 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Equivalent Contrastive Learning for Radio Signal Recognition
Apr 13, 2026Robust radio signal recognition is fundamental to spectrum management, electromagnetic space security, and intelligent wireless applications, yet existing deep-learning methods rely heavily on large labeled datasets and struggle to capture the multi-domain characteristics inherent in real-world signals. To address these limitations, we propose an unsupervised equivalent contrastive learning method that leverages four information-lossless equivalent transformations, spanning the time, instantaneous, frequency, and time-frequency domains, to construct multi-view and semantically consistent representations of each signal. An equivalent contrastive learning strategy then aligns these complementary views to learn discriminative and transferable embeddings without requiring labeled data. Once pre-training is completed, the resulting model can be directly fine-tuned on downstream tasks using only raw signal samples, without reapplying any equivalent transformations, which reduces computational overhead and simplifies deployment. Extensive experiments on four public datasets demonstrate that the proposed method consistently outperforms state-of-the-art contrastive baselines under linear evaluation, few-shot semi-supervised learning, and cross-domain transfer settings. Notably, the learned representations yield substantial gains in few-shot regimes and challenging channel conditions, confirming the effectiveness of multi-domain equivalent modeling in enhancing robustness and generalization. This work establishes a principled pathway for exploiting massive unlabeled radio data and provides a foundation for future self-supervised learning frameworks in wireless systems.
DS-Pnet: FM-Based Positioning via Downsampling
Apr 10, 2025



In this paper we present DS-Pnet, a novel framework for FM signal-based positioning that addresses the challenges of high computational complexity and limited deployment in resource-constrained environments. Two downsampling methods-IQ signal downsampling and time-frequency representation downsampling-are proposed to reduce data dimensionality while preserving critical positioning features. By integrating with the lightweight MobileViT-XS neural network, the framework achieves high positioning accuracy with significantly reduced computational demands. Experiments on real-world FM signal datasets demonstrate that DS-Pnet achieves superior performance in both indoor and outdoor scenarios, with space and time complexity reductions of approximately 87% and 99.5%, respectively, compared to an existing method, FM-Pnet. Despite the high compression, DS-Pnet maintains robust positioning accuracy, offering an optimal balance between efficiency and precision.
WK-Pnet: FM-Based Positioning via Wavelet Packet Decomposition and Knowledge Distillation
Apr 10, 2025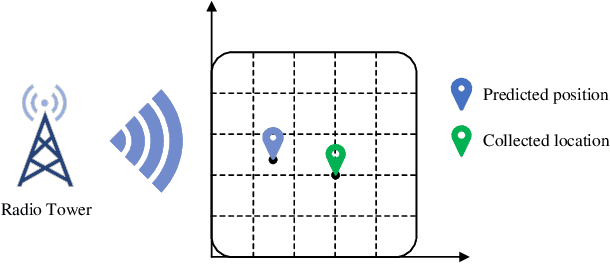
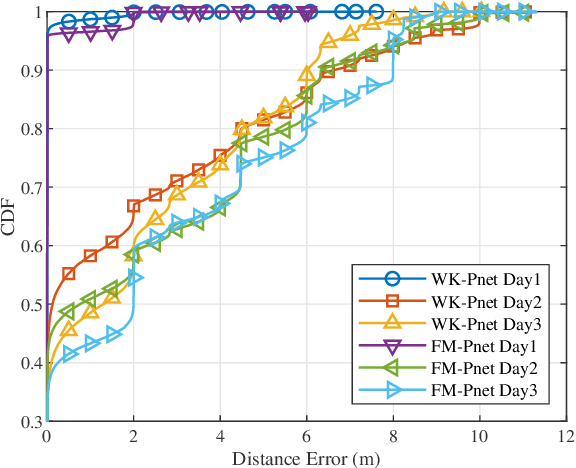
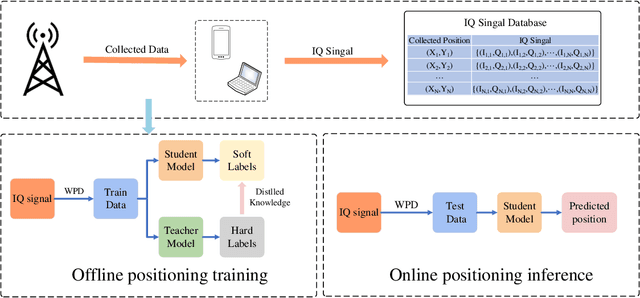
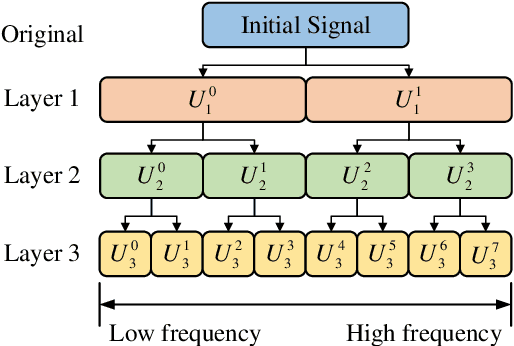
Accurate and efficient positioning in complex environments is critical for applications where traditional satellite-based systems face limitations, such as indoors or urban canyons. This paper introduces WK-Pnet, an FM-based indoor positioning framework that combines wavelet packet decomposition (WPD) and knowledge distillation. WK-Pnet leverages WPD to extract rich time-frequency features from FM signals, which are then processed by a deep learning model for precise position estimation. To address computational demands, we employ knowledge distillation, transferring insights from a high-capacity model to a streamlined student model, achieving substantial reductions in complexity without sacrificing accuracy. Experimental results across diverse environments validate WK-Pnet's superior positioning accuracy and lower computational requirements, making it a viable solution for positioning in real-time resource-constraint applications.
Reassessing Layer Pruning in LLMs: New Insights and Methods
Nov 23, 2024



