 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSS-Auto: A Single-Shot, Automatic Structured Weight Pruning Framework of DNNs with Ultra-High Efficiency
Jan 23, 2020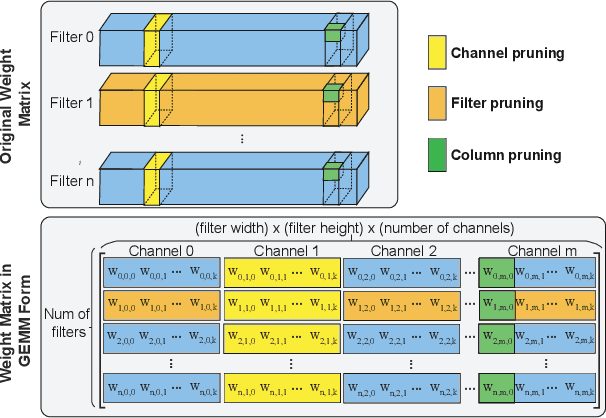
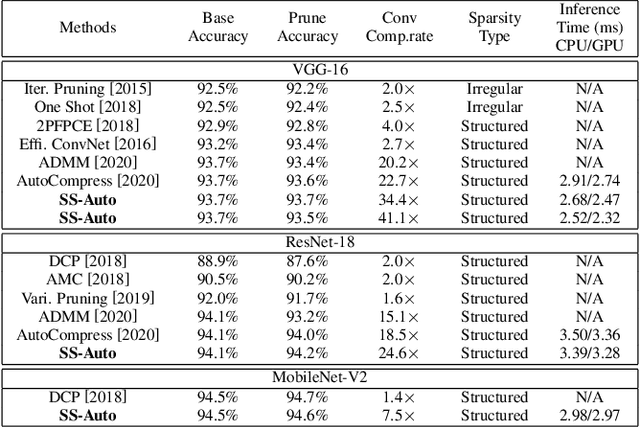
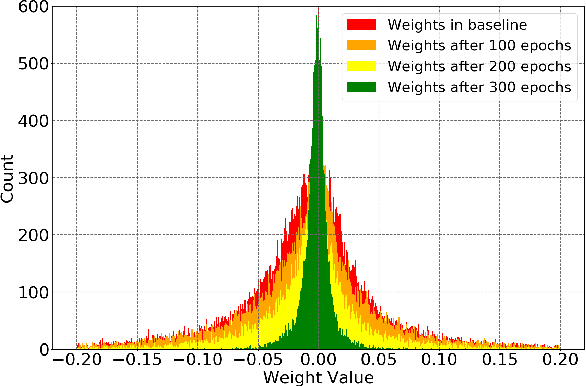
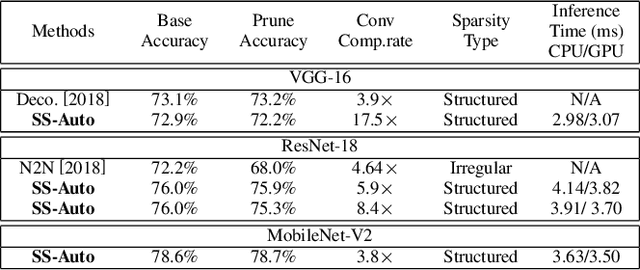
Structured weight pruning is a representative model compression technique of DNNs for hardware efficiency and inference accelerations. Previous works in this area leave great space for improvement since sparse structures with combinations of different structured pruning schemes are not exploited fully and efficiently. To mitigate the limitations, we propose SS-Auto, a single-shot, automatic structured pruning framework that can achieve row pruning and column pruning simultaneously. We adopt soft constraint-based formulation to alleviate the strong non-convexity of l0-norm constraints used in state-of-the-art ADMM-based methods for faster convergence and fewer hyperparameters. Instead of solving the problem directly, a Primal-Proximal solution is proposed to avoid the pitfall of penalizing all weights equally, thereby enhancing the accuracy. Extensive experiments on CIFAR-10 and CIFAR-100 datasets demonstrate that the proposed framework can achieve ultra-high pruning rates while maintaining accuracy. Furthermore, significant inference speedup has been observed from the proposed framework through actual measurements on the smartphone.
