 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the use of AI authors and reviewers at Agents4Science
Nov 19, 2025There is growing interest in using AI agents for scientific research, yet fundamental questions remain about their capabilities as scientists and reviewers. To explore these questions, we organized Agents4Science, the first conference in which AI agents serve as both primary authors and reviewers, with humans as co-authors and co-reviewers. Here, we discuss the key learnings from the conference and their implications for human-AI collaboration in science.
Target word activity detector: An approach to obtain ASR word boundaries without lexicon
Sep 20, 2024Obtaining word timestamp information from end-to-end (E2E) ASR models remains challenging due to the lack of explicit time alignment during training. This issue is further complicated in multilingual models. Existing methods, either rely on lexicons or introduce additional tokens, leading to scalability issues and increased computational costs. In this work, we propose a new approach to estimate word boundaries without relying on lexicons. Our method leverages word embeddings from sub-word token units and a pretrained ASR model, requiring only word alignment information during training. Our proposed method can scale-up to any number of languages without incurring any additional cost. We validate our approach using a multilingual ASR model trained on five languages and demonstrate its effectiveness against a strong baseline.
A Survey on Large Language Model Security and Privacy: The Good, the Bad, and the Ugly
Dec 04, 2023



Large Language Models (LLMs), such as GPT-3 and BERT, have revolutionized natural language understanding and generation. They possess deep language comprehension, human-like text generation capabilities, contextual awareness, and robust problem-solving skills, making them invaluable in various domains (e.g., search engines, customer support, translation). In the meantime, LLMs have also gained traction in the security community, revealing security vulnerabilities and showcasing their potential in security-related tasks. This paper explores the intersection of LLMs with security and privacy. Specifically, we investigate how LLMs positively impact security and privacy, potential risks and threats associated with their use, and inherent vulnerabilities within LLMs. Through a comprehensive literature review, the paper categorizes findings into "The Good" (beneficial LLM applications), "The Bad" (offensive applications), and "The Ugly" (vulnerabilities and their defenses). We have some interesting findings. For example, LLMs have proven to enhance code and data security, outperforming traditional methods. However, they can also be harnessed for various attacks (particularly user-level attacks) due to their human-like reasoning abilities. We have identified areas that require further research efforts. For example, research on model and parameter extraction attacks is limited and often theoretical, hindered by LLM parameter scale and confidentiality. Safe instruction tuning, a recent development, requires more exploration. We hope that our work can shed light on the LLMs' potential to both bolster and jeopardize cybersecurity.
Pre-training End-to-end ASR Models with Augmented Speech Samples Queried by Text
Jul 30, 2023



In end-to-end automatic speech recognition system, one of the difficulties for language expansion is the limited paired speech and text training data. In this paper, we propose a novel method to generate augmented samples with unpaired speech feature segments and text data for model pre-training, which has the advantage of low cost without using additional speech data. When mixing 20,000 hours augmented speech data generated by our method with 12,500 hours original transcribed speech data for Italian Transformer transducer model pre-training, we achieve 8.7% relative word error rate reduction. The pre-trained model achieves similar performance as the model pre-trained with multilingual transcribed 75,000 hours raw speech data. When merging the augmented speech data with the multilingual data to pre-train a new model, we achieve even more relative word error rate reduction of 12.2% over the baseline, which further verifies the effectiveness of our method for speech data augmentation.
Building High-accuracy Multilingual ASR with Gated Language Experts and Curriculum Training
Mar 01, 2023



We propose gated language experts to improve multilingual transformer transducer models without any language identification (LID) input from users during inference. We define gating mechanism and LID loss to let transformer encoders learn language-dependent information, construct the multilingual transformer block with gated transformer experts and shared transformer layers for compact models, and apply linear experts on joint network output to better regularize speech acoustic and token label joint information. Furthermore, a curriculum training scheme is proposed to let LID guide the gated language experts for better serving their corresponding languages. Evaluated on the English and Spanish bilingual task, our methods achieve average 12.5% and 7.3% relative word error reductions over the baseline bilingual model and monolingual models, respectively, obtaining similar results to the upper bound model trained and inferred with oracle LID. We further explore our method on trilingual, quadrilingual, and pentalingual models, and observe similar advantages as in the bilingual models, which demonstrates the easy extension to more languages.
