 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDP-SfM: Dual-Pixel Structure-from-Motion without Scale Ambiguity
May 03, 2026Multi-view 3D reconstruction, namely, structure-from-motion followed by multi-view stereo, is a fundamental component of 3D computer vision. In general, multi-view 3D reconstruction suffers from an unknown scale ambiguity unless a reference object of known size is present in the scene. In this article, we show that multi-view images captured using a dual-pixel (DP) sensor can automatically resolve the scale ambiguity, without requiring a reference object or prior calibration. Specifically, the defocus blur observed in DP images provides sufficient information to determine the absolute scale when paired with depth maps (up to scale) recovered from multi-view 3D reconstruction. Based on this observation, we develop a simple yet effective linear method to estimate the absolute scale, followed by the intensity-based optimization stage that aligns the left and right DP images by shifting them back toward each other using cross-view blur kernels. Experiments demonstrate the effectiveness of the proposed approach across diverse scenes captured with different cameras and lenses. Code and data are available at https://github.com/lilika-makabe/dp-sfm-tpami.git
NRGS: Neural Regularization for Robust 3D Semantic Gaussian Splatting
Apr 24, 2026We propose a neural regularization method that refines the noisy 3D semantic field produced by lifting multi-view inconsistent 2D features, in order to obtain an accurate and robust 3D semantic Gaussian Splatting. The 2D features extracted from vision foundation models suffer from multi-view inconsistency due to a lack of cross-view constraints. Lifting these inconsistent features directly into 3D Gaussians results in a noisy semantic field, which degrades the performance of downstream tasks. Previous methods either focus on obtaining consistent multi-view features in the preprocessing stage or aim to mitigate noise through improved optimization strategies, often at the cost of increased preprocessing time or expensive computational overhead. In contrast, we introduce a variance-aware conditional MLP that operates directly on the 3D Gaussians, leveraging their geometric and appearance attributes to correct semantic errors in 3D space. Experiments on different datasets show that our method enhances the accuracy of lifted semantics, providing an efficient and effective approach to robust 3D semantic Gaussian Splatting.
BioVITA: Biological Dataset, Model, and Benchmark for Visual-Textual-Acoustic Alignment
Mar 25, 2026Understanding animal species from multimodal data poses an emerging challenge at the intersection of computer vision and ecology. While recent biological models, such as BioCLIP, have demonstrated strong alignment between images and textual taxonomic information for species identification, the integration of the audio modality remains an open problem. We propose BioVITA, a novel visual-textual-acoustic alignment framework for biological applications. BioVITA involves (i) a training dataset, (ii) a representation model, and (iii) a retrieval benchmark. First, we construct a large-scale training dataset comprising 1.3 million audio clips and 2.3 million images, covering 14,133 species annotated with 34 ecological trait labels. Second, building upon BioCLIP2, we introduce a two-stage training framework to effectively align audio representations with visual and textual representations. Third, we develop a cross-modal retrieval benchmark that covers all possible directional retrieval across the three modalities (i.e., image-to-audio, audio-to-text, text-to-image, and their reverse directions), with three taxonomic levels: Family, Genus, and Species. Extensive experiments demonstrate that our model learns a unified representation space that captures species-level semantics beyond taxonomy, advancing multimodal biodiversity understanding. The project page is available at: https://dahlian00.github.io/BioVITA_Page/
AnimalCLAP: Taxonomy-Aware Language-Audio Pretraining for Species Recognition and Trait Inference
Mar 23, 2026Animal vocalizations provide crucial insights for wildlife assessment, particularly in complex environments such as forests, aiding species identification and ecological monitoring. Recent advances in deep learning have enabled automatic species classification from their vocalizations. However, classifying species unseen during training remains challenging. To address this limitation, we introduce AnimalCLAP, a taxonomy-aware language-audio framework comprising a new dataset and model that incorporate hierarchical biological information. Specifically, our vocalization dataset consists of 4,225 hours of recordings covering 6,823 species, annotated with 22 ecological traits. The AnimalCLAP model is trained on this dataset to align audio and textual representations using taxonomic structures, improving the recognition of unseen species. We demonstrate that our proposed model effectively infers ecological and biological attributes of species directly from their vocalizations, achieving superior performance compared to CLAP. Our dataset, code, and models will be publicly available at https://dahlian00.github.io/AnimalCLAP_Page/.