Embedding Compression with Isotropic Iterative Quantization
Jan 23, 2020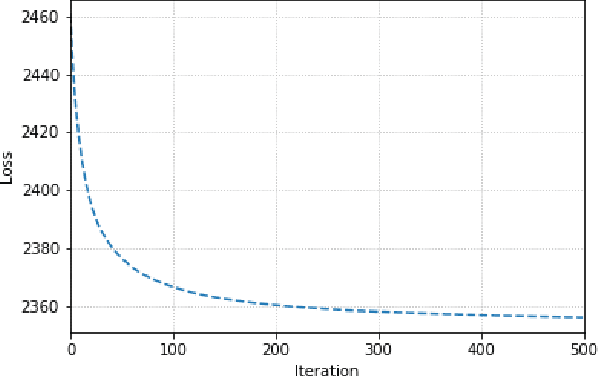
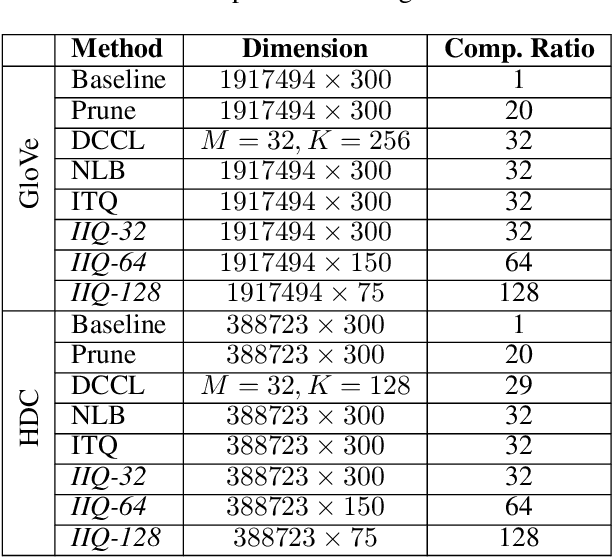
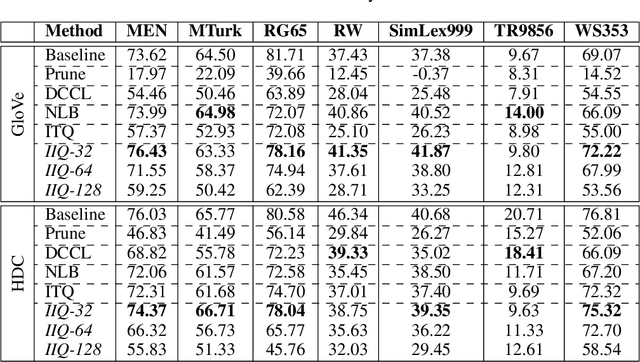
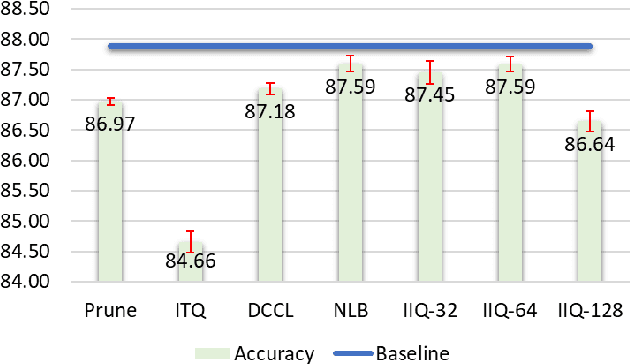
Continuous representation of words is a standard component in deep learning-based NLP models. However, representing a large vocabulary requires significant memory, which can cause problems, particularly on resource-constrained platforms. Therefore, in this paper we propose an isotropic iterative quantization (IIQ) approach for compressing embedding vectors into binary ones, leveraging the iterative quantization technique well established for image retrieval, while satisfying the desired isotropic property of PMI based models. Experiments with pre-trained embeddings (i.e., GloVe and HDC) demonstrate a more than thirty-fold compression ratio with comparable and sometimes even improved performance over the original real-valued embedding vectors.
