 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFieldGen: From Teleoperated Pre-Manipulation Trajectories to Field-Guided Data Generation
Oct 23, 2025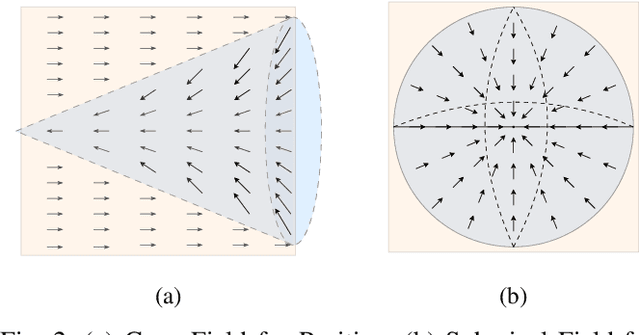

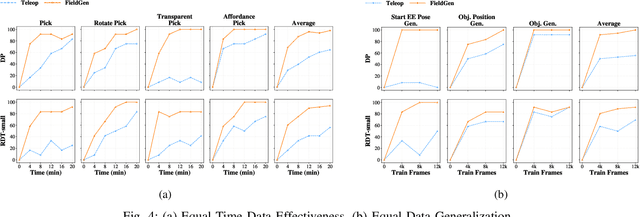

Large-scale and diverse datasets are vital for training robust robotic manipulation policies, yet existing data collection methods struggle to balance scale, diversity, and quality. Simulation offers scalability but suffers from sim-to-real gaps, while teleoperation yields high-quality demonstrations with limited diversity and high labor cost. We introduce FieldGen, a field-guided data generation framework that enables scalable, diverse, and high-quality real-world data collection with minimal human supervision. FieldGen decomposes manipulation into two stages: a pre-manipulation phase, allowing trajectory diversity, and a fine manipulation phase requiring expert precision. Human demonstrations capture key contact and pose information, after which an attraction field automatically generates diverse trajectories converging to successful configurations. This decoupled design combines scalable trajectory diversity with precise supervision. Moreover, FieldGen-Reward augments generated data with reward annotations to further enhance policy learning. Experiments demonstrate that policies trained with FieldGen achieve higher success rates and improved stability compared to teleoperation-based baselines, while significantly reducing human effort in long-term real-world data collection. Webpage is available at https://fieldgen.github.io/.
LAIP: Learning Local Alignment from Image-Phrase Modeling for Text-based Person Search
Jun 16, 2024Text-based person search aims at retrieving images of a particular person based on a given textual description. A common solution for this task is to directly match the entire images and texts, i.e., global alignment, which fails to deal with discerning specific details that discriminate against appearance-similar people. As a result, some works shift their attention towards local alignment. One group matches fine-grained parts using forward attention weights of the transformer yet underutilizes information. Another implicitly conducts local alignment by reconstructing masked parts based on unmasked context yet with a biased masking strategy. All limit performance improvement. This paper proposes the Local Alignment from Image-Phrase modeling (LAIP) framework, with Bidirectional Attention-weighted local alignment (BidirAtt) and Mask Phrase Modeling (MPM) module.BidirAtt goes beyond the typical forward attention by considering the gradient of the transformer as backward attention, utilizing two-sided information for local alignment. MPM focuses on mask reconstruction within the noun phrase rather than the entire text, ensuring an unbiased masking strategy. Extensive experiments conducted on the CUHK-PEDES, ICFG-PEDES, and RSTPReid datasets demonstrate the superiority of the LAIP framework over existing methods.