 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHiD-VAE: Interpretable Generative Recommendation via Hierarchical and Disentangled Semantic IDs
Aug 06, 2025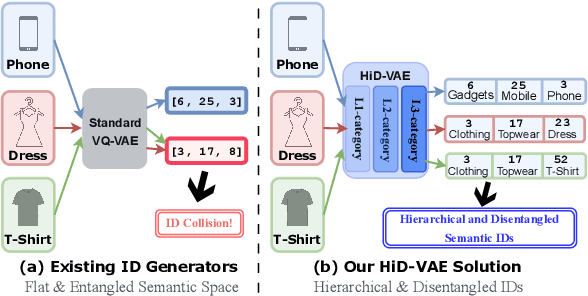
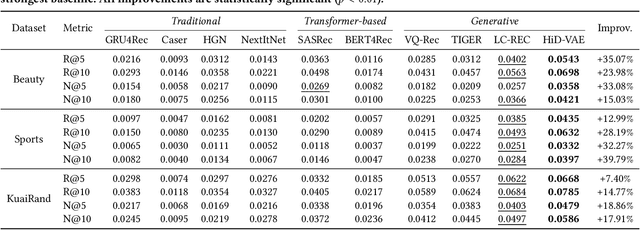
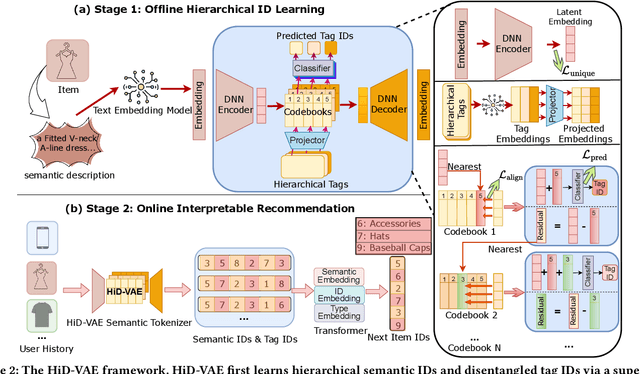
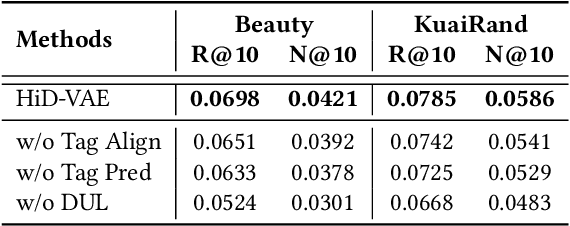
Recommender systems are indispensable for helping users navigate the immense item catalogs of modern online platforms. Recently, generative recommendation has emerged as a promising paradigm, unifying the conventional retrieve-and-rank pipeline into an end-to-end model capable of dynamic generation. However, existing generative methods are fundamentally constrained by their unsupervised tokenization, which generates semantic IDs suffering from two critical flaws: (1) they are semantically flat and uninterpretable, lacking a coherent hierarchy, and (2) they are prone to representation entanglement (i.e., ``ID collisions''), which harms recommendation accuracy and diversity. To overcome these limitations, we propose HiD-VAE, a novel framework that learns hierarchically disentangled item representations through two core innovations. First, HiD-VAE pioneers a hierarchically-supervised quantization process that aligns discrete codes with multi-level item tags, yielding more uniform and disentangled IDs. Crucially, the trained codebooks can predict hierarchical tags, providing a traceable and interpretable semantic path for each recommendation. Second, to combat representation entanglement, HiD-VAE incorporates a novel uniqueness loss that directly penalizes latent space overlap. This mechanism not only resolves the critical ID collision problem but also promotes recommendation diversity by ensuring a more comprehensive utilization of the item representation space. These high-quality, disentangled IDs provide a powerful foundation for downstream generative models. Extensive experiments on three public benchmarks validate HiD-VAE's superior performance against state-of-the-art methods. The code is available at https://anonymous.4open.science/r/HiD-VAE-84B2.