PatDNN: Achieving Real-Time DNN Execution on Mobile Devices with Pattern-based Weight Pruning
Jan 22, 2020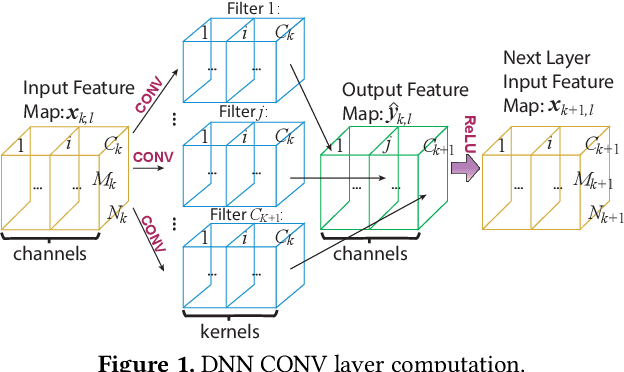
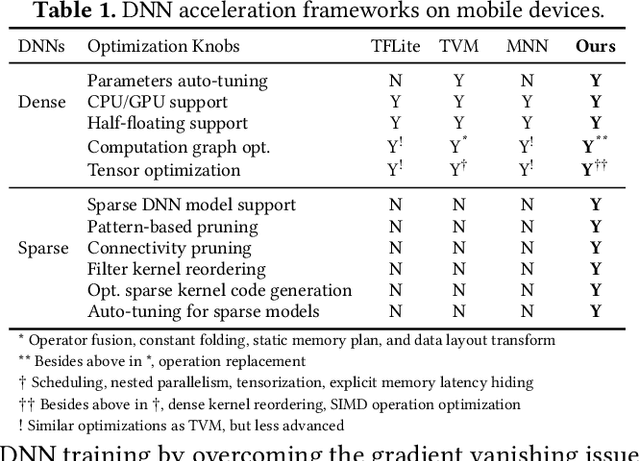
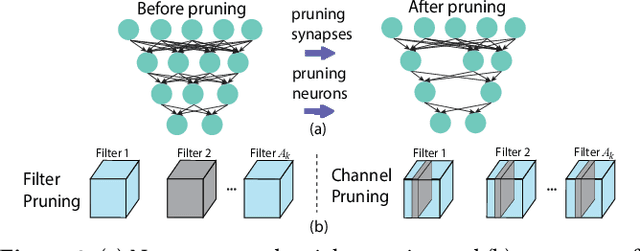
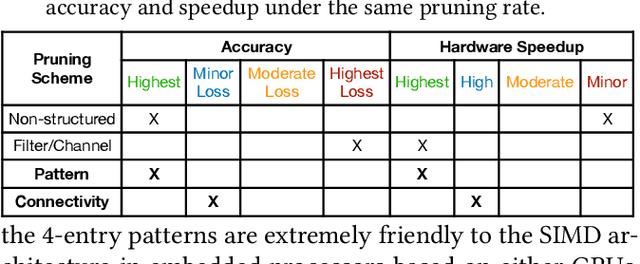
With the emergence of a spectrum of high-end mobile devices, many applications that formerly required desktop-level computation capability are being transferred to these devices. However, executing the inference of Deep Neural Networks (DNNs) is still challenging considering high computation and storage demands, specifically, if real-time performance with high accuracy is needed. Weight pruning of DNNs is proposed, but existing schemes represent two extremes in the design space: non-structured pruning is fine-grained, accurate, but not hardware friendly; structured pruning is coarse-grained, hardware-efficient, but with higher accuracy loss. In this paper, we introduce a new dimension, fine-grained pruning patterns inside the coarse-grained structures, revealing a previously unknown point in design space. With the higher accuracy enabled by fine-grained pruning patterns, the unique insight is to use the compiler to re-gain and guarantee high hardware efficiency. In other words, our method achieves the best of both worlds, and is desirable across theory/algorithm, compiler, and hardware levels. The proposed PatDNN is an end-to-end framework to efficiently execute DNN on mobile devices with the help of a novel model compression technique (pattern-based pruning based on extended ADMM solution framework) and a set of thorough architecture-aware compiler- and code generation-based optimizations (filter kernel reordering, compressed weight storage, register load redundancy elimination, and parameter auto-tuning). Evaluation results demonstrate that PatDNN outperforms three state-of-the-art end-to-end DNN frameworks, TensorFlow Lite, TVM, and Alibaba Mobile Neural Network with speedup up to 44.5x, 11.4x, and 7.1x, respectively, with no accuracy compromise. Real-time inference of representative large-scale DNNs (e.g., VGG-16, ResNet-50) can be achieved using mobile devices.
