 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeES-dLLM: Efficient Inference for Diffusion Large Language Models by Early-Skipping
Mar 10, 2026Diffusion large language models (dLLMs) are emerging as a promising alternative to autoregressive models (ARMs) due to their ability to capture bidirectional context and the potential for parallel generation. Despite the advantages, dLLM inference remains computationally expensive as the full input context is processed at every iteration. In this work, we analyze the generation dynamics of dLLMs and find that intermediate representations, including key, value, and hidden states, change only subtly across successive iterations. Leveraging this insight, we propose \textbf{ES-dLLM}, a training-free inference acceleration framework for dLLM that reduces computation by skipping tokens in early layers based on the estimated importance. Token importance is computed with intermediate tensor variation and confidence scores of previous iterations. Experiments on LLaDA-8B and Dream-7B demonstrate that ES-dLLM achieves throughput of up to 226.57 and 308.51 tokens per second (TPS), respectively, on an NVIDIA H200 GPU, delivering 5.6$\times$ to 16.8$\times$ speedup over the vanilla implementation and up to 1.85$\times$ over the state-of-the-art caching method, while preserving generation quality.
SoFar: Language-Grounded Orientation Bridges Spatial Reasoning and Object Manipulation
Feb 18, 2025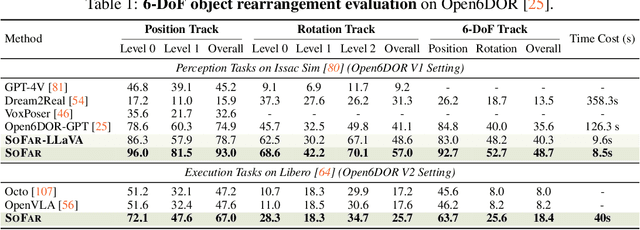

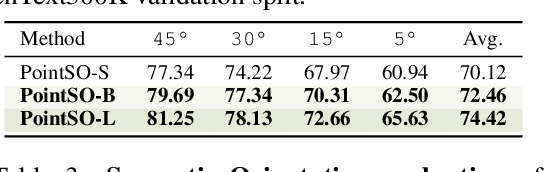
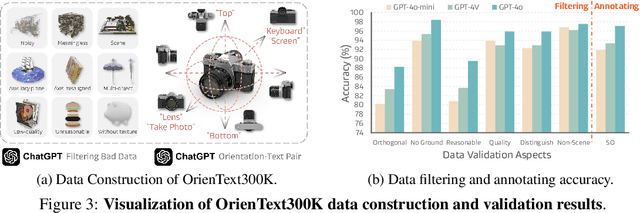
Spatial intelligence is a critical component of embodied AI, promoting robots to understand and interact with their environments. While recent advances have enhanced the ability of VLMs to perceive object locations and positional relationships, they still lack the capability to precisely understand object orientations-a key requirement for tasks involving fine-grained manipulations. Addressing this limitation not only requires geometric reasoning but also an expressive and intuitive way to represent orientation. In this context, we propose that natural language offers a more flexible representation space than canonical frames, making it particularly suitable for instruction-following robotic systems. In this paper, we introduce the concept of semantic orientation, which defines object orientations using natural language in a reference-frame-free manner (e.g., the ''plug-in'' direction of a USB or the ''handle'' direction of a knife). To support this, we construct OrienText300K, a large-scale dataset of 3D models annotated with semantic orientations that link geometric understanding to functional semantics. By integrating semantic orientation into a VLM system, we enable robots to generate manipulation actions with both positional and orientational constraints. Extensive experiments in simulation and real world demonstrate that our approach significantly enhances robotic manipulation capabilities, e.g., 48.7% accuracy on Open6DOR and 74.9% accuracy on SIMPLER.
Accelerating Diffusion Models with One-to-Many Knowledge Distillation
Oct 05, 2024Significant advancements in image generation have been made with diffusion models. Nevertheless, when contrasted with previous generative models, diffusion models face substantial computational overhead, leading to failure in real-time generation. Recent approaches have aimed to accelerate diffusion models by reducing the number of sampling steps through improved sampling techniques or step distillation. However, the methods to diminish the computational cost for each timestep remain a relatively unexplored area. Observing the fact that diffusion models exhibit varying input distributions and feature distributions at different timesteps, we introduce one-to-many knowledge distillation (O2MKD), which distills a single teacher diffusion model into multiple student diffusion models, where each student diffusion model is trained to learn the teacher's knowledge for a subset of continuous timesteps. Experiments on CIFAR10, LSUN Church, CelebA-HQ with DDPM and COCO30K with Stable Diffusion show that O2MKD can be applied to previous knowledge distillation and fast sampling methods to achieve significant acceleration. Codes will be released in Github.
Unique3D: High-Quality and Efficient 3D Mesh Generation from a Single Image
May 30, 2024