LAMASSU: Streaming Language-Agnostic Multilingual Speech Recognition and Translation Using Neural Transducers
Nov 05, 2022



End-to-end formulation of automatic speech recognition (ASR) and speech translation (ST) makes it easy to use a single model for both multilingual ASR and many-to-many ST. In this paper, we propose streaming language-agnostic multilingual speech recognition and translation using neural transducers (LAMASSU). To enable multilingual text generation in LAMASSU, we conduct a systematic comparison between specified and unified prediction and joint networks. We leverage a language-agnostic multilingual encoder that substantially outperforms shared encoders. To enhance LAMASSU, we propose to feed target LID to encoders. We also apply connectionist temporal classification regularization to transducer training. Experimental results show that LAMASSU not only drastically reduces the model size but also outperforms monolingual ASR and bilingual ST models.
A Weakly-Supervised Streaming Multilingual Speech Model with Truly Zero-Shot Capability
Nov 04, 2022



In this paper, we introduce our work of building a Streaming Multilingual Speech Model (SM2), which can transcribe or translate multiple spoken languages into texts of the target language. The backbone of SM2 is Transformer Transducer, which has high streaming capability. Instead of human labeled speech translation (ST) data, SM2 models are trained using weakly supervised data generated by converting the transcriptions in speech recognition corpora with a machine translation service. With 351 thousand hours of anonymized speech training data from 25 languages, SM2 models achieve comparable or even better ST quality than some recent popular large-scale non-streaming speech models. More importantly, we show that SM2 has the truly zero-shot capability when expanding to new target languages, yielding high quality ST results for {source-speech, target-text} pairs that are not seen during training.
Building a great multi-lingual teacher with sparsely-gated mixture of experts for speech recognition
Jan 04, 2022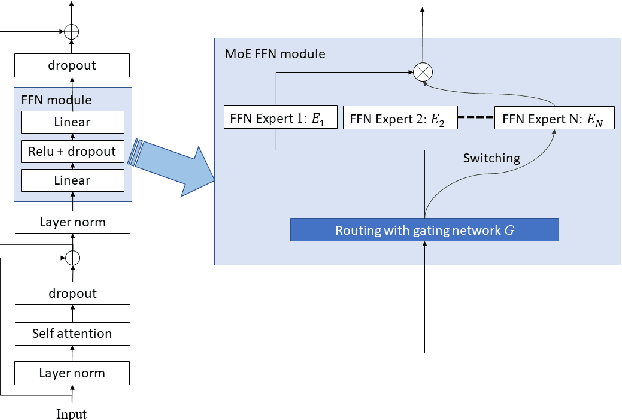
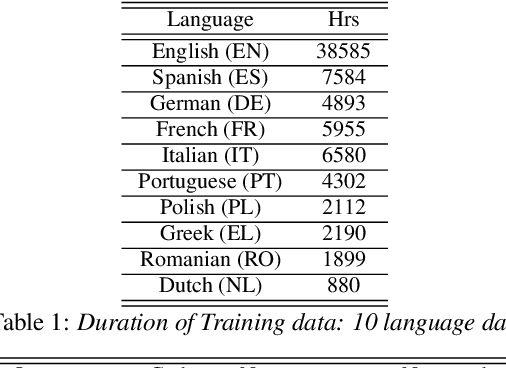