Although large language models (LLMs) have achieved remarkable success across various domains, their considerable scale necessitates substantial computational resources, posing significant challenges for deployment in resource-constrained environments. Layer pruning, as a simple yet effective compression method, removes layers of a model directly, reducing computational overhead. However, what are the best practices for layer pruning in LLMs? Are sophisticated layer selection metrics truly effective? Does the LoRA (Low-Rank Approximation) family, widely regarded as a leading method for pruned model fine-tuning, truly meet expectations when applied to post-pruning fine-tuning? To answer these questions, we dedicate thousands of GPU hours to benchmarking layer pruning in LLMs and gaining insights across multiple dimensions. Our results demonstrate that a simple approach, i.e., pruning the final 25\% of layers followed by fine-tuning the \texttt{lm\_head} and the remaining last three layer, yields remarkably strong performance. Following this guide, we prune Llama-3.1-8B-It and obtain a model that outperforms many popular LLMs of similar size, such as ChatGLM2-6B, Vicuna-7B-v1.5, Qwen1.5-7B and Baichuan2-7B. We release the optimal model weights on Huggingface, and the code is available on GitHub.
Lateral Movement Detection via Time-aware Subgraph Classification on Authentication Logs
Nov 15, 2024Lateral movement is a crucial component of advanced persistent threat (APT) attacks in networks. Attackers exploit security vulnerabilities in internal networks or IoT devices, expanding their control after initial infiltration to steal sensitive data or carry out other malicious activities, posing a serious threat to system security. Existing research suggests that attackers generally employ seemingly unrelated operations to mask their malicious intentions, thereby evading existing lateral movement detection methods and hiding their intrusion traces. In this regard, we analyze host authentication log data from a graph perspective and propose a multi-scale lateral movement detection framework called LMDetect. The main workflow of this framework proceeds as follows: 1) Construct a heterogeneous multigraph from host authentication log data to strengthen the correlations among internal system entities; 2) Design a time-aware subgraph generator to extract subgraphs centered on authentication events from the heterogeneous authentication multigraph; 3) Design a multi-scale attention encoder that leverages both local and global attention to capture hidden anomalous behavior patterns in the authentication subgraphs, thereby achieving lateral movement detection. Extensive experiments on two real-world authentication log datasets demonstrate the effectiveness and superiority of our framework in detecting lateral movement behaviors.
RedTest: Towards Measuring Redundancy in Deep Neural Networks Effectively
Nov 15, 2024



Deep learning has revolutionized computing in many real-world applications, arguably due to its remarkable performance and extreme convenience as an end-to-end solution. However, deep learning models can be costly to train and to use, especially for those large-scale models, making it necessary to optimize the original overly complicated models into smaller ones in scenarios with limited resources such as mobile applications or simply for resource saving. The key question in such model optimization is, how can we effectively identify and measure the redundancy in a deep learning model structure. While several common metrics exist in the popular model optimization techniques to measure the performance of models after optimization, they are not able to quantitatively inform the degree of remaining redundancy. To address the problem, we present a novel testing approach, i.e., RedTest, which proposes a novel testing metric called Model Structural Redundancy Score (MSRS) to quantitatively measure the degree of redundancy in a deep learning model structure. We first show that MSRS is effective in both revealing and assessing the redundancy issues in many state-of-the-art models, which urgently calls for model optimization. Then, we utilize MSRS to assist deep learning model developers in two practical application scenarios: 1) in Neural Architecture Search, we design a novel redundancy-aware algorithm to guide the search for the optimal model structure and demonstrate its effectiveness by comparing it to existing standard NAS practice; 2) in the pruning of large-scale pre-trained models, we prune the redundant layers of pre-trained models with the guidance of layer similarity to derive less redundant ones of much smaller size. Extensive experimental results demonstrate that removing such redundancy has a negligible effect on the model utility.
Rethinking Graph Transformer Architecture Design for Node Classification
Oct 15, 2024