Can Large Multimodal Models Actively Recognize Faulty Inputs? A Systematic Evaluation Framework of Their Input Scrutiny Ability
Aug 06, 2025
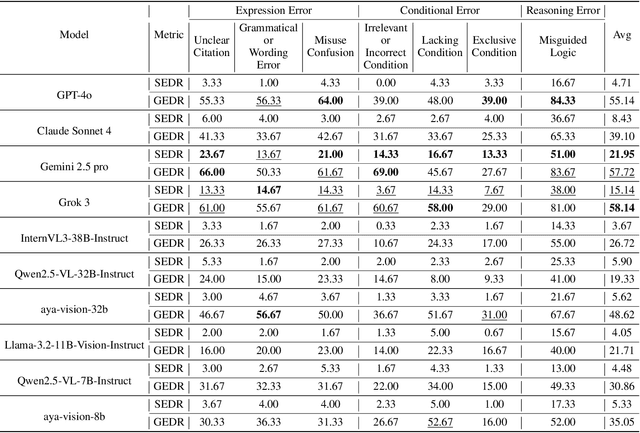
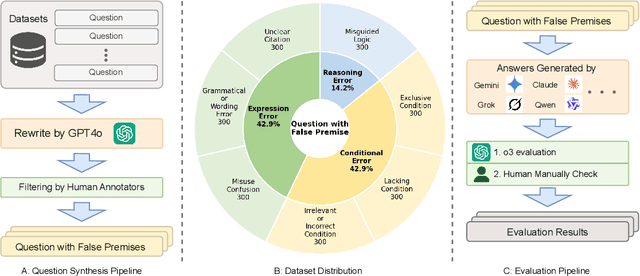
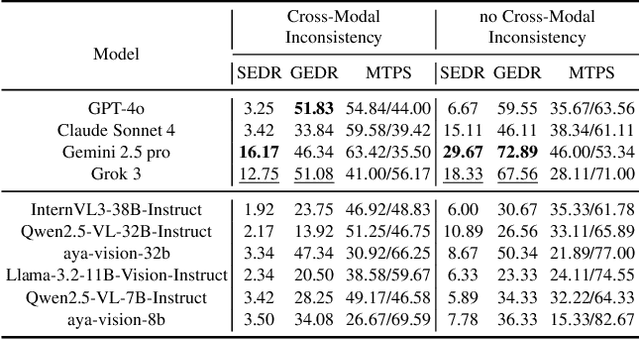
Large Multimodal Models (LMMs) have witnessed remarkable growth, showcasing formidable capabilities in handling intricate multimodal tasks with exceptional performance. Recent research has underscored the inclination of large language models to passively accept defective inputs, often resulting in futile reasoning on invalid prompts. However, the same critical question of whether LMMs can actively detect and scrutinize erroneous inputs still remains unexplored. To address this gap, we introduce the Input Scrutiny Ability Evaluation Framework (ISEval), which encompasses seven categories of flawed premises and three evaluation metrics. Our extensive evaluation of ten advanced LMMs has identified key findings. Most models struggle to actively detect flawed textual premises without guidance, which reflects a strong reliance on explicit prompts for premise error identification. Error type affects performance: models excel at identifying logical fallacies but struggle with surface-level linguistic errors and certain conditional flaws. Modality trust varies-Gemini 2.5 pro and Claude Sonnet 4 balance visual and textual info, while aya-vision-8b over-rely on text in conflicts. These insights underscore the urgent need to enhance LMMs' proactive verification of input validity and shed novel insights into mitigating the problem. The code is available at https://github.com/MLGroupJLU/LMM_ISEval.
