 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFieldGen: From Teleoperated Pre-Manipulation Trajectories to Field-Guided Data Generation
Oct 23, 2025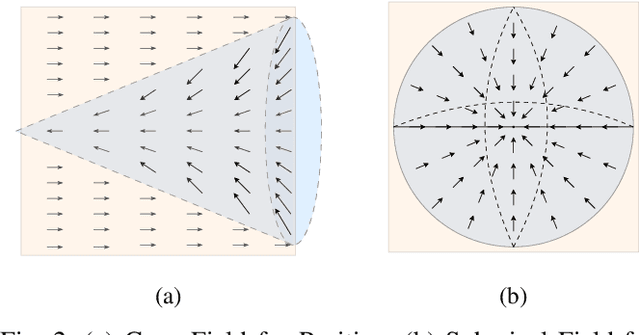

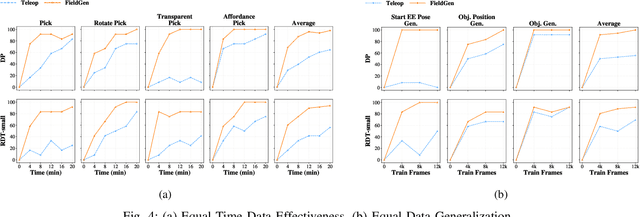

Large-scale and diverse datasets are vital for training robust robotic manipulation policies, yet existing data collection methods struggle to balance scale, diversity, and quality. Simulation offers scalability but suffers from sim-to-real gaps, while teleoperation yields high-quality demonstrations with limited diversity and high labor cost. We introduce FieldGen, a field-guided data generation framework that enables scalable, diverse, and high-quality real-world data collection with minimal human supervision. FieldGen decomposes manipulation into two stages: a pre-manipulation phase, allowing trajectory diversity, and a fine manipulation phase requiring expert precision. Human demonstrations capture key contact and pose information, after which an attraction field automatically generates diverse trajectories converging to successful configurations. This decoupled design combines scalable trajectory diversity with precise supervision. Moreover, FieldGen-Reward augments generated data with reward annotations to further enhance policy learning. Experiments demonstrate that policies trained with FieldGen achieve higher success rates and improved stability compared to teleoperation-based baselines, while significantly reducing human effort in long-term real-world data collection. Webpage is available at https://fieldgen.github.io/.
Efficient Autoregressive Inference for Transformer Probabilistic Models
Oct 10, 2025



Transformer-based models for amortized probabilistic inference, such as neural processes, prior-fitted networks, and tabular foundation models, excel at single-pass marginal prediction. However, many real-world applications, from signal interpolation to multi-column tabular predictions, require coherent joint distributions that capture dependencies between predictions. While purely autoregressive architectures efficiently generate such distributions, they sacrifice the flexible set-conditioning that makes these models powerful for meta-learning. Conversely, the standard approach to obtain joint distributions from set-based models requires expensive re-encoding of the entire augmented conditioning set at each autoregressive step. We introduce a causal autoregressive buffer that preserves the advantages of both paradigms. Our approach decouples context encoding from updating the conditioning set. The model processes the context once and caches it. A dynamic buffer then captures target dependencies: as targets are incorporated, they enter the buffer and attend to both the cached context and previously buffered targets. This enables efficient batched autoregressive generation and one-pass joint log-likelihood evaluation. A unified training strategy allows seamless integration of set-based and autoregressive modes at minimal additional cost. Across synthetic functions, EEG signals, cognitive models, and tabular data, our method matches predictive accuracy of strong baselines while delivering up to 20 times faster joint sampling. Our approach combines the efficiency of autoregressive generative models with the representational power of set-based conditioning, making joint prediction practical for transformer-based probabilistic models.
Noise or Signal? Deconstructing Contradictions and An Adaptive Remedy for Reversible Normalization in Time Series Forecasting
Oct 06, 2025



Reversible Instance Normalization (RevIN) is a key technique enabling simple linear models to achieve state-of-the-art performance in time series forecasting. While replacing its non-robust statistics with robust counterparts (termed R$^2$-IN) seems like a straightforward improvement, our findings reveal a far more complex reality. This paper deconstructs the perplexing performance of various normalization strategies by identifying four underlying theoretical contradictions. Our experiments provide two crucial findings: first, the standard RevIN catastrophically fails on datasets with extreme outliers, where its MSE surges by a staggering 683\%. Second, while the simple R$^2$-IN prevents this failure and unexpectedly emerges as the best overall performer, our adaptive model (A-IN), designed to test a diagnostics-driven heuristic, unexpectedly suffers a complete and systemic failure. This surprising outcome uncovers a critical, overlooked pitfall in time series analysis: the instability introduced by a simple or counter-intuitive heuristic can be more damaging than the statistical issues it aims to solve. The core contribution of this work is thus a new, cautionary paradigm for time series normalization: a shift from a blind search for complexity to a diagnostics-driven analysis that reveals not only the surprising power of simple baselines but also the perilous nature of naive adaptation.
GeoPurify: A Data-Efficient Geometric Distillation Framework for Open-Vocabulary 3D Segmentation
Oct 02, 2025