Graph Transformer (GT), as a special type of Graph Neural Networks (GNNs), utilizes multi-head attention to facilitate high-order message passing. However, this also imposes several limitations in node classification applications: 1) nodes are susceptible to global noise; 2) self-attention computation cannot scale well to large graphs. In this work, we conduct extensive observational experiments to explore the adaptability of the GT architecture in node classification tasks and draw several conclusions: the current multi-head self-attention module in GT can be completely replaceable, while the feed-forward neural network module proves to be valuable. Based on this, we decouple the propagation (P) and transformation (T) of GNNs and explore a powerful GT architecture, named GNNFormer, which is based on the P/T combination message passing and adapted for node classification in both homophilous and heterophilous scenarios. Extensive experiments on 12 benchmark datasets demonstrate that our proposed GT architecture can effectively adapt to node classification tasks without being affected by global noise and computational efficiency limitations.
MDM: Advancing Multi-Domain Distribution Matching for Automatic Modulation Recognition Dataset Synthesis
Aug 05, 2024Recently, deep learning technology has been successfully introduced into Automatic Modulation Recognition (AMR) tasks. However, the success of deep learning is all attributed to the training on large-scale datasets. Such a large amount of data brings huge pressure on storage, transmission and model training. In order to solve the problem of large amount of data, some researchers put forward the method of data distillation, which aims to compress large training data into smaller synthetic datasets to maintain its performance. While numerous data distillation techniques have been developed within the realm of image processing, the unique characteristics of signals set them apart. Signals exhibit distinct features across various domains, necessitating specialized approaches for their analysis and processing. To this end, a novel dataset distillation method--Multi-domain Distribution Matching (MDM) is proposed. MDM employs the Discrete Fourier Transform (DFT) to translate timedomain signals into the frequency domain, and then uses a model to compute distribution matching losses between the synthetic and real datasets, considering both the time and frequency domains. Ultimately, these two losses are integrated to update the synthetic dataset. We conduct extensive experiments on three AMR datasets. Experimental results show that, compared with baseline methods, our method achieves better performance under the same compression ratio. Furthermore, we conduct crossarchitecture generalization experiments on several models, and the experimental results show that our synthetic datasets can generalize well on other unseen models.
Enhancing Ethereum Fraud Detection via Generative and Contrastive Self-supervision
Aug 01, 2024



The rampant fraudulent activities on Ethereum hinder the healthy development of the blockchain ecosystem, necessitating the reinforcement of regulations. However, multiple imbalances involving account interaction frequencies and interaction types in the Ethereum transaction environment pose significant challenges to data mining-based fraud detection research. To address this, we first propose the concept of meta-interactions to refine interaction behaviors in Ethereum, and based on this, we present a dual self-supervision enhanced Ethereum fraud detection framework, named Meta-IFD. This framework initially introduces a generative self-supervision mechanism to augment the interaction features of accounts, followed by a contrastive self-supervision mechanism to differentiate various behavior patterns, and ultimately characterizes the behavioral representations of accounts and mines potential fraud risks through multi-view interaction feature learning. Extensive experiments on real Ethereum datasets demonstrate the effectiveness and superiority of our framework in detecting common Ethereum fraud behaviors such as Ponzi schemes and phishing scams. Additionally, the generative module can effectively alleviate the interaction distribution imbalance in Ethereum data, while the contrastive module significantly enhances the framework's ability to distinguish different behavior patterns. The source code will be released on GitHub soon.
A Generic Layer Pruning Method for Signal Modulation Recognition Deep Learning Models
Jun 12, 2024



With the successful application of deep learning in communications systems, deep neural networks are becoming the preferred method for signal classification. Although these models yield impressive results, they often come with high computational complexity and large model sizes, which hinders their practical deployment in communication systems. To address this challenge, we propose a novel layer pruning method. Specifically, we decompose the model into several consecutive blocks, each containing consecutive layers with similar semantics. Then, we identify layers that need to be preserved within each block based on their contribution. Finally, we reassemble the pruned blocks and fine-tune the compact model. Extensive experiments on five datasets demonstrate the efficiency and effectiveness of our method over a variety of state-of-the-art baselines, including layer pruning and channel pruning methods.