 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Composition Diffusion Model for Closed-loop Traffic Generation
Dec 23, 2024Simulation is critical for safety evaluation in autonomous driving, particularly in capturing complex interactive behaviors. However, generating realistic and controllable traffic scenarios in long-tail situations remains a significant challenge. Existing generative models suffer from the conflicting objective between user-defined controllability and realism constraints, which is amplified in safety-critical contexts. In this work, we introduce the Causal Compositional Diffusion Model (CCDiff), a structure-guided diffusion framework to address these challenges. We first formulate the learning of controllable and realistic closed-loop simulation as a constrained optimization problem. Then, CCDiff maximizes controllability while adhering to realism by automatically identifying and injecting causal structures directly into the diffusion process, providing structured guidance to enhance both realism and controllability. Through rigorous evaluations on benchmark datasets and in a closed-loop simulator, CCDiff demonstrates substantial gains over state-of-the-art approaches in generating realistic and user-preferred trajectories. Our results show CCDiff's effectiveness in extracting and leveraging causal structures, showing improved closed-loop performance based on key metrics such as collision rate, off-road rate, FDE, and comfort.
DriveGPT: Scaling Autoregressive Behavior Models for Driving
Dec 19, 2024



We present DriveGPT, a scalable behavior model for autonomous driving. We model driving as a sequential decision making task, and learn a transformer model to predict future agent states as tokens in an autoregressive fashion. We scale up our model parameters and training data by multiple orders of magnitude, enabling us to explore the scaling properties in terms of dataset size, model parameters, and compute. We evaluate DriveGPT across different scales in a planning task, through both quantitative metrics and qualitative examples including closed-loop driving in complex real-world scenarios. In a separate prediction task, DriveGPT outperforms a state-of-the-art baseline and exhibits improved performance by pretraining on a large-scale dataset, further validating the benefits of data scaling.
Cohere3D: Exploiting Temporal Coherence for Unsupervised Representation Learning of Vision-based Autonomous Driving
Feb 23, 2024



Due to the lack of depth cues in images, multi-frame inputs are important for the success of vision-based perception, prediction, and planning in autonomous driving. Observations from different angles enable the recovery of 3D object states from 2D image inputs if we can identify the same instance in different input frames. However, the dynamic nature of autonomous driving scenes leads to significant changes in the appearance and shape of each instance captured by the camera at different time steps. To this end, we propose a novel contrastive learning algorithm, Cohere3D, to learn coherent instance representations in a long-term input sequence robust to the change in distance and perspective. The learned representation aids in instance-level correspondence across multiple input frames in downstream tasks. In the pretraining stage, the raw point clouds from LiDAR sensors are utilized to construct the long-term temporal correspondence for each instance, which serves as guidance for the extraction of instance-level representation from the vision-based bird's eye-view (BEV) feature map. Cohere3D encourages a consistent representation for the same instance at different frames but distinguishes between representations of different instances. We evaluate our algorithm by finetuning the pretrained model on various downstream perception, prediction, and planning tasks. Results show a notable improvement in both data efficiency and task performance.
SHIFT3D: Synthesizing Hard Inputs For Tricking 3D Detectors
Sep 11, 2023



We present SHIFT3D, a differentiable pipeline for generating 3D shapes that are structurally plausible yet challenging to 3D object detectors. In safety-critical applications like autonomous driving, discovering such novel challenging objects can offer insight into unknown vulnerabilities of 3D detectors. By representing objects with a signed distanced function (SDF), we show that gradient error signals allow us to smoothly deform the shape or pose of a 3D object in order to confuse a downstream 3D detector. Importantly, the objects generated by SHIFT3D physically differ from the baseline object yet retain a semantically recognizable shape. Our approach provides interpretable failure modes for modern 3D object detectors, and can aid in preemptive discovery of potential safety risks within 3D perception systems before these risks become critical failures.