Adversarial T-shirt! Evading Person Detectors in A Physical World
Nov 27, 2019It is known that deep neural networks (DNNs) are vulnerable to adversarial attacks. The so-called physical adversarial examples deceive DNN-based decision makers by attaching adversarial patches to real objects. However, most of the existing works on physical adversarial attacks focus on static objects such as glass frames, stop signs and images attached to cardboard. In this work, we propose Adversarial T-shirts, a robust physical adversarial example for evading person detectors even if it could undergo non-rigid deformation due to a moving person's pose changes. To the best of our knowledge, this is the first work that models the effect of deformation for designing physical adversarial examples with respect to non-rigid objects such as T-shirts. We show that the proposed method achieves 74% and 57% attack success rates in digital and physical worlds respectively against YOLOv2. In contrast, the state-of-the-art physical attack method to fool a person detector only achieves 18% attack success rate. Furthermore, by leveraging min-max optimization, we extend our method to the ensemble attack setting against two object detectors YOLO-v2 and Faster R-CNN simultaneously.
DARB: A Density-Aware Regular-Block Pruning for Deep Neural Networks
Nov 20, 2019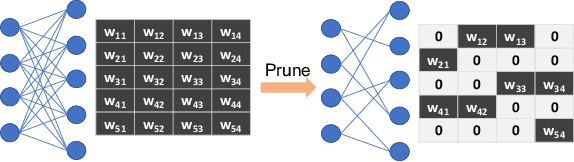
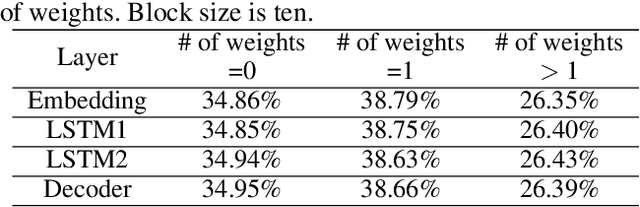
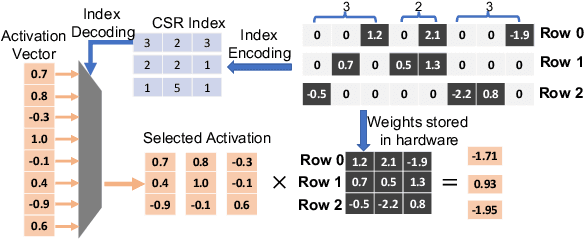
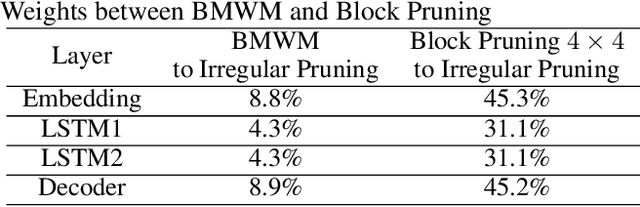
The rapidly growing parameter volume of deep neural networks (DNNs) hinders the artificial intelligence applications on resource constrained devices, such as mobile and wearable devices. Neural network pruning, as one of the mainstream model compression techniques, is under extensive study to reduce the number of parameters and computations. In contrast to irregular pruning that incurs high index storage and decoding overhead, structured pruning techniques have been proposed as the promising solutions. However, prior studies on structured pruning tackle the problem mainly from the perspective of facilitating hardware implementation, without analyzing the characteristics of sparse neural networks. The neglect on the study of sparse neural networks causes inefficient trade-off between