Recent attempts to transfer features from 2D Vision-Language Models (VLMs) to 3D semantic segmentation expose a persistent trade-off. Directly projecting 2D features into 3D yields noisy and fragmented predictions, whereas enforcing geometric coherence necessitates costly training pipelines and large-scale annotated 3D data. We argue that this limitation stems from the dominant segmentation-and-matching paradigm, which fails to reconcile 2D semantics with 3D geometric structure. The geometric cues are not eliminated during the 2D-to-3D transfer but remain latent within the noisy and view-aggregated features. To exploit this property, we propose GeoPurify that applies a small Student Affinity Network to purify 2D VLM-generated 3D point features using geometric priors distilled from a 3D self-supervised teacher model. During inference, we devise a Geometry-Guided Pooling module to further denoise the point cloud and ensure the semantic and structural consistency. Benefiting from latent geometric information and the learned affinity network, GeoPurify effectively mitigates the trade-off and achieves superior data efficiency. Extensive experiments on major 3D benchmarks demonstrate that GeoPurify achieves or surpasses state-of-the-art performance while utilizing only about 1.5% of the training data. Our codes and checkpoints are available at [https://github.com/tj12323/GeoPurify](https://github.com/tj12323/GeoPurify).
More Than One Teacher: Adaptive Multi-Guidance Policy Optimization for Diverse Exploration
Oct 02, 2025



Reinforcement Learning with Verifiable Rewards (RLVR) is a promising paradigm for enhancing the reasoning ability in Large Language Models (LLMs). However, prevailing methods primarily rely on self-exploration or a single off-policy teacher to elicit long chain-of-thought (LongCoT) reasoning, which may introduce intrinsic model biases and restrict exploration, ultimately limiting reasoning diversity and performance. Drawing inspiration from multi-teacher strategies in knowledge distillation, we introduce Adaptive Multi-Guidance Policy Optimization (AMPO), a novel framework that adaptively leverages guidance from multiple proficient teacher models, but only when the on-policy model fails to generate correct solutions. This "guidance-on-demand" approach expands exploration while preserving the value of self-discovery. Moreover, AMPO incorporates a comprehension-based selection mechanism, prompting the student to learn from the reasoning paths that it is most likely to comprehend, thus balancing broad exploration with effective exploitation. Extensive experiments show AMPO substantially outperforms a strong baseline (GRPO), with a 4.3% improvement on mathematical reasoning tasks and 12.2% on out-of-distribution tasks, while significantly boosting Pass@k performance and enabling more diverse exploration. Notably, using four peer-sized teachers, our method achieves comparable results to approaches that leverage a single, more powerful teacher (e.g., DeepSeek-R1) with more data. These results demonstrate a more efficient and scalable path to superior reasoning and generalizability. Our code is available at https://github.com/SII-Enigma/AMPO.
MARS2 2025 Challenge on Multimodal Reasoning: Datasets, Methods, Results, Discussion, and Outlook
Sep 17, 2025



