 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMSQA: A Natively Sourced Multilingual and Multicultural SimpleQA Benchmark
Jul 01, 2026Multilingual fluency often invites a stronger assumption: a model that can speak a user's language must also understand the culture encoded by that language. We call this the Illusion of Cultural Alignment. To test this assumption directly, we introduce MSQA, a benchmark of 1,064 natively sourced questions across 11 language groups, five cultural dimensions, and three difficulty tiers. Unlike translated benchmarks, MSQA targets locally grounded knowledge and reduces shortcuts from English-centric cross-lingual transfer. Evaluating 18 LLMs, we find substantial cultural degradation and a pronounced Locality Effect: cultural competence tracks pre-training exposure more closely than general reasoning ability. We further show that common inference-time remedies do not dissolve the illusion. Models remain overconfident on unfamiliar cultural questions, repeated sampling yields unstable rather than reliable correctness, and retrieval augmentation helps unevenly on long-tail facts. These findings indicate that cultural alignment cannot be inferred from multilingual ability alone and requires deeper intervention than calibration, sampling, or retrieval at inference time
WebCompass: Towards Multimodal Web Coding Evaluation for Code Language Models
Apr 20, 2026Large language models are rapidly evolving into interactive coding agents capable of end-to-end web coding, yet existing benchmarks evaluate only narrow slices of this capability, typically text-conditioned generation with static-correctness metrics, leaving visual fidelity, interaction quality, and codebase-level reasoning largely unmeasured. We introduce WebCompass, a multimodal benchmark that provides unified lifecycle evaluation of web engineering capability. Recognizing that real-world web coding is an iterative cycle of generation, editing, and repair, WebCompass spans three input modalities (text, image, video) and three task types (generation, editing, repair), yielding seven task categories that mirror professional workflows. Through a multi-stage, human-in-the-loop pipeline, we curate instances covering 15 generation domains, 16 editing operation types, and 11 repair defect types, each annotated at Easy/Medium/Hard levels. For evaluation, we adopt a checklist-guided LLM-as-a-Judge protocol for editing and repair, and propose a novel Agent-as-a-Judge paradigm for generation that autonomously executes generated websites in a real browser, explores interactive behaviors via the Model Context Protocol (MCP), and iteratively synthesizes targeted test cases, closely approximating human acceptance testing. We evaluate representative closed-source and open-source models and observe that: (1) closed-source models remain substantially stronger and more balanced; (2) editing and repair exhibit distinct difficulty profiles, with repair preserving interactivity better but remaining execution-challenging; (3) aesthetics is the most persistent bottleneck, especially for open-source models; and (4) framework choice materially affects outcomes, with Vue consistently challenging while React and Vanilla/HTML perform more strongly depending on task type.
Color When It Counts: Grayscale-Guided Online Triggering for Always-On Streaming Video Sensing
Mar 23, 2026Always-on sensing is essential for next-generation edge/wearable AI systems, yet continuous high-fidelity RGB video capture remains prohibitively expensive for resource-constrained mobile and edge platforms. We present a new paradigm for efficient streaming video understanding: grayscale-always, color-on-demand. Through preliminary studies, we discover that color is not always necessary. Sparse RGB frames suffice for comparable performance when temporal structure is preserved via continuous grayscale streams. Building on this insight, we propose ColorTrigger, an online training-free trigger that selectively activates color capture based on windowed grayscale affinity analysis. Designed for real-time edge deployment, ColorTrigger uses lightweight quadratic programming to detect chromatic redundancy causally, coupled with credit-budgeted control and dynamic token routing to jointly reduce sensing and inference costs. On streaming video understanding benchmarks, ColorTrigger achieves 91.6% of full-color baseline performance while using only 8.1% RGB frames, demonstrating substantial color redundancy in natural videos and enabling practical always-on video sensing on resource-constrained devices.