regularity and pruning ratio. Consequently, the potential of structurally pruning neural networks is not sufficiently mined. In this work, we examine the structural characteristics of the irregularly pruned weight matrices, such as the diverse redundancy of different rows, the sensitivity of different rows to pruning, and the positional characteristics of retained weights. By leveraging the gained insights as a guidance, we first propose the novel block-max weight masking (BMWM) method, which can effectively retain the salient weights while imposing high regularity to the weight matrix. As a further optimization, we propose a density-adaptive regular-block (DARB) pruning that outperforms prior structured pruning work with high pruning ratio and decoding efficiency. Our experimental results show that DARB can achieve 13$\times$ to 25$\times$ pruning ratio, which are 2.8$\times$ to 4.3$\times$ improvements than the state-of-the-art counterparts on multiple neural network models and tasks. Moreover, DARB can achieve 14.3$\times$ decoding efficiency than block pruning with higher pruning ratio.
Deep Compressed Pneumonia Detection for Low-Power Embedded Devices
Nov 04, 2019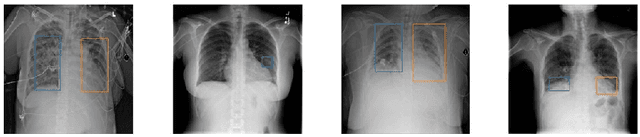
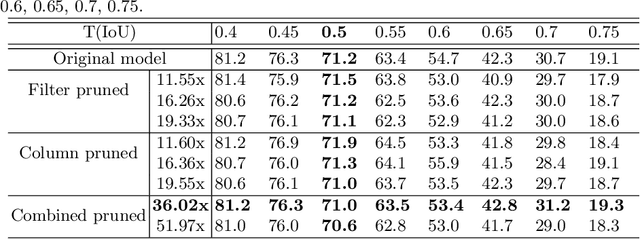
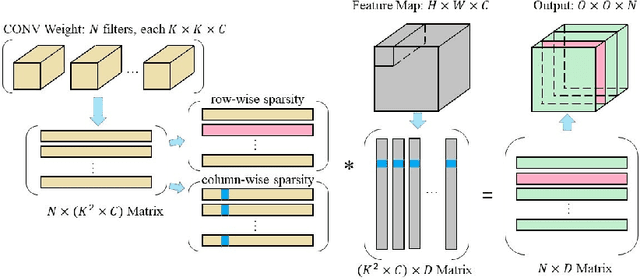
Deep neural networks (DNNs) have been expanded into medical fields and triggered the revolution of some medical applications by extracting complex features and achieving high accuracy and performance, etc. On the contrast, the large-scale network brings high requirements of both memory storage and computation resource, especially for portable medical devices and other embedded systems. In this work, we first train a DNN for pneumonia detection using the dataset provided by RSNA Pneumonia Detection Challenge. To overcome hardware limitation for implementing large-scale networks, we develop a systematic structured weight pruning method with filter sparsity, column sparsity and combined sparsity. Experiments show that we can achieve up to 36x compression ratio compared to the original model with 106 layers, while maintaining no accuracy degradation. We evaluate the proposed methods on an embedded low-power device, Jetson TX2, and achieve low power usage and high energy efficiency.