ConfProBench: A Confidence Evaluation Benchmark for MLLM-Based Process Judges
Aug 06, 2025



Reasoning is a critical capability of multimodal large language models (MLLMs) for solving complex multimodal tasks, and judging the correctness of reasoning steps is crucial for improving this capability. Recently, MLLM-based process judges (MPJs) have been widely used to assess the correctness of reasoning steps in multimodal tasks. Therefore, evaluating MPJs is important for identifying their limitations and guiding future improvements. However, existing benchmarks for MPJs mainly focus on tasks such as step correctness classification and reasoning process search, while overlooking a key aspect: whether the confidence scores produced by MPJs at the step level are reliable. To address this gap, we propose ConfProBench, the first comprehensive benchmark designed to systematically evaluate the reliability of step-level confidence scores generated by MPJs. Our benchmark constructs three types of adversarially perturbed reasoning steps: Synonym Substitution, Syntactic Transformation, and Image Perturbation, to test the robustness of MPJ confidence under perturbations. In addition, we introduce three novel evaluation metrics: Confidence Robustness Score (CRS), Confidence Sensitivity Score (CSS), and Confidence Calibration Score (CCS), which evaluate robustness, sensitivity, and calibration, respectively. We evaluate 14 state-of-the-art MLLMs, including both proprietary and open-source models. Experiments reveal limitations in current MPJs' confidence performance and offer competitive baselines to support future research.
Rethinking Discrete Tokens: Treating Them as Conditions for Continuous Autoregressive Image Synthesis
Jul 02, 2025Recent advances in large language models (LLMs) have spurred interests in encoding images as discrete tokens and leveraging autoregressive (AR) frameworks for visual generation. However, the quantization process in AR-based visual generation models inherently introduces information loss that degrades image fidelity. To mitigate this limitation, recent studies have explored to autoregressively predict continuous tokens. Unlike discrete tokens that reside in a structured and bounded space, continuous representations exist in an unbounded, high-dimensional space, making density estimation more challenging and increasing the risk of generating out-of-distribution artifacts. Based on the above findings, this work introduces DisCon (Discrete-Conditioned Continuous Autoregressive Model), a novel framework that reinterprets discrete tokens as conditional signals rather than generation targets. By modeling the conditional probability of continuous representations conditioned on discrete tokens, DisCon circumvents the optimization challenges of continuous token modeling while avoiding the information loss caused by quantization. DisCon achieves a gFID score of 1.38 on ImageNet 256$\times$256 generation, outperforming state-of-the-art autoregressive approaches by a clear margin.
Training-free LLM Merging for Multi-task Learning
Jun 14, 2025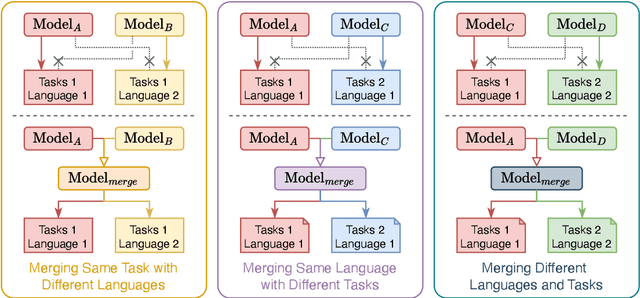
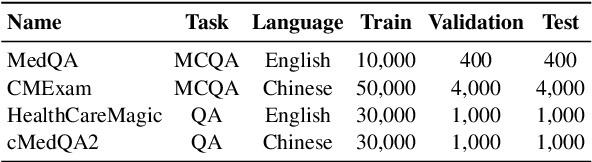
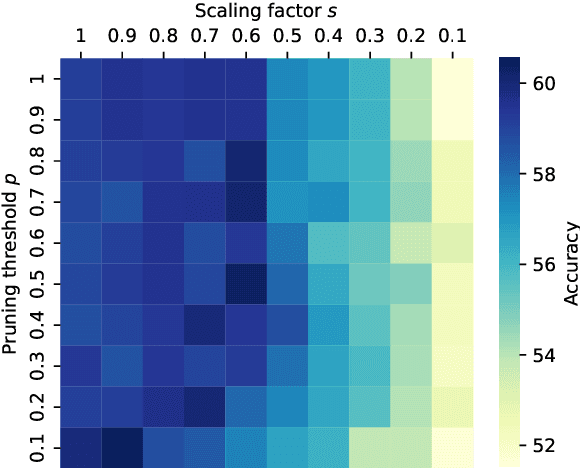
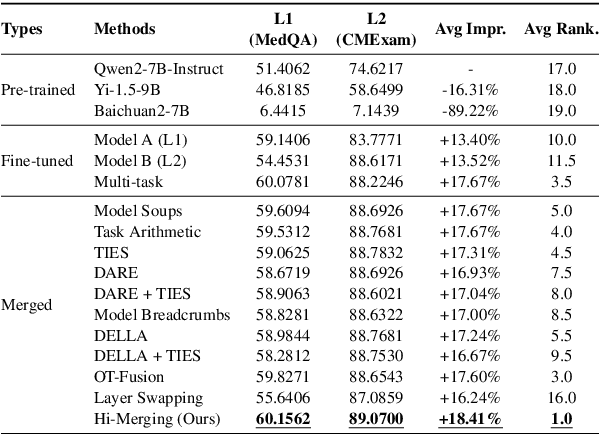