High-fidelity Multi-view Normal Integration with Scale-encoded Neural Surface Representation
Mar 20, 2026Previous multi-view normal integration methods typically sample a single ray per pixel, without considering the spatial area covered by each pixel, which varies with camera intrinsics and the camera-to-object distance. Consequently, when the target object is captured at different distances, the normals at corresponding pixels may differ across views. This multi-view surface normal inconsistency results in the blurring of high-frequency details in the reconstructed surface. To address this issue, we propose a scale-encoded neural surface representation that incorporates the pixel coverage area into the neural representation. By associating each 3D point with a spatial scale and calculating its normal from a hybrid grid-based encoding, our method effectively represents multi-scale surface normals captured at varying distances. Furthermore, to enable scale-aware surface reconstruction, we introduce a mesh extraction module that assigns an optimal local scale to each vertex based on the training observations. Experimental results demonstrate that our approach consistently yields high-fidelity surface reconstruction from normals observed at varying distances, outperforming existing multi-view normal integration methods.
Near-light Photometric Stereo with Symmetric Lights
Mar 17, 2026This paper describes a linear solution method for near-light photometric stereo by exploiting symmetric light source arrangements. Unlike conventional non-convex optimization approaches, by arranging multiple sets of symmetric nearby light source pairs, our method derives a closed-form solution for surface normal and depth without requiring initialization. In addition, our method works as long as the light sources are symmetrically distributed about an arbitrary point even when the entire spatial offset is uncalibrated. Experiments showcase the accuracy of shape recovery accuracy of our method, achieving comparable results to the state-of-the-art calibrated near-light photometric stereo method while significantly reducing requirements of careful depth initialization and light calibration.
HalDec-Bench: Benchmarking Hallucination Detector in Image Captioning
Mar 16, 2026Hallucination detection in captions (HalDec) assesses a vision-language model's ability to correctly align image content with text by identifying errors in captions that misrepresent the image. Beyond evaluation, effective hallucination detection is also essential for curating high-quality image-caption pairs used to train VLMs. However, the generalizability of VLMs as hallucination detectors across different captioning models and hallucination types remains unclear due to the lack of a comprehensive benchmark. In this work, we introduce HalDec-Bench, a benchmark designed to evaluate hallucination detectors in a principled and interpretable manner. HalDec-Bench contains captions generated by diverse VLMs together with human annotations indicating the presence of hallucinations, detailed hallucination-type categories, and segment-level labels. The benchmark provides tasks with a wide range of difficulty levels and reveals performance differences across models that are not visible in existing multimodal reasoning or alignment benchmarks. Our analysis further uncovers two key findings. First, detectors tend to recognize sentences appearing at the beginning of a response as correct, regardless of their actual correctness. Second, our experiments suggest that dataset noise can be substantially reduced by using strong VLMs as filters while employing recent VLMs as caption generators. Our project page is available at https://dahlian00.github.io/HalDec-Bench-Page/.
Gaussian Mesh Renderer for Lightweight Differentiable Rendering
Feb 16, 20263D Gaussian Splatting (3DGS) has enabled high-fidelity virtualization with fast rendering and optimization for novel view synthesis. On the other hand, triangle mesh models still remain a popular choice for surface reconstruction but suffer from slow or heavy optimization in traditional mesh-based differentiable renderers. To address this problem, we propose a new lightweight differentiable mesh renderer leveraging the efficient rasterization process of 3DGS, named Gaussian Mesh Renderer (GMR), which tightly integrates the Gaussian and mesh representations. Each Gaussian primitive is analytically derived from the corresponding mesh triangle, preserving structural fidelity and enabling the gradient flow. Compared to the traditional mesh renderers, our method achieves smoother gradients, which especially contributes to better optimization using smaller batch sizes with limited memory. Our implementation is available in the public GitHub repository at https://github.com/huntorochi/Gaussian-Mesh-Renderer.
Interaction-via-Actions: Cattle Interaction Detection with Joint Learning of Action-Interaction Latent Space
Dec 18, 2025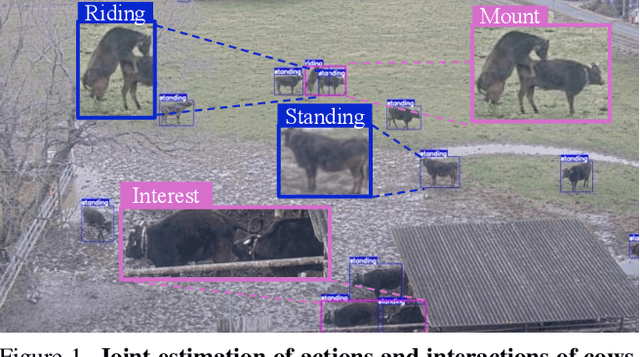
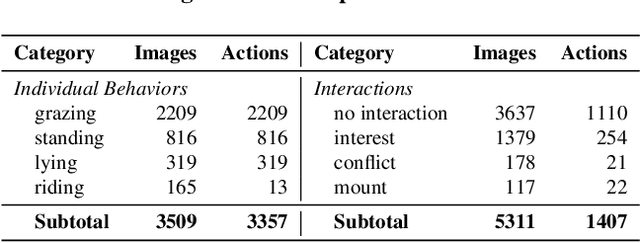