SPEC2: SPECtral SParsE CNN Accelerator on FPGAs
Oct 16, 2019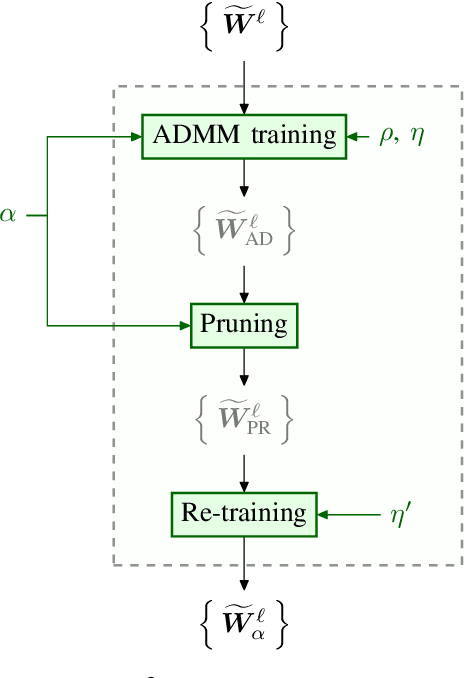
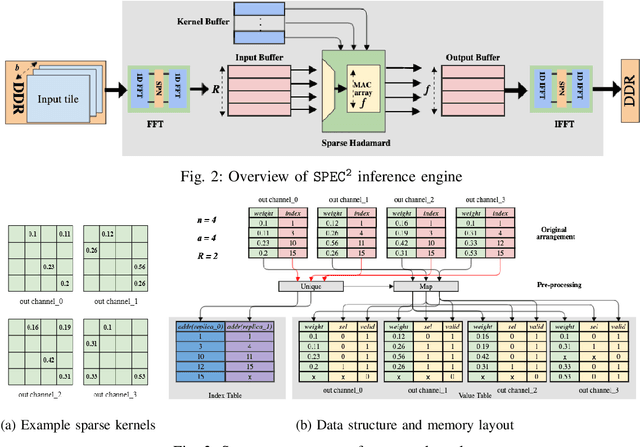

To accelerate inference of Convolutional Neural Networks (CNNs), various techniques have been proposed to reduce computation redundancy. Converting convolutional layers into frequency domain significantly reduces the computation complexity of the sliding window operations in space domain. On the other hand, weight pruning techniques address the redundancy in model parameters by converting dense convolutional kernels into sparse ones. To obtain high-throughput FPGA implementation, we propose SPEC2 -- the first work to prune and accelerate spectral CNNs. First, we propose a systematic pruning algorithm based on Alternative Direction Method of Multipliers (ADMM). The offline pruning iteratively sets the majority of spectral weights to zero, without using any handcrafted heuristics. Then, we design an optimized pipeline architecture on FPGA that has efficient random access into the sparse kernels and exploits various dimensions of parallelism in convolutional layers. Overall, SPEC2 achieves high inference throughput with extremely low computation complexity and negligible accuracy degradation. We demonstrate SPEC2 by pruning and implementing LeNet and VGG16 on the Xilinx Virtex platform. After pruning 75% of the spectral weights, SPEC2 achieves 0% accuracy loss for LeNet, and <1% accuracy loss for VGG16. The resulting accelerators achieve up to 24x higher throughput, compared with the state-of-the-art FPGA implementations for VGG16.