Large Language Models (LLMs) have demonstrated exceptional capabilities across diverse natural language processing (NLP) tasks. The release of open-source LLMs like LLaMA and Qwen has triggered the development of numerous fine-tuned models tailored for various tasks and languages. In this paper, we explore an important question: is it possible to combine these specialized models to create a unified model with multi-task capabilities. We introduces Hierarchical Iterative Merging (Hi-Merging), a training-free method for unifying different specialized LLMs into a single model. Specifically, Hi-Merging employs model-wise and layer-wise pruning and scaling, guided by contribution analysis, to mitigate parameter conflicts. Extensive experiments on multiple-choice and question-answering tasks in both Chinese and English validate Hi-Merging's ability for multi-task learning. The results demonstrate that Hi-Merging consistently outperforms existing merging techniques and surpasses the performance of models fine-tuned on combined datasets in most scenarios. Code is available at: https://github.com/Applied-Machine-Learning-Lab/Hi-Merging.
* 14 pages, 6 figures
A Survey of Retentive Network
Jun 07, 2025Retentive Network (RetNet) represents a significant advancement in neural network architecture, offering an efficient alternative to the Transformer. While Transformers rely on self-attention to model dependencies, they suffer from high memory costs and limited scalability when handling long sequences due to their quadratic complexity. To mitigate these limitations, RetNet introduces a retention mechanism that unifies the inductive bias of recurrence with the global dependency modeling of attention. This mechanism enables linear-time inference, facilitates efficient modeling of extended contexts, and remains compatible with fully parallelizable training pipelines. RetNet has garnered significant research interest due to its consistently demonstrated cross-domain effectiveness, achieving robust performance across machine learning paradigms including natural language processing, speech recognition, and time-series analysis. However, a comprehensive review of RetNet is still missing from the current literature. This paper aims to fill that gap by offering the first detailed survey of the RetNet architecture, its key innovations, and its diverse applications. We also explore the main challenges associated with RetNet and propose future research directions to support its continued advancement in both academic research and practical deployment.
Don't Take the Premise for Granted: Evaluating the Premise Critique Ability of Large Language Models
May 29, 2025Large language models (LLMs) have witnessed rapid advancements, demonstrating remarkable capabilities. However, a notable vulnerability persists: LLMs often uncritically accept flawed or contradictory premises, leading to inefficient reasoning and unreliable outputs. This emphasizes the significance of possessing the \textbf{Premise Critique Ability} for LLMs, defined as the capacity to proactively identify and articulate errors in input premises. Most existing studies assess LLMs' reasoning ability in ideal settings, largely ignoring their vulnerabilities when faced with flawed premises. Thus, we introduce the \textbf{Premise Critique Bench (PCBench)}, designed by incorporating four error types across three difficulty levels, paired with multi-faceted evaluation metrics. We conducted systematic evaluations of 15 representative LLMs. Our findings reveal: (1) Most models rely heavily on explicit prompts to detect errors, with limited autonomous critique; (2) Premise critique ability depends on question difficulty and error type, with direct contradictions being easier to detect than complex or procedural errors; (3) Reasoning ability does not consistently correlate with the premise critique ability; (4) Flawed premises trigger overthinking in reasoning models, markedly lengthening responses due to repeated attempts at resolving conflicts. These insights underscore the urgent need to enhance LLMs' proactive evaluation of input validity, positioning premise critique as a foundational capability for developing reliable, human-centric systems. The code is available at https://github.com/MLGroupJLU/Premise_Critique.