Hierarchical Model-Based Imitation Learning for Planning in Autonomous Driving
Oct 18, 2022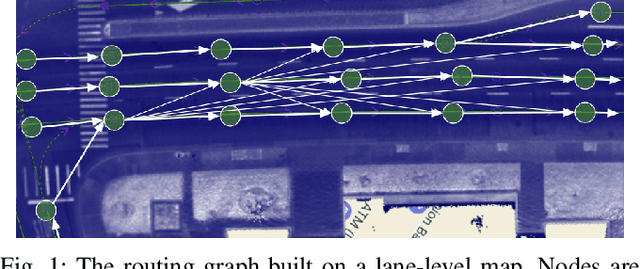
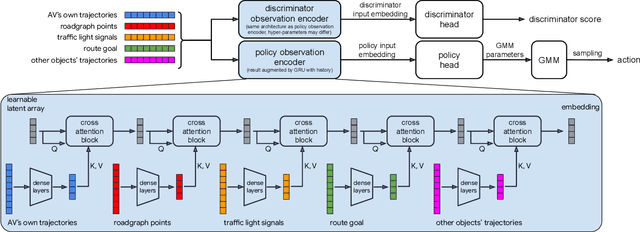
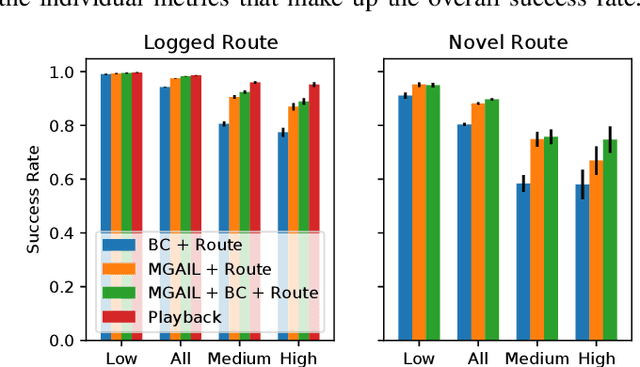
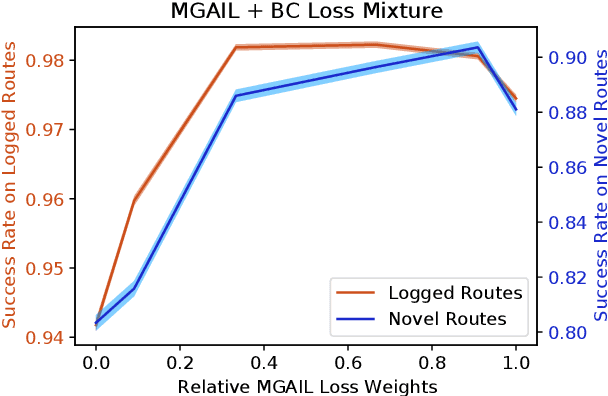
We demonstrate the first large-scale application of model-based generative adversarial imitation learning (MGAIL) to the task of dense urban self-driving. We augment standard MGAIL using a hierarchical model to enable generalization to arbitrary goal routes, and measure performance using a closed-loop evaluation framework with simulated interactive agents. We train policies from expert trajectories collected from real vehicles driving over 100,000 miles in San Francisco, and demonstrate a steerable policy that can navigate robustly even in a zero-shot setting, generalizing to synthetic scenarios with novel goals that never occurred in real-world driving. We also demonstrate the importance of mixing closed-loop MGAIL losses with open-loop behavior cloning losses, and show our best policy approaches the performance of the expert. We evaluate our imitative model in both average and challenging scenarios, and show how it can serve as a useful prior to plan successful trajectories.
Robust Reinforcement Learning on State Observations with Learned Optimal Adversary
Jan 21, 2021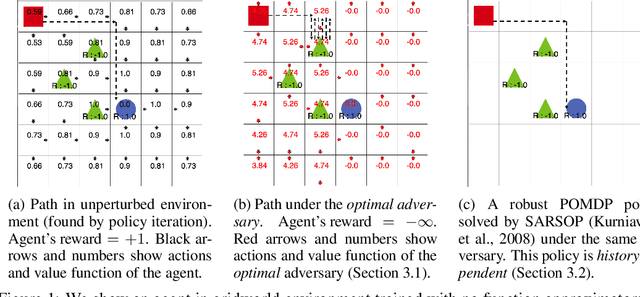
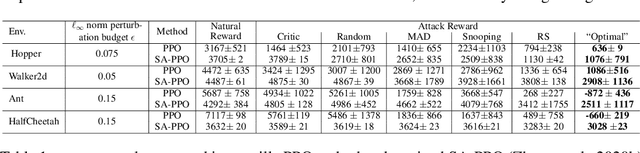
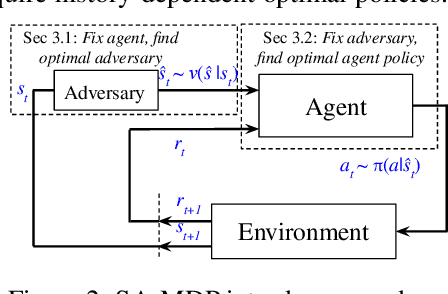
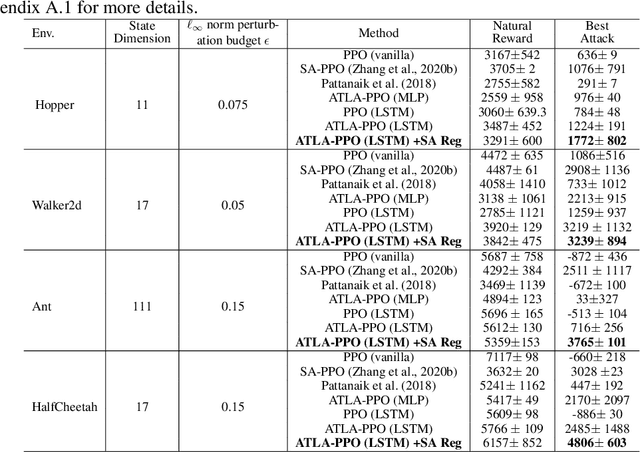
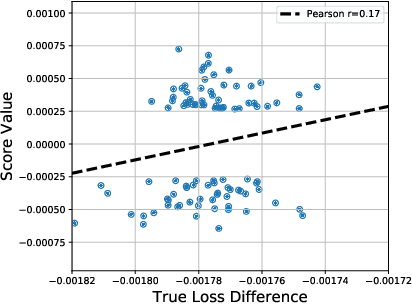
We study the robustness of reinforcement learning (RL) with adversarially perturbed state observations, which aligns with the setting of many adversarial attacks to deep reinforcement learning (DRL) and is also important for rolling out real-world RL agent under unpredictable sensing noise. With a fixed agent policy, we demonstrate that an optimal adversary to perturb state observations can be found, which is guaranteed to obtain the worst case agent reward. For DRL settings, this leads to a novel empirical adversarial attack to RL agents via a learned adversary that is much stronger than previous ones. To enhance the robustness of an agent, we