 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMG2Skill: Can Agents Distill In-the-Wild Guides into Self-Evolving Skills?
Jun 01, 2026Abundant procedural knowledge on the Web holds great potential for helping agents solve long-horizon tasks. However, such knowledge is often multimodal, heterogeneous, noisy, and implicitly assumes human executors, making it difficult to use directly as the skills required by agents. To bridge the gap between human-oriented guides and agent-executable skills, we formalize this problem as guide-to-skill learning: converting in-the-wild guides into executable skills and continuously improving them from trajectories observable to the agent. To evaluate the capability of existing agents on this task, we introduce MMG2Skill-Bench, the first benchmark designed for this problem. We further propose MMG2Skill, a closed-loop framework that compiles guides into editable skills, conditions a fixed vision-language model (VLM) agent on these skills during execution, and revises the skills from trajectory-level root-cause feedback without using benchmark scores. Across GUI control, open-ended gameplay, and strategic card play with six VLM backbones, MMG2Skill consistently outperforms vanilla baseline agents in every model-domain setting, achieving macro-average gains of +12.8 to +25.3 percentage points across backbones. Ablation studies show that directly prompting agents with raw guides can degrade performance, while both structured skill construction and trajectory-driven revision are necessary for the observed improvements. On success-inferable tasks, analyzer-based early stopping further prevents late-stage performance regressions and saves 25%-53% of attempts when the success signal is properly calibrated.
WebCompass: Towards Multimodal Web Coding Evaluation for Code Language Models
Apr 20, 2026Large language models are rapidly evolving into interactive coding agents capable of end-to-end web coding, yet existing benchmarks evaluate only narrow slices of this capability, typically text-conditioned generation with static-correctness metrics, leaving visual fidelity, interaction quality, and codebase-level reasoning largely unmeasured. We introduce WebCompass, a multimodal benchmark that provides unified lifecycle evaluation of web engineering capability. Recognizing that real-world web coding is an iterative cycle of generation, editing, and repair, WebCompass spans three input modalities (text, image, video) and three task types (generation, editing, repair), yielding seven task categories that mirror professional workflows. Through a multi-stage, human-in-the-loop pipeline, we curate instances covering 15 generation domains, 16 editing operation types, and 11 repair defect types, each annotated at Easy/Medium/Hard levels. For evaluation, we adopt a checklist-guided LLM-as-a-Judge protocol for editing and repair, and propose a novel Agent-as-a-Judge paradigm for generation that autonomously executes generated websites in a real browser, explores interactive behaviors via the Model Context Protocol (MCP), and iteratively synthesizes targeted test cases, closely approximating human acceptance testing. We evaluate representative closed-source and open-source models and observe that: (1) closed-source models remain substantially stronger and more balanced; (2) editing and repair exhibit distinct difficulty profiles, with repair preserving interactivity better but remaining execution-challenging; (3) aesthetics is the most persistent bottleneck, especially for open-source models; and (4) framework choice materially affects outcomes, with Vue consistently challenging while React and Vanilla/HTML perform more strongly depending on task type.
CodeTracer: Towards Traceable Agent States
Apr 14, 2026Code agents are advancing rapidly, but debugging them is becoming increasingly difficult. As frameworks orchestrate parallel tool calls and multi-stage workflows over complex tasks, making the agent's state transitions and error propagation hard to observe. In these runs, an early misstep can trap the agent in unproductive loops or even cascade into fundamental errors, forming hidden error chains that make it hard to tell when the agent goes off track and why. Existing agent tracing analyses either focus on simple interaction or rely on small-scale manual inspection, which limits their scalability and usefulness for real coding workflows. We present CodeTracer, a tracing architecture that parses heterogeneous run artifacts through evolving extractors, reconstructs the full state transition history as a hierarchical trace tree with persistent memory, and performs failure onset localization to pinpoint the failure origin and its downstream chain. To enable systematic evaluation, we construct CodeTraceBench from a large collection of executed trajectories generated by four widely used code agent frameworks on diverse code tasks (e.g., bug fixing, refactoring, and terminal interaction), with supervision at both the stage and step levels for failure localization. Experiments show that CodeTracer substantially outperforms direct prompting and lightweight baselines, and that replaying its diagnostic signals consistently recovers originally failed runs under matched budgets. Our code and data are publicly available.