In this work, we introduce Unique3D, a novel image-to-3D framework for efficiently generating high-quality 3D meshes from single-view images, featuring state-of-the-art generation fidelity and strong generalizability. Previous methods based on Score Distillation Sampling (SDS) can produce diversified 3D results by distilling 3D knowledge from large 2D diffusion models, but they usually suffer from long per-case optimization time with inconsistent issues. Recent works address the problem and generate better 3D results either by finetuning a multi-view diffusion model or training a fast feed-forward model. However, they still lack intricate textures and complex geometries due to inconsistency and limited generated resolution. To simultaneously achieve high fidelity, consistency, and efficiency in single image-to-3D, we propose a novel framework Unique3D that includes a multi-view diffusion model with a corresponding normal diffusion model to generate multi-view images with their normal maps, a multi-level upscale process to progressively improve the resolution of generated orthographic multi-views, as well as an instant and consistent mesh reconstruction algorithm called ISOMER, which fully integrates the color and geometric priors into mesh results. Extensive experiments demonstrate that our Unique3D significantly outperforms other image-to-3D baselines in terms of geometric and textural details.
Flow Score Distillation for Diverse Text-to-3D Generation
May 16, 2024



Recent advancements in Text-to-3D generation have yielded remarkable progress, particularly through methods that rely on Score Distillation Sampling (SDS). While SDS exhibits the capability to create impressive 3D assets, it is hindered by its inherent maximum-likelihood-seeking essence, resulting in limited diversity in generation outcomes. In this paper, we discover that the Denoise Diffusion Implicit Models (DDIM) generation process (\ie PF-ODE) can be succinctly expressed using an analogue of SDS loss. One step further, one can see SDS as a generalized DDIM generation process. Following this insight, we show that the noise sampling strategy in the noise addition stage significantly restricts the diversity of generation results. To address this limitation, we present an innovative noise sampling approach and introduce a novel text-to-3D method called Flow Score Distillation (FSD). Our validation experiments across various text-to-image Diffusion Models demonstrate that FSD substantially enhances generation diversity without compromising quality.
Orchestrate Latent Expertise: Advancing Online Continual Learning with Multi-Level Supervision and Reverse Self-Distillation
Mar 30, 2024



To accommodate real-world dynamics, artificial intelligence systems need to cope with sequentially arriving content in an online manner. Beyond regular Continual Learning (CL) attempting to address catastrophic forgetting with offline training of each task, Online Continual Learning (OCL) is a more challenging yet realistic setting that performs CL in a one-pass data stream. Current OCL methods primarily rely on memory replay of old training samples. However, a notable gap from CL to OCL stems from the additional overfitting-underfitting dilemma associated with the use of rehearsal buffers: the inadequate learning of new training samples (underfitting) and the repeated learning of a few old training samples (overfitting). To this end, we introduce a novel approach, Multi-level Online Sequential Experts (MOSE), which cultivates the model as stacked sub-experts, integrating multi-level supervision and reverse self-distillation. Supervision signals across multiple stages facilitate appropriate convergence of the new task while gathering various strengths from experts by knowledge distillation mitigates the performance decline of old tasks. MOSE demonstrates remarkable efficacy in learning new samples and preserving past knowledge through multi-level experts, thereby significantly advancing OCL performance over state-of-the-art baselines (e.g., up to 7.3% on Split CIFAR-100 and 6.1% on Split Tiny-ImageNet).
ShapeLLM: Universal 3D Object Understanding for Embodied Interaction
Mar 06, 2024