propose a framework of alternating training with learned adversaries (ATLA), which trains an adversary online together with the agent using policy gradient following the optimal adversarial attack framework. Additionally, inspired by the analysis of state-adversarial Markov decision process (SA-MDP), we show that past states and actions (history) can be useful for learning a robust agent, and we empirically find a LSTM based policy can be more robust under adversaries. Empirical evaluations on a few continuous control environments show that ATLA achieves state-of-the-art performance under strong adversaries. Our code is available at https://github.com/huanzhang12/ATLA_robust_RL.
On $\ell_p$-norm Robustness of Ensemble Stumps and Trees
Sep 29, 2020

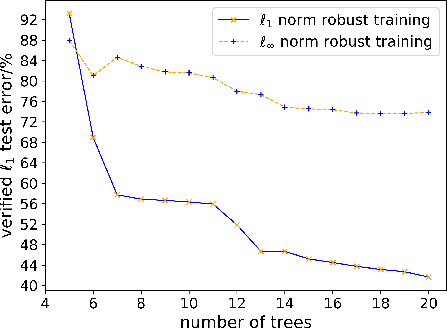
Recent papers have demonstrated that ensemble stumps and trees could be vulnerable to small input perturbations, so robustness verification and defense for those models have become an important research problem. However, due to the structure of decision trees, where each node makes decision purely based on one feature value, all the previous works only consider the $\ell_\infty$ norm perturbation. To study robustness with respect to a general $\ell_p$ norm perturbation, one has to consider the correlation between perturbations on different features, which has not been handled by previous algorithms. In this paper, we study the problem of robustness verification and certified defense with respect to general $\ell_p$ norm perturbations for ensemble decision stumps and trees. For robustness verification of ensemble stumps, we prove that complete verification is NP-complete for $p\in(0, \infty)$ while polynomial time algorithms exist for $p=0$ or $\infty$. For $p\in(0, \infty)$ we develop an efficient dynamic programming based algorithm for sound verification of ensemble stumps. For ensemble trees, we generalize the previous multi-level robustness verification algorithm to $\ell_p$ norm. We demonstrate the first certified defense method for training ensemble stumps and trees with respect to $\ell_p$ norm perturbations, and verify its effectiveness empirically on real datasets.