REQ-YOLO: A Resource-Aware, Efficient Quantization Framework for Object Detection on FPGAs
Sep 29, 2019
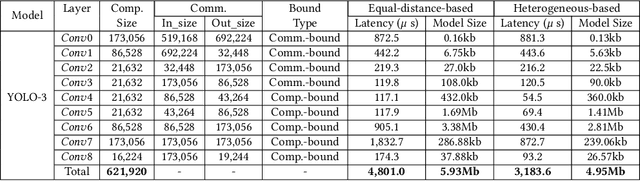
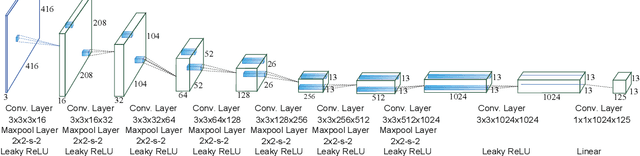

Deep neural networks (DNNs), as the basis of object detection, will play a key role in the development of future autonomous systems with full autonomy. The autonomous systems have special requirements of real-time, energy-efficient implementations of DNNs on a power-constrained system. Two research thrusts are dedicated to performance and energy efficiency enhancement of the inference phase of DNNs. The first one is model compression techniques while the second is efficient hardware implementation. Recent works on extremely-low-bit CNNs such as the binary neural network (BNN) and XNOR-Net replace the traditional floating-point operations with binary bit operations which significantly reduces the memory bandwidth and storage requirement. However, it suffers from non-negligible accuracy loss and underutilized digital signal processing (DSP) blocks of FPGAs. To overcome these limitations, this paper proposes REQ-YOLO, a resource-aware, systematic weight quantization framework for object detection, considering both algorithm and hardware resource aspects in object detection. We adopt the block-circulant matrix method and propose a heterogeneous weight quantization using the Alternating Direction Method of Multipliers (ADMM), an effective optimization technique for general, non-convex optimization problems. To achieve real-time, highly-efficient implementations on FPGA, we present the detailed hardware implementation of block circulant matrices on CONV layers and develop an efficient processing element (PE) structure supporting the heterogeneous weight quantization, CONV dataflow and pipelining techniques, design optimization, and a template-based automatic synthesis framework to optimally exploit hardware resource. Experimental results show that our proposed REQ-YOLO framework can significantly compress the YOLO model while introducing very small accuracy degradation.
Reweighted Proximal Pruning for Large-Scale Language Representation
Sep 27, 2019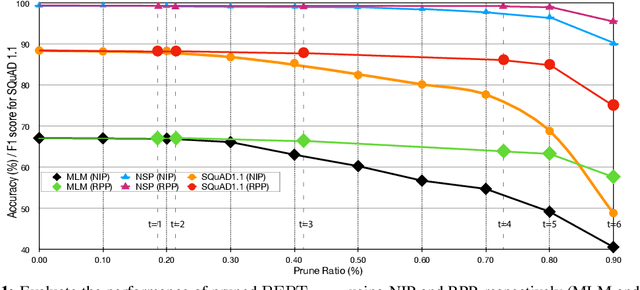
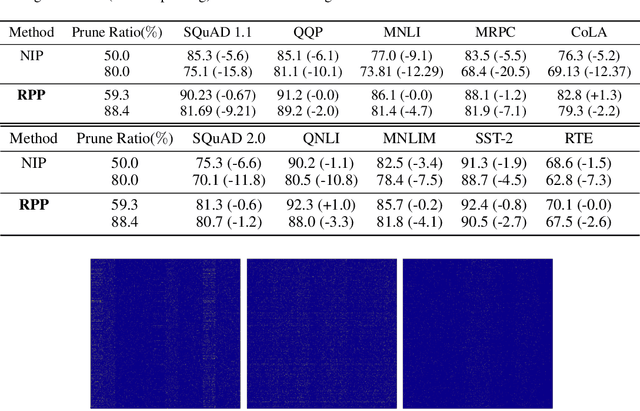
Recently, pre-trained language representation flourishes as the mainstay of the natural language understanding community, e.g., BERT. These pre-trained language representations can create state-of-the-art results on a wide range of downstream tasks. Along with continuous significant performance improvement, the size and complexity of these pre-trained neural models continue to increase rapidly. Is it possible to compress these large-scale language representation models? How will the pruned language representation affect the downstream multi-task transfer learning objectives? In this paper, we propose Reweighted Proximal Pruning (RPP), a new pruning method specifically designed for a large-scale language representation model. Through experiments on SQuAD and the GLUE benchmark suite, we show that proximal pruned BERT keeps high accuracy for both the pre-training task and the downstream multiple fine-tuning tasks at high prune ratio. RPP provides a new perspective to help us analyze what large-scale language representation might learn. Additionally, RPP makes it possible to deploy a large state-of-the-art language representation model such as BERT on a series of distinct devices (e.g., online servers, mobile phones, and edge devices).