Vibe AIGC: A New Paradigm for Content Generation via Agentic Orchestration
Feb 05, 2026For the past decade, the trajectory of generative artificial intelligence (AI) has been dominated by a model-centric paradigm driven by scaling laws. Despite significant leaps in visual fidelity, this approach has encountered a ``usability ceiling'' manifested as the Intent-Execution Gap (i.e., the fundamental disparity between a creator's high-level intent and the stochastic, black-box nature of current single-shot models). In this paper, inspired by the Vibe Coding, we introduce the \textbf{Vibe AIGC}, a new paradigm for content generation via agentic orchestration, which represents the autonomous synthesis of hierarchical multi-agent workflows. Under this paradigm, the user's role transcends traditional prompt engineering, evolving into a Commander who provides a Vibe, a high-level representation encompassing aesthetic preferences, functional logic, and etc. A centralized Meta-Planner then functions as a system architect, deconstructing this ``Vibe'' into executable, verifiable, and adaptive agentic pipelines. By transitioning from stochastic inference to logical orchestration, Vibe AIGC bridges the gap between human imagination and machine execution. We contend that this shift will redefine the human-AI collaborative economy, transforming AI from a fragile inference engine into a robust system-level engineering partner that democratizes the creation of complex, long-horizon digital assets.
AutoMV: An Automatic Multi-Agent System for Music Video Generation
Dec 13, 2025Music-to-Video (M2V) generation for full-length songs faces significant challenges. Existing methods produce short, disjointed clips, failing to align visuals with musical structure, beats, or lyrics, and lack temporal consistency. We propose AutoMV, a multi-agent system that generates full music videos (MVs) directly from a song. AutoMV first applies music processing tools to extract musical attributes, such as structure, vocal tracks, and time-aligned lyrics, and constructs these features as contextual inputs for following agents. The screenwriter Agent and director Agent then use this information to design short script, define character profiles in a shared external bank, and specify camera instructions. Subsequently, these agents call the image generator for keyframes and different video generators for "story" or "singer" scenes. A Verifier Agent evaluates their output, enabling multi-agent collaboration to produce a coherent longform MV. To evaluate M2V generation, we further propose a benchmark with four high-level categories (Music Content, Technical, Post-production, Art) and twelve ine-grained criteria. This benchmark was applied to compare commercial products, AutoMV, and human-directed MVs with expert human raters: AutoMV outperforms current baselines significantly across all four categories, narrowing the gap to professional MVs. Finally, we investigate using large multimodal models as automatic MV judges; while promising, they still lag behind human expert, highlighting room for future work.
SWE-Compass: Towards Unified Evaluation of Agentic Coding Abilities for Large Language Models
Nov 07, 2025Evaluating large language models (LLMs) for software engineering has been limited by narrow task coverage, language bias, and insufficient alignment with real-world developer workflows. Existing benchmarks often focus on algorithmic problems or Python-centric bug fixing, leaving critical dimensions of software engineering underexplored. To address these gaps, we introduce SWE-Compass1, a comprehensive benchmark that unifies heterogeneous code-related evaluations into a structured and production-aligned framework. SWE-Compass spans 8 task types, 8 programming scenarios, and 10 programming languages, with 2000 high-quality instances curated from authentic GitHub pull requests and refined through systematic filtering and validation. We benchmark ten state-of-the-art LLMs under two agentic frameworks, SWE-Agent and Claude Code, revealing a clear hierarchy of difficulty across task types, languages, and scenarios. Moreover, by aligning evaluation with real-world developer practices, SWE-Compass provides a rigorous and reproducible foundation for diagnosing and advancing agentic coding capabilities in large language models.
