2026The efficacy of deep residual networks is fundamentally predicated on the identity shortcut connection. While this mechanism effectively mitigates the vanishing gradient problem, it imposes a strictly additive inductive bias on feature transformations, thereby limiting the network's capacity to model complex state transitions. In this paper, we introduce Deep Delta Learning (DDL), a novel architecture that generalizes the standard residual connection by modulating the identity shortcut with a learnable, data-dependent geometric transformation. This transformation, termed the Delta Operator, constitutes a rank-1 perturbation of the identity matrix, parameterized by a reflection direction vector $\mathbf{k}(\mathbf{X})$ and a gating scalar $β(\mathbf{X})$. We provide a spectral analysis of this operator, demonstrating that the gate $β(\mathbf{X})$ enables dynamic interpolation between identity mapping, orthogonal projection, and geometric reflection. Furthermore, we restructure the residual update as a synchronous rank-1 injection, where the gate acts as a dynamic step size governing both the erasure of old information and the writing of new features. This unification empowers the network to explicitly control the spectrum of its layer-wise transition operator, enabling the modeling of complex, non-monotonic dynamics while preserving the stable training characteristics of gated residual architectures.
Physically-Grounded Manifold Projection with Foundation Priors for Metal Artifact Reduction in Dental CBCT
Dec 30, 2025Metal artifacts in Dental CBCT severely obscure anatomical structures, hindering diagnosis. Current deep learning for Metal Artifact Reduction (MAR) faces limitations: supervised methods suffer from spectral blurring due to "regression-to-the-mean", while unsupervised ones risk structural hallucinations. Denoising Diffusion Models (DDPMs) offer realism but rely on slow, stochastic iterative sampling, unsuitable for clinical use. To resolve this, we propose the Physically-Grounded Manifold Projection (PGMP) framework. First, our Anatomically-Adaptive Physics Simulation (AAPS) pipeline synthesizes high-fidelity training pairs via Monte Carlo spectral modeling and patient-specific digital twins, bridging the synthetic-to-real gap. Second, our DMP-Former adapts the Direct x-Prediction paradigm, reformulating restoration as a deterministic manifold projection to recover clean anatomy in a single forward pass, eliminating stochastic sampling. Finally, a Semantic-Structural Alignment (SSA) module anchors the solution using priors from medical foundation models (MedDINOv3), ensuring clinical plausibility. Experiments on synthetic and multi-center clinical datasets show PGMP outperforms state-of-the-art methods on unseen anatomy, setting new benchmarks in efficiency and diagnostic reliability. Code and data: https://github.com/ricoleehduu/PGMP
Web World Models
Dec 29, 2025Language agents increasingly require persistent worlds in which they can act, remember, and learn. Existing approaches sit at two extremes: conventional web frameworks provide reliable but fixed contexts backed by databases, while fully generative world models aim for unlimited environments at the expense of controllability and practical engineering. In this work, we introduce the Web World Model (WWM), a middle ground where world state and ``physics'' are implemented in ordinary web code to ensure logical consistency, while large language models generate context, narratives, and high-level decisions on top of this structured latent state. We build a suite of WWMs on a realistic web stack, including an infinite travel atlas grounded in real geography, fictional galaxy explorers, web-scale encyclopedic and narrative worlds, and simulation- and game-like environments. Across these systems, we identify practical design principles for WWMs: separating code-defined rules from model-driven imagination, representing latent state as typed web interfaces, and utilizing deterministic generation to achieve unlimited but structured exploration. Our results suggest that web stacks themselves can serve as a scalable substrate for world models, enabling controllable yet open-ended environments. Project Page: https://github.com/Princeton-AI2-Lab/Web-World-Models.
SPIRAL: Symbolic LLM Planning via Grounded and Reflective Search
Dec 29, 2025Large Language Models (LLMs) often falter at complex planning tasks that require exploration and self-correction, as their linear reasoning process struggles to recover from early mistakes. While search algorithms like Monte Carlo Tree Search (MCTS) can explore alternatives, they are often ineffective when guided by sparse rewards and fail to leverage the rich semantic capabilities of LLMs. We introduce SPIRAL (Symbolic LLM Planning via Grounded and Reflective Search), a novel framework that embeds a cognitive architecture of three specialized LLM agents into an MCTS loop. SPIRAL's key contribution is its integrated planning pipeline where a Planner proposes creative next steps, a Simulator grounds the search by predicting realistic outcomes, and a Critic provides dense reward signals through reflection. This synergy transforms MCTS from a brute-force search into a guided, self-correcting reasoning process. On the DailyLifeAPIs and HuggingFace datasets, SPIRAL consistently outperforms the default Chain-of-Thought planning method and other state-of-the-art agents. More importantly, it substantially surpasses other state-of-the-art agents; for example, SPIRAL achieves 83.6% overall accuracy on DailyLifeAPIs, an improvement of over 16 percentage points against the next-best search framework, while also demonstrating superior token efficiency. Our work demonstrates that structuring LLM reasoning as a guided, reflective, and grounded search process yields more robust and efficient autonomous planners. The source code, full appendices, and all experimental data are available for reproducibility at the official project repository.