PCONV: The Missing but Desirable Sparsity in DNN Weight Pruning for Real-time Execution on Mobile Devices
Sep 12, 2019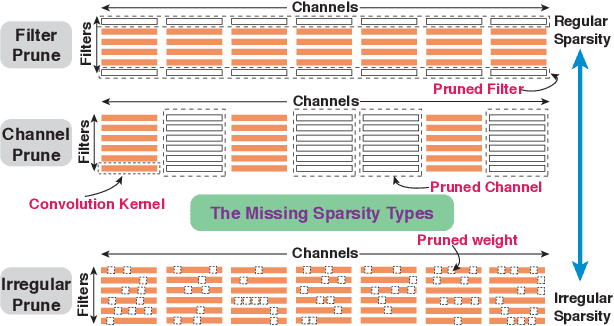
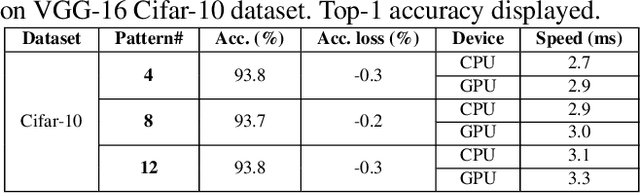
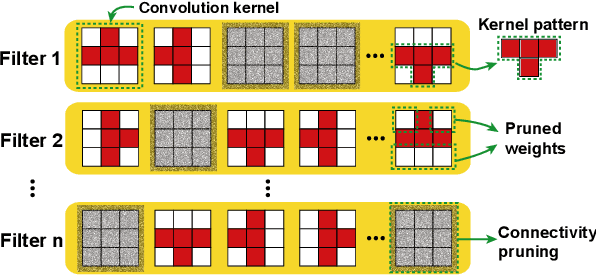
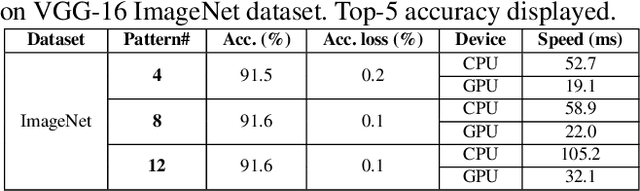
Model compression techniques on Deep Neural Network (DNN) have been widely acknowledged as an effective way to achieve acceleration on a variety of platforms, and DNN weight pruning is a straightforward and effective method. There are currently two mainstreams of pruning methods representing two extremes of pruning regularity: non-structured, fine-grained pruning can achieve high sparsity and accuracy, but is not hardware friendly; structured, coarse-grained pruning exploits hardware-efficient structures in pruning, but suffers from accuracy drop when the pruning rate is high. In this paper, we introduce PCONV, comprising a new sparsity dimension, -- fine-grained pruning patterns inside the coarse-grained structures. PCONV comprises two types of sparsities, Sparse Convolution Patterns (SCP) which is generated from intra-convolution kernel pruning and connectivity sparsity generated from inter-convolution kernel pruning. Essentially, SCP enhances accuracy due to its special vision properties, and connectivity sparsity increases pruning rate while maintaining balanced workload on filter computation. To deploy PCONV, we develop a novel compiler-assisted DNN inference framework and execute PCONV models in real-time without accuracy compromise, which cannot be achieved in prior work. Our experimental results show that, PCONV outperforms three state-of-art end-to-end DNN frameworks, TensorFlow-Lite, TVM, and Alibaba Mobile Neural Network with speedup up to 39.2x, 11.4x, and 6.3x, respectively, with no accuracy loss. Mobile devices can achieve real-time inference on large-scale DNNs.