Egocentric Co-Pilot: Web-Native Smart-Glasses Agents for Assistive Egocentric AI
Mar 01, 2026What if accessing the web did not require a screen, a stable desk, or even free hands? For people navigating crowded cities, living with low vision, or experiencing cognitive overload, smart glasses coupled with AI agents could turn the web into an always-on assistive layer over daily life. We present Egocentric Co-Pilot, a web-native neuro-symbolic framework that runs on smart glasses and uses a Large Language Model (LLM) to orchestrate a toolbox of perception, reasoning, and web tools. An egocentric reasoning core combines Temporal Chain-of-Thought with Hierarchical Context Compression to support long-horizon question answering and decision support over continuous first-person video, far beyond a single model's context window. Additionally, a lightweight multimodal intent layer maps noisy speech and gaze into structured commands. We further implement and evaluate a cloud-native WebRTC pipeline integrating streaming speech, video, and control messages into a unified channel for smart glasses and browsers. In parallel, we deploy an on-premise WebSocket baseline, exposing concrete trade-offs between local inference and cloud offloading in terms of latency, mobility, and resource use. Experiments on Egolife and HD-EPIC demonstrate competitive or state-of-the-art egocentric QA performance, and a human-in-the-loop study on smart glasses shows higher task completion and user satisfaction than leading commercial baselines. Taken together, these results indicate that web-connected egocentric co-pilots can be a practical path toward more accessible, context-aware assistance in everyday life. By grounding operation in web-native communication primitives and modular, auditable tool use, Egocentric Co-Pilot offers a concrete blueprint for assistive, always-on web agents that support education, accessibility, and social inclusion for people who may benefit most from contextual, egocentric AI.
EgoGraph: Temporal Knowledge Graph for Egocentric Video Understanding
Feb 27, 2026Ultra-long egocentric videos spanning multiple days present significant challenges for video understanding. Existing approaches still rely on fragmented local processing and limited temporal modeling, restricting their ability to reason over such extended sequences. To address these limitations, we introduce EgoGraph, a training-free and dynamic knowledge-graph construction framework that explicitly encodes long-term, cross-entity dependencies in egocentric video streams. EgoGraph employs a novel egocentric schema that unifies the extraction and abstraction of core entities, such as people, objects, locations, and events, and structurally reasons about their attributes and interactions, yielding a significantly richer and more coherent semantic representation than traditional clip-based video models. Crucially, we develop a temporal relational modeling strategy that captures temporal dependencies across entities and accumulates stable long-term memory over multiple days, enabling complex temporal reasoning. Extensive experiments on the EgoLifeQA and EgoR1-bench benchmarks demonstrate that EgoGraph achieves state-of-the-art performance on long-term video question answering, validating its effectiveness as a new paradigm for ultra-long egocentric video understanding.
SecCodeBench-V2 Technical Report
Feb 17, 2026We introduce SecCodeBench-V2, a publicly released benchmark for evaluating Large Language Model (LLM) copilots' capabilities of generating secure code. SecCodeBench-V2 comprises 98 generation and fix scenarios derived from Alibaba Group's industrial productions, where the underlying security issues span 22 common CWE (Common Weakness Enumeration) categories across five programming languages: Java, C, Python, Go, and Node.js. SecCodeBench-V2 adopts a function-level task formulation: each scenario provides a complete project scaffold and requires the model to implement or patch a designated target function under fixed interfaces and dependencies. For each scenario, SecCodeBench-V2 provides executable proof-of-concept (PoC) test cases for both functional validation and security verification. All test cases are authored and double-reviewed by security experts, ensuring high fidelity, broad coverage, and reliable ground truth. Beyond the benchmark itself, we build a unified evaluation pipeline that assesses models primarily via dynamic execution. For most scenarios, we compile and run model-generated artifacts in isolated environments and execute PoC test cases to validate both functional correctness and security properties. For scenarios where security issues cannot be adjudicated with deterministic test cases, we additionally employ an LLM-as-a-judge oracle. To summarize performance across heterogeneous scenarios and difficulty levels, we design a Pass@K-based scoring protocol with principled aggregation over scenarios and severity, enabling holistic and comparable evaluation across models. Overall, SecCodeBench-V2 provides a rigorous and reproducible foundation for assessing the security posture of AI coding assistants, with results and artifacts released at https://alibaba.github.io/sec-code-bench. The benchmark is publicly available at https://github.com/alibaba/sec-code-bench.
Optimizing Multimodal LLMs for Egocentric Video Understanding: A Solution for the HD-EPIC VQA Challenge
Jan 15, 2026Multimodal Large Language Models (MLLMs) struggle with complex video QA benchmarks like HD-EPIC VQA due to ambiguous queries/options, poor long-range temporal reasoning, and non-standardized outputs. We propose a framework integrating query/choice pre-processing, domain-specific Qwen2.5-VL fine-tuning, a novel Temporal Chain-of-Thought (T-CoT) prompting for multi-step reasoning, and robust post-processing. This system achieves 41.6% accuracy on HD-EPIC VQA, highlighting the need for holistic pipeline optimization in demanding video understanding. Our code, fine-tuned models are available at https://github.com/YoungSeng/Egocentric-Co-Pilot.