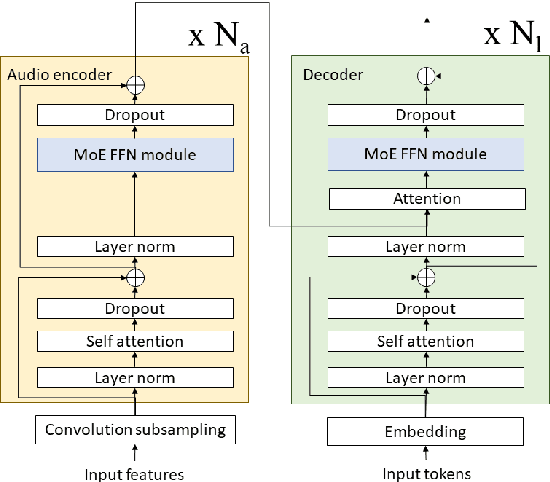
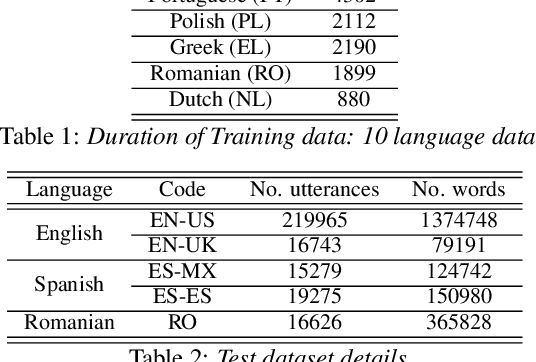
The sparsely-gated Mixture of Experts (MoE) can magnify a network capacity with a little computational complexity. In this work, we investigate how multi-lingual Automatic Speech Recognition (ASR) networks can be scaled up with a simple routing algorithm in order to achieve better accuracy. More specifically, we apply the sparsely-gated MoE technique to two types of networks: Sequence-to-Sequence Transformer (S2S-T) and Transformer Transducer (T-T). We demonstrate through a set of ASR experiments on multiple language data that the MoE networks can reduce the relative word error rates by 16.3% and 4.6% with the S2S-T and T-T, respectively. Moreover, we thoroughly investigate the effect of the MoE on the T-T architecture in various conditions: streaming mode, non-streaming mode, the use of language ID and the label decoder with the MoE.
Multilingual Speech Recognition using Knowledge Transfer across Learning Processes
Oct 15, 2021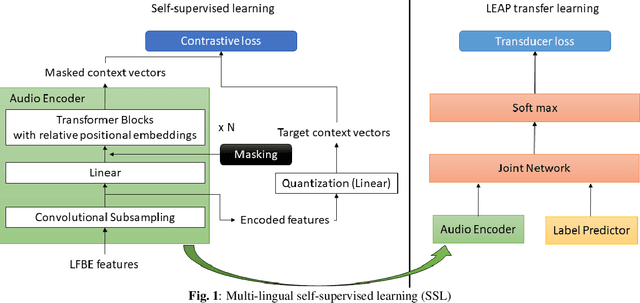
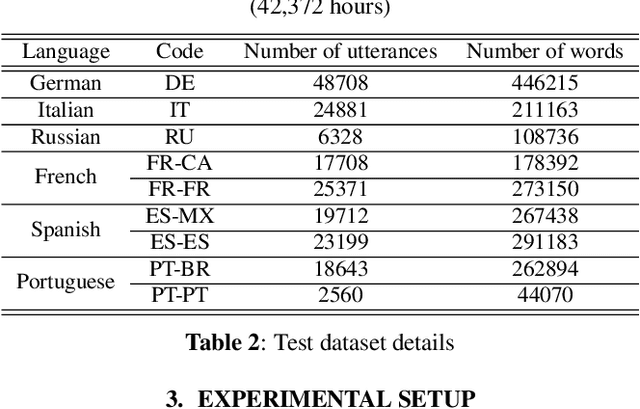
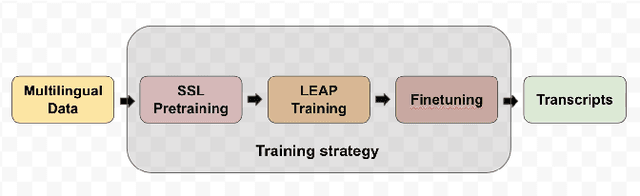
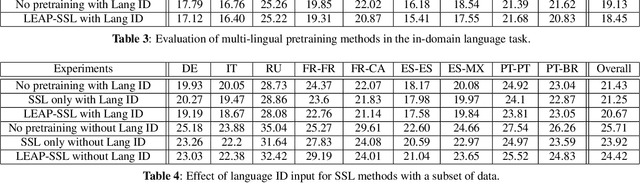
Multilingual end-to-end(E2E) models have shown a great potential in the expansion of the language coverage in the realm of automatic speech recognition(ASR). In this paper, we aim to enhance the multilingual ASR performance in two ways, 1)studying the impact of feeding a one-hot vector identifying the language, 2)formulating the task with a meta-learning objective combined with self-supervised learning (SSL). We associate every language with a distinct task manifold and attempt to improve the performance by transferring knowledge across learning processes itself as compared to transferring through final model parameters. We employ this strategy on a dataset comprising of 6 languages for an in-domain ASR task, by minimizing an objective related to expected gradient path length. Experimental results reveal the best pre-training strategy resulting in 3.55% relative reduction in overall WER. A combination of LEAP and SSL yields 3.51% relative reduction in overall WER when using language ID.