Multi-Stage Influence Function
Jul 17, 2020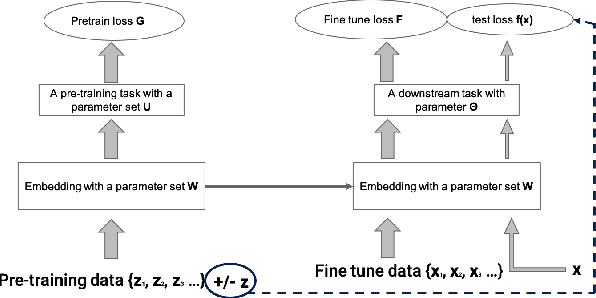
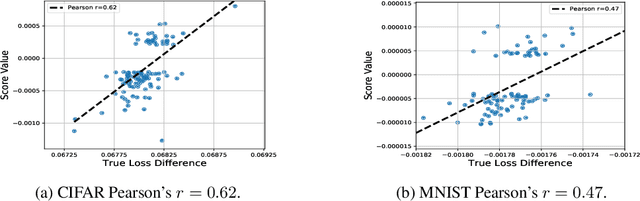

Multi-stage training and knowledge transfer, from a large-scale pretraining task to various finetuning tasks, have revolutionized natural language processing and computer vision resulting in state-of-the-art performance improvements. In this paper, we develop a multi-stage influence function score to track predictions from a finetuned model all the way back to the pretraining data. With this score, we can identify the pretraining examples in the pretraining task that contribute most to a prediction in the finetuning task. The proposed multi-stage influence function generalizes the original influence function for a single model in (Koh & Liang, 2017), thereby enabling influence computation through both pretrained and finetuned models. We study two different scenarios with the pretrained embeddings fixed or updated in the finetuning tasks. We test our proposed method in various experiments to show its effectiveness and potential applications.
Robust Deep Reinforcement Learning against Adversarial Perturbations on Observations
Mar 19, 2020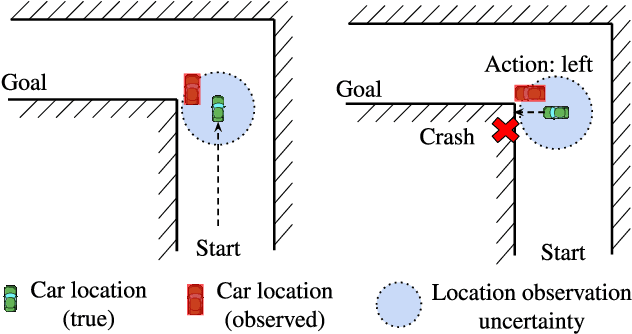

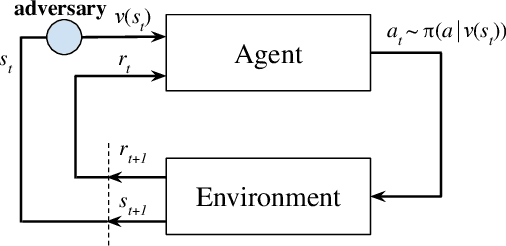
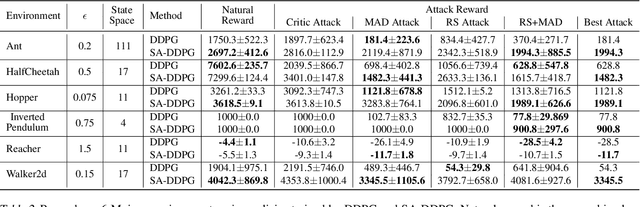
Deep Reinforcement Learning (DRL) is vulnerable to small adversarial perturbations on state observations. These perturbations do not alter the environment directly but can mislead the agent into making suboptimal decisions. We analyze the Markov Decision Process (MDP) under this threat model and utilize tools from the neural net-work verification literature to enable robust train-ing for DRL under observational perturbations. Our techniques are general and can be applied to both Deep Q Networks (DQN) and Deep Deterministic Policy Gradient (DDPG) algorithms for discrete and continuous action control problems. We demonstrate that our proposed training procedure significantly improves the robustness of DQN and DDPG agents under a suite of strong white-box attacks on observations, including a few novel attacks we specifically craft. Additionally, our training procedure can produce provable certificates for the robustness of a Deep RL agent.
Adversarial T-shirt! Evading Person Detectors in A Physical World
Nov 27, 2019It is known that deep neural networks (DNNs) are vulnerable to adversarial attacks. The so-called physical adversarial examples deceive DNN-based decision makers by attaching adversarial patches to real objects. However, most of the existing works on physical adversarial attacks focus on static objects such as glass frames, stop signs and images attached to cardboard. In this work, we propose Adversarial T-shirts, a robust physical adversarial example for evading person detectors even if it could undergo non-rigid deformation due to a moving person's pose changes. To the best of our knowledge, this is the first work that models the effect of deformation for designing physical adversarial examples with respect to non-rigid objects such as T-shirts. We show that the proposed method achieves 74% and 57% attack success rates in digital and physical worlds respectively against YOLOv2. In contrast, the state-of-the-art physical attack method to fool a person detector only achieves 18% attack success rate. Furthermore, by leveraging min-max optimization, we extend our method to the ensemble attack setting against two object detectors YOLO-v2 and Faster R-CNN simultaneously.