Plug-and-Play Clarifier: A Zero-Shot Multimodal Framework for Egocentric Intent Disambiguation
Nov 12, 2025



The performance of egocentric AI agents is fundamentally limited by multimodal intent ambiguity. This challenge arises from a combination of underspecified language, imperfect visual data, and deictic gestures, which frequently leads to task failure. Existing monolithic Vision-Language Models (VLMs) struggle to resolve these multimodal ambiguous inputs, often failing silently or hallucinating responses. To address these ambiguities, we introduce the Plug-and-Play Clarifier, a zero-shot and modular framework that decomposes the problem into discrete, solvable sub-tasks. Specifically, our framework consists of three synergistic modules: (1) a text clarifier that uses dialogue-driven reasoning to interactively disambiguate linguistic intent, (2) a vision clarifier that delivers real-time guidance feedback, instructing users to adjust their positioning for improved capture quality, and (3) a cross-modal clarifier with grounding mechanism that robustly interprets 3D pointing gestures and identifies the specific objects users are pointing to. Extensive experiments demonstrate that our framework improves the intent clarification performance of small language models (4--8B) by approximately 30%, making them competitive with significantly larger counterparts. We also observe consistent gains when applying our framework to these larger models. Furthermore, our vision clarifier increases corrective guidance accuracy by over 20%, and our cross-modal clarifier improves semantic answer accuracy for referential grounding by 5%. Overall, our method provides a plug-and-play framework that effectively resolves multimodal ambiguity and significantly enhances user experience in egocentric interaction.
Dolphin: A Large-Scale Automatic Speech Recognition Model for Eastern Languages
Mar 26, 2025This report introduces Dolphin, a large-scale multilingual automatic speech recognition (ASR) model that extends the Whisper architecture to support a wider range of languages. Our approach integrates in-house proprietary and open-source datasets to refine and optimize Dolphin's performance. The model is specifically designed to achieve notable recognition accuracy for 40 Eastern languages across East Asia, South Asia, Southeast Asia, and the Middle East, while also supporting 22 Chinese dialects. Experimental evaluations show that Dolphin significantly outperforms current state-of-the-art open-source models across various languages. To promote reproducibility and community-driven innovation, we are making our trained models and inference source code publicly available.
speechocean762: An Open-Source Non-native English Speech Corpus For Pronunciation Assessment
Apr 03, 2021
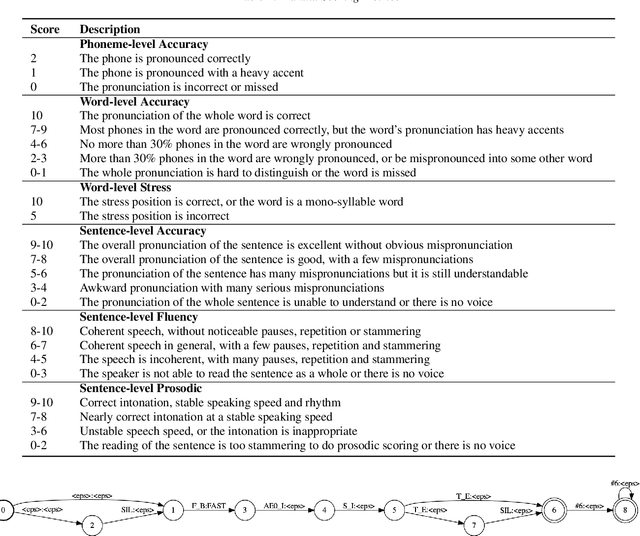
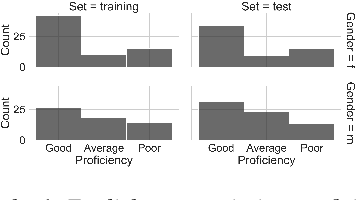

This paper introduces a new open-source speech corpus named "speechocean762" designed for pronunciation assessment use, consisting of 5000 English utterances from 250 non-native speakers, where half of the speakers are children. Five experts annotated each of the utterances at sentence-level, word-level and phoneme-level. A baseline system is released in open source to illustrate the phoneme-level pronunciation assessment workflow on this corpus. This corpus is allowed to be used freely for commercial and non-commercial purposes. It is available for free download from OpenSLR, and the corresponding baseline system is published in the Kaldi speech recognition toolkit.