Monadic Context Engineering
Dec 27, 2025The proliferation of Large Language Models (LLMs) has catalyzed a shift towards autonomous agents capable of complex reasoning and tool use. However, current agent architectures are frequently constructed using imperative, ad hoc patterns. This results in brittle systems plagued by difficulties in state management, error handling, and concurrency. This paper introduces Monadic Context Engineering (MCE), a novel architectural paradigm leveraging the algebraic structures of Functors, Applicative Functors, and Monads to provide a formal foundation for agent design. MCE treats agent workflows as computational contexts where cross-cutting concerns, such as state propagation, short-circuiting error handling, and asynchronous execution, are managed intrinsically by the algebraic properties of the abstraction. We demonstrate how Monads enable robust sequential composition, how Applicatives provide a principled structure for parallel execution, and crucially, how Monad Transformers allow for the systematic composition of these capabilities. This layered approach enables developers to construct complex, resilient, and efficient AI agents from simple, independently verifiable components. We further extend this framework to describe Meta-Agents, which leverage MCE for generative orchestration, dynamically creating and managing sub-agent workflows through metaprogramming. Project Page: https://github.com/yifanzhang-pro/monadic-context-engineering.
Borrowing from anything: A generalizable framework for reference-guided instance editing
Dec 17, 2025Reference-guided instance editing is fundamentally limited by semantic entanglement, where a reference's intrinsic appearance is intertwined with its extrinsic attributes. The key challenge lies in disentangling what information should be borrowed from the reference, and determining how to apply it appropriately to the target. To tackle this challenge, we propose GENIE, a Generalizable Instance Editing framework capable of achieving explicit disentanglement. GENIE first corrects spatial misalignments with a Spatial Alignment Module (SAM). Then, an Adaptive Residual Scaling Module (ARSM) learns what to borrow by amplifying salient intrinsic cues while suppressing extrinsic attributes, while a Progressive Attention Fusion (PAF) mechanism learns how to render this appearance onto the target, preserving its structure. Extensive experiments on the challenging AnyInsertion dataset demonstrate that GENIE achieves state-of-the-art fidelity and robustness, setting a new standard for disentanglement-based instance editing.
FutureX: Enhance End-to-End Autonomous Driving via Latent Chain-of-Thought World Model
Dec 12, 2025



In autonomous driving, end-to-end planners learn scene representations from raw sensor data and utilize them to generate a motion plan or control actions. However, exclusive reliance on the current scene for motion planning may result in suboptimal responses in highly dynamic traffic environments where ego actions further alter the future scene. To model the evolution of future scenes, we leverage the World Model to represent how the ego vehicle and its environment interact and change over time, which entails complex reasoning. The Chain of Thought (CoT) offers a promising solution by forecasting a sequence of future thoughts that subsequently guide trajectory refinement. In this paper, we propose FutureX, a CoT-driven pipeline that enhances end-to-end planners to perform complex motion planning via future scene latent reasoning and trajectory refinement. Specifically, the Auto-think Switch examines the current scene and decides whether additional reasoning is required to yield a higher-quality motion plan. Once FutureX enters the Thinking mode, the Latent World Model conducts a CoT-guided rollout to predict future scene representation, enabling the Summarizer Module to further refine the motion plan. Otherwise, FutureX operates in an Instant mode to generate motion plans in a forward pass for relatively simple scenes. Extensive experiments demonstrate that FutureX enhances existing methods by producing more rational motion plans and fewer collisions without compromising efficiency, thereby achieving substantial overall performance gains, e.g., 6.2 PDMS improvement for TransFuser on NAVSIM. Code will be released.
Video-QTR: Query-Driven Temporal Reasoning Framework for Lightweight Video Understanding
Dec 10, 2025The rapid development of multimodal large-language models (MLLMs) has significantly expanded the scope of visual language reasoning, enabling unified systems to interpret and describe complex visual content. However, applying these models to long-video understanding remains computationally intensive. Dense frame encoding generates excessive visual tokens, leading to high memory consumption, redundant computation, and limited scalability in real-world applications. This inefficiency highlights a key limitation of the traditional process-then-reason paradigm, which analyzes visual streams exhaustively before semantic reasoning. To address this challenge, we introduce Video-QTR (Query-Driven Temporal Reasoning), a lightweight framework that redefines video comprehension as a query-guided reasoning process. Instead of encoding every frame, Video-QTR dynamically allocates perceptual resources based on the semantic intent of the query, creating an adaptive feedback loop between reasoning and perception. Extensive experiments across five benchmarks: MSVD-QA, Activity Net-QA, Movie Chat, and Video MME demonstrate that Video-QTR achieves state-of-the-art performance while reducing input frame consumption by up to 73%. These results confirm that query-driven temporal reasoning provides an efficient and scalable solution for video understanding.