This paper reviews the MARS2 2025 Challenge on Multimodal Reasoning. We aim to bring together different approaches in multimodal machine learning and LLMs via a large benchmark. We hope it better allows researchers to follow the state-of-the-art in this very dynamic area. Meanwhile, a growing number of testbeds have boosted the evolution of general-purpose large language models. Thus, this year's MARS2 focuses on real-world and specialized scenarios to broaden the multimodal reasoning applications of MLLMs. Our organizing team released two tailored datasets Lens and AdsQA as test sets, which support general reasoning in 12 daily scenarios and domain-specific reasoning in advertisement videos, respectively. We evaluated 40+ baselines that include both generalist MLLMs and task-specific models, and opened up three competition tracks, i.e., Visual Grounding in Real-world Scenarios (VG-RS), Visual Question Answering with Spatial Awareness (VQA-SA), and Visual Reasoning in Creative Advertisement Videos (VR-Ads). Finally, 76 teams from the renowned academic and industrial institutions have registered and 40+ valid submissions (out of 1200+) have been included in our ranking lists. Our datasets, code sets (40+ baselines and 15+ participants' methods), and rankings are publicly available on the MARS2 workshop website and our GitHub organization page https://github.com/mars2workshop/, where our updates and announcements of upcoming events will be continuously provided.
DATE: Dynamic Absolute Time Enhancement for Long Video Understanding
Sep 11, 2025Long video understanding remains a fundamental challenge for multimodal large language models (MLLMs), particularly in tasks requiring precise temporal reasoning and event localization. Existing approaches typically adopt uniform frame sampling and rely on implicit position encodings to model temporal order. However, these methods struggle with long-range dependencies, leading to critical information loss and degraded temporal comprehension. In this paper, we propose Dynamic Absolute Time Enhancement (DATE) that enhances temporal awareness in MLLMs through the Timestamp Injection Mechanism (TIM) and a semantically guided Temporal-Aware Similarity Sampling (TASS) strategy. Specifically, we interleave video frame embeddings with textual timestamp tokens to construct a continuous temporal reference system. We further reformulate the video sampling problem as a vision-language retrieval task and introduce a two-stage algorithm to ensure both semantic relevance and temporal coverage: enriching each query into a descriptive caption to better align with the vision feature, and sampling key event with a similarity-driven temporally regularized greedy strategy. Our method achieves remarkable improvements w.r.t. absolute time understanding and key event localization, resulting in state-of-the-art performance among 7B and 72B models on hour-long video benchmarks. Particularly, our 7B model even exceeds many 72B models on some benchmarks.
Zero-shot Hierarchical Plant Segmentation via Foundation Segmentation Models and Text-to-image Attention
Sep 11, 2025Foundation segmentation models achieve reasonable leaf instance extraction from top-view crop images without training (i.e., zero-shot). However, segmenting entire plant individuals with each consisting of multiple overlapping leaves remains challenging. This problem is referred to as a hierarchical segmentation task, typically requiring annotated training datasets, which are often species-specific and require notable human labor. To address this, we introduce ZeroPlantSeg, a zero-shot segmentation for rosette-shaped plant individuals from top-view images. We integrate a foundation segmentation model, extracting leaf instances, and a vision-language model, reasoning about plants' structures to extract plant individuals without additional training. Evaluations on datasets with multiple plant species, growth stages, and shooting environments demonstrate that our method surpasses existing zero-shot methods and achieves better cross-domain performance than supervised methods. Implementations are available at https://github.com/JunhaoXing/ZeroPlantSeg.
SCoder: Iterative Self-Distillation for Bootstrapping Small-Scale Data Synthesizers to Empower Code LLMs
Sep 09, 2025



Existing code large language models (LLMs) often rely on large-scale instruction data distilled from proprietary LLMs for fine-tuning, which typically incurs high costs. In this paper, we explore the potential of small-scale open-source LLMs (e.g., 7B) as synthesizers for high-quality code instruction data construction. We first observe that the data synthesis capability of small-scale LLMs can be enhanced by training on a few superior data synthesis samples from proprietary LLMs. Building on this, we propose a novel iterative self-distillation approach to bootstrap small-scale LLMs, transforming them into powerful synthesizers that reduce reliance on proprietary LLMs and minimize costs. Concretely, in each iteration, to obtain diverse and high-quality self-distilled data, we design multi-checkpoint sampling and multi-aspect scoring strategies for initial data selection. Furthermore, to identify the most influential samples, we introduce a gradient-based influence estimation method for final data filtering. Based on the code instruction datasets from the small-scale synthesizers, we develop SCoder, a family of code generation models fine-tuned from DeepSeek-Coder. SCoder models achieve state-of-the-art code generation capabilities, demonstrating the effectiveness of our method.
What Can We Learn from Harry Potter? An Exploratory Study of Visual Representation Learning from Atypical Videos
Aug 29, 2025



Humans usually show exceptional generalisation and discovery ability in the open world, when being shown uncommon new concepts. Whereas most existing studies in the literature focus on common typical data from closed sets, open-world novel discovery is under-explored in videos. In this paper, we are interested in asking: \textit{What if atypical unusual videos are exposed in the learning process?} To this end, we collect a new video dataset consisting of various types of unusual atypical data (\eg sci-fi, animation, \etc). To study how such atypical data may benefit open-world learning, we feed them into the model training process for representation learning. Focusing on three key tasks in open-world learning: out-of-distribution (OOD) detection, novel category discovery (NCD), and zero-shot action recognition (ZSAR), we found that even straightforward learning approaches with atypical data consistently improve performance across various settings. Furthermore, we found that increasing the categorical diversity of the atypical samples further boosts OOD detection performance. Additionally, in the NCD task, using a smaller yet more semantically diverse set of atypical samples leads to better performance compared to using a larger but more typical dataset. In the ZSAR setting, the semantic diversity of atypical videos helps the model generalise better to unseen action classes. These observations in our extensive experimental evaluations reveal the benefits of atypical videos for visual representation learning in the open world, together with the newly proposed dataset, encouraging further studies in this direction.