This paper presents ShapeLLM, the first 3D Multimodal Large Language Model (LLM) designed for embodied interaction, exploring a universal 3D object understanding with 3D point clouds and languages. ShapeLLM is built upon an improved 3D encoder by extending ReCon to ReCon++ that benefits from multi-view image distillation for enhanced geometry understanding. By utilizing ReCon++ as the 3D point cloud input encoder for LLMs, ShapeLLM is trained on constructed instruction-following data and tested on our newly human-curated evaluation benchmark, 3D MM-Vet. ReCon++ and ShapeLLM achieve state-of-the-art performance in 3D geometry understanding and language-unified 3D interaction tasks, such as embodied visual grounding.
DreamLLM: Synergistic Multimodal Comprehension and Creation
Sep 20, 2023This paper presents DreamLLM, a learning framework that first achieves versatile Multimodal Large Language Models (MLLMs) empowered with frequently overlooked synergy between multimodal comprehension and creation. DreamLLM operates on two fundamental principles. The first focuses on the generative modeling of both language and image posteriors by direct sampling in the raw multimodal space. This approach circumvents the limitations and information loss inherent to external feature extractors like CLIP, and a more thorough multimodal understanding is obtained. Second, DreamLLM fosters the generation of raw, interleaved documents, modeling both text and image contents, along with unstructured layouts. This allows DreamLLM to learn all conditional, marginal, and joint multimodal distributions effectively. As a result, DreamLLM is the first MLLM capable of generating free-form interleaved content. Comprehensive experiments highlight DreamLLM's superior performance as a zero-shot multimodal generalist, reaping from the enhanced learning synergy.
VPP: Efficient Conditional 3D Generation via Voxel-Point Progressive Representation
Jul 28, 2023



Conditional 3D generation is undergoing a significant advancement, enabling the free creation of 3D content from inputs such as text or 2D images. However, previous approaches have suffered from low inference efficiency, limited generation categories, and restricted downstream applications. In this work, we revisit the impact of different 3D representations on generation quality and efficiency. We propose a progressive generation method through Voxel-Point Progressive Representation (VPP). VPP leverages structured voxel representation in the proposed Voxel Semantic Generator and the sparsity of unstructured point representation in the Point Upsampler, enabling efficient generation of multi-category objects. VPP can generate high-quality 8K point clouds within 0.2 seconds. Additionally, the masked generation Transformer allows for various 3D downstream tasks, such as generation, editing, completion, and pre-training. Extensive experiments demonstrate that VPP efficiently generates high-fidelity and diverse 3D shapes across different categories, while also exhibiting excellent representation transfer performance. Codes will be released on https://github.com/qizekun/VPP.
Point-GCC: Universal Self-supervised 3D Scene Pre-training via Geometry-Color Contrast
Jun 01, 2023



Geometry and color information provided by the point clouds are both crucial for 3D scene understanding. Two pieces of information characterize the different aspects of point clouds, but existing methods lack an elaborate design for the discrimination and relevance. Hence we explore a 3D self-supervised paradigm that can better utilize the relations of point cloud information. Specifically, we propose a universal 3D scene pre-training framework via Geometry-Color Contrast (Point-GCC), which aligns geometry and color information using a Siamese network. To take care of actual application tasks, we design (i) hierarchical supervision with point-level contrast and reconstruct and object-level contrast based on the novel deep clustering module to close the gap between pre-training and downstream tasks; (ii) architecture-agnostic backbone to adapt for various downstream models. Benefiting from the object-level representation associated with downstream tasks, Point-GCC can directly evaluate model performance and the result demonstrates the effectiveness of our methods. Transfer learning results on a wide range of tasks also show consistent improvements across all datasets. e.g., new state-of-the-art object detection results on SUN RGB-D and S3DIS datasets. Codes will be released at https://github.com/Asterisci/Point-GCC.