Group Representational Position Encoding
Dec 08, 2025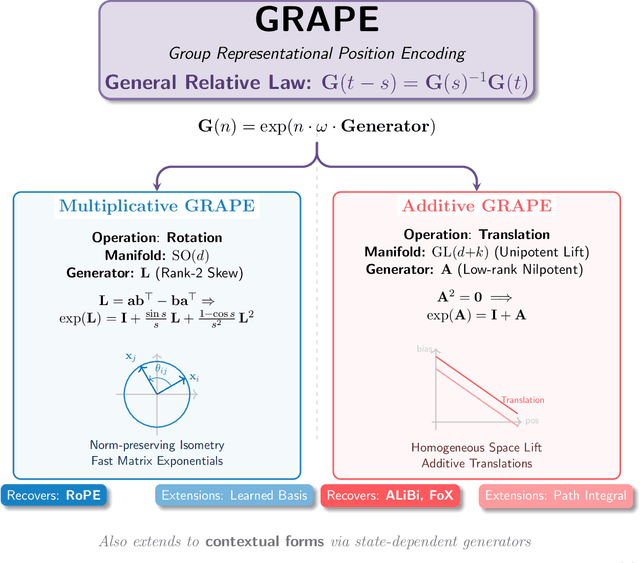
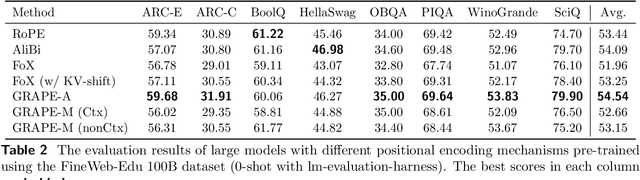
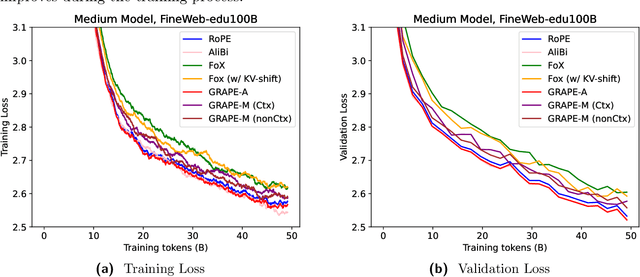

We present GRAPE (Group RepresentAtional Position Encoding), a unified framework for positional encoding based on group actions. GRAPE brings together two families of mechanisms: (i) multiplicative rotations (Multiplicative GRAPE) in $\mathrm{SO}(d)$ and (ii) additive logit biases (Additive GRAPE) arising from unipotent actions in the general linear group $\mathrm{GL}$. In Multiplicative GRAPE, a position $n \in \mathbb{Z}$ (or $t \in \mathbb{R}$) acts as $\mathbf{G}(n)=\exp(n\,ω\,\mathbf{L})$ with a rank-2 skew generator $\mathbf{L} \in \mathbb{R}^{d \times d}$, yielding a relative, compositional, norm-preserving map with a closed-form matrix exponential. RoPE is recovered exactly when the $d/2$ planes are the canonical coordinate pairs with log-uniform spectrum. Learned commuting subspaces and compact non-commuting mixtures strictly extend this geometry to capture cross-subspace feature coupling at $O(d)$ and $O(r d)$ cost per head, respectively. In Additive GRAPE, additive logits arise as rank-1 (or low-rank) unipotent actions, recovering ALiBi and the Forgetting Transformer (FoX) as exact special cases while preserving an exact relative law and streaming cacheability. Altogether, GRAPE supplies a principled design space for positional geometry in long-context models, subsuming RoPE and ALiBi as special cases. Project Page: https://github.com/model-architectures/GRAPE.
MiroThinker: Pushing the Performance Boundaries of Open-Source Research Agents via Model, Context, and Interactive Scaling
Nov 18, 2025We present MiroThinker v1.0, an open-source research agent designed to advance tool-augmented reasoning and information-seeking capabilities. Unlike previous agents that only scale up model size or context length, MiroThinker explores interaction scaling at the model level, systematically training the model to handle deeper and more frequent agent-environment interactions as a third dimension of performance improvement. Unlike LLM test-time scaling, which operates in isolation and risks degradation with longer reasoning chains, interactive scaling leverages environment feedback and external information acquisition to correct errors and refine trajectories. Through reinforcement learning, the model achieves efficient interaction scaling: with a 256K context window, it can perform up to 600 tool calls per task, enabling sustained multi-turn reasoning and complex real-world research workflows. Across four representative benchmarks-GAIA, HLE, BrowseComp, and BrowseComp-ZH-the 72B variant achieves up to 81.9%, 37.7%, 47.1%, and 55.6% accuracy respectively, surpassing previous open-source agents and approaching commercial counterparts such as GPT-5-high. Our analysis reveals that MiroThinker benefits from interactive scaling consistently: research performance improves predictably as the model engages in deeper and more frequent agent-environment interactions, demonstrating that interaction depth exhibits scaling behaviors analogous to model size and context length. These findings establish interaction scaling as a third critical dimension for building next-generation open research agents, complementing model capacity and context windows.