MotivGraph-SoIQ: Integrating Motivational Knowledge Graphs and Socratic Dialogue for Enhanced LLM Ideation
Sep 26, 2025
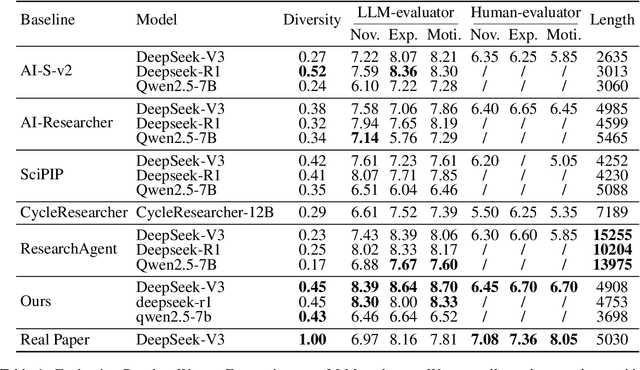
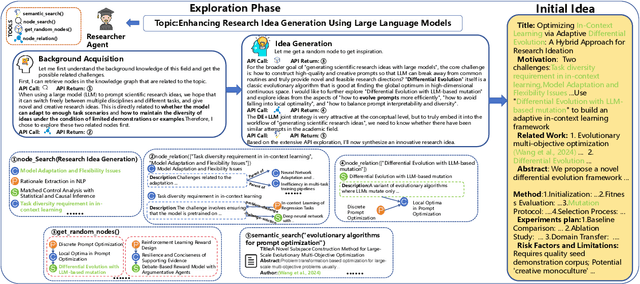
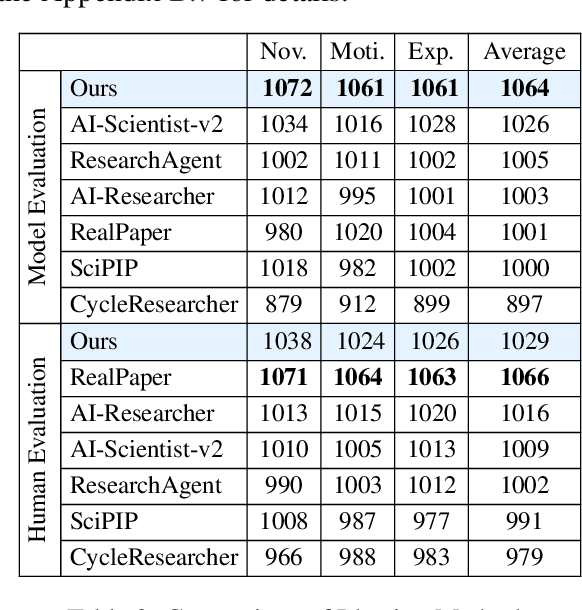
Large Language Models (LLMs) hold substantial potential for accelerating academic ideation but face critical challenges in grounding ideas and mitigating confirmation bias for further refinement. We propose integrating motivational knowledge graphs and socratic dialogue to address these limitations in enhanced LLM ideation (MotivGraph-SoIQ). This novel framework provides essential grounding and practical idea improvement steps for LLM ideation by integrating a Motivational Knowledge Graph (MotivGraph) with a Q-Driven Socratic Ideator. The MotivGraph structurally stores three key node types(problem, challenge and solution) to offer motivation grounding for the LLM ideation process. The Ideator is a dual-agent system utilizing Socratic questioning, which facilitates a rigorous refinement process that mitigates confirmation bias and improves idea quality across novelty, experimental rigor, and motivational rationality dimensions. On the ICLR25 paper topics dataset, MotivGraph-SoIQ exhibits clear advantages over existing state-of-the-art approaches across LLM-based scoring, ELO ranking, and human evaluation metrics.
Inverse IFEval: Can LLMs Unlearn Stubborn Training Conventions to Follow Real Instructions?
Sep 04, 2025Large Language Models (LLMs) achieve strong performance on diverse tasks but often exhibit cognitive inertia, struggling to follow instructions that conflict with the standardized patterns learned during supervised fine-tuning (SFT). To evaluate this limitation, we propose Inverse IFEval, a benchmark that measures models Counter-intuitive Abilitytheir capacity to override training-induced biases and comply with adversarial instructions. Inverse IFEval introduces eight types of such challenges, including Question Correction, Intentional Textual Flaws, Code without Comments, and Counterfactual Answering. Using a human-in-the-loop pipeline, we construct a dataset of 1012 high-quality Chinese and English questions across 23 domains, evaluated under an optimized LLM-as-a-Judge framework. Experiments on existing leading LLMs demonstrate the necessity of our proposed Inverse IFEval benchmark. Our findings emphasize that future alignment efforts should not only pursue fluency and factual correctness but also account for adaptability under unconventional contexts. We hope that Inverse IFEval serves as both a diagnostic tool and a foundation for developing methods that mitigate cognitive inertia, reduce overfitting to narrow patterns, and ultimately enhance the instruction-following reliability of LLMs in diverse and unpredictable real-world scenarios.