THINK-Bench: Evaluating Thinking Efficiency and Chain-of-Thought Quality of Large Reasoning Models
May 28, 2025



Large reasoning models (LRMs) have achieved impressive performance in complex tasks, often outperforming conventional large language models (LLMs). However, the prevalent issue of overthinking severely limits their computational efficiency. Overthinking occurs when models generate excessive and redundant tokens that contribute little to accurate outcomes, especially in simple tasks, resulting in a significant waste of computational resources. To systematically investigate this issue, we introduce Think-Bench, a benchmark designed to evaluate the reasoning efficiency of LRMs. We also propose novel efficiency metrics and conduct a comprehensive evaluation of various LRMs across multiple dimensions, including the reasoning process, outcome quality, and chain-of-thought (CoT) characteristics. Our analysis reveals that most LRMs exhibit overthinking in handling easy questions, generating unnecessarily lengthy reasoning chains. While many LRMs demonstrate high CoT quality, several suffer from low efficiency. We hope that Think-Bench can serve as a robust foundation for advancing research into LRMs.
Decision Flow Policy Optimization
May 26, 2025In recent years, generative models have shown remarkable capabilities across diverse fields, including images, videos, language, and decision-making. By applying powerful generative models such as flow-based models to reinforcement learning, we can effectively model complex multi-modal action distributions and achieve superior robotic control in continuous action spaces, surpassing the limitations of single-modal action distributions with traditional Gaussian-based policies. Previous methods usually adopt the generative models as behavior models to fit state-conditioned action distributions from datasets, with policy optimization conducted separately through additional policies using value-based sample weighting or gradient-based updates. However, this separation prevents the simultaneous optimization of multi-modal distribution fitting and policy improvement, ultimately hindering the training of models and degrading the performance. To address this issue, we propose Decision Flow, a unified framework that integrates multi-modal action distribution modeling and policy optimization. Specifically, our method formulates the action generation procedure of flow-based models as a flow decision-making process, where each action generation step corresponds to one flow decision. Consequently, our method seamlessly optimizes the flow policy while capturing multi-modal action distributions. We provide rigorous proofs of Decision Flow and validate the effectiveness through extensive experiments across dozens of offline RL environments. Compared with established offline RL baselines, the results demonstrate that our method achieves or matches the SOTA performance.
ScreenExplorer: Training a Vision-Language Model for Diverse Exploration in Open GUI World
May 25, 2025



The rapid progress of large language models (LLMs) has sparked growing interest in building Artificial General Intelligence (AGI) within Graphical User Interface (GUI) environments. However, existing GUI agents based on LLMs or vision-language models (VLMs) often fail to generalize to novel environments and rely heavily on manually curated, diverse datasets. To overcome these limitations, we introduce ScreenExplorer, a VLM trained via Group Relative Policy Optimization(GRPO) in real, dynamic, and open-ended GUI environments. Innovatively, we introduced a world-model-based curiosity reward function to help the agent overcome the cold-start phase of exploration. Additionally, distilling experience streams further enhances the model's exploration capabilities. Our training framework enhances model exploration in open GUI environments, with trained models showing better environmental adaptation and sustained exploration compared to static deployment models. Our findings offer a scalable pathway toward AGI systems with self-improving capabilities in complex interactive settings.