A Configurable Multilingual Model is All You Need to Recognize All Languages
Jul 13, 2021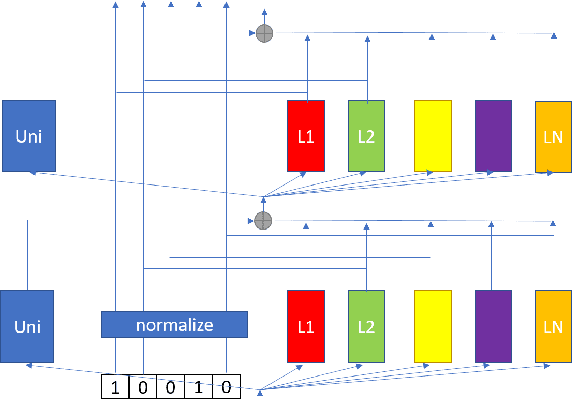
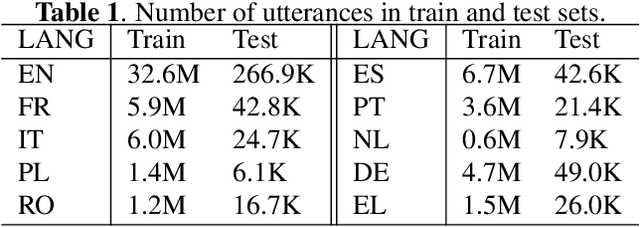
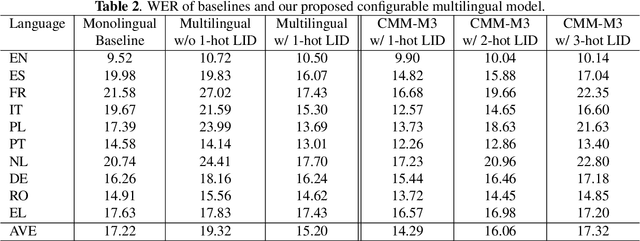
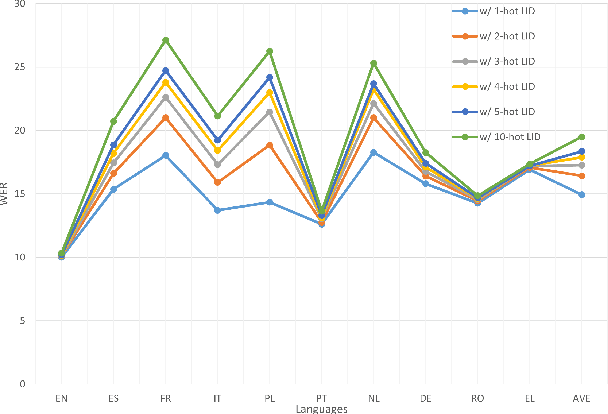
Multilingual automatic speech recognition (ASR) models have shown great promise in recent years because of the simplified model training and deployment process. Conventional methods either train a universal multilingual model without taking any language information or with a 1-hot language ID (LID) vector to guide the recognition of the target language. In practice, the user can be prompted to pre-select several languages he/she can speak. The multilingual model without LID cannot well utilize the language information set by the user while the multilingual model with LID can only handle one pre-selected language. In this paper, we propose a novel configurable multilingual model (CMM) which is trained only once but can be configured as different models based on users' choices by extracting language-specific modules together with a universal model from the trained CMM. Particularly, a single CMM can be deployed to any user scenario where the users can pre-select any combination of languages. Trained with 75K hours of transcribed anonymized Microsoft multilingual data and evaluated with 10-language test sets, the proposed CMM improves from the universal multilingual model by 26.0%, 16.9%, and 10.4% relative word error reduction when the user selects 1, 2, or 3 languages, respectively. CMM also performs significantly better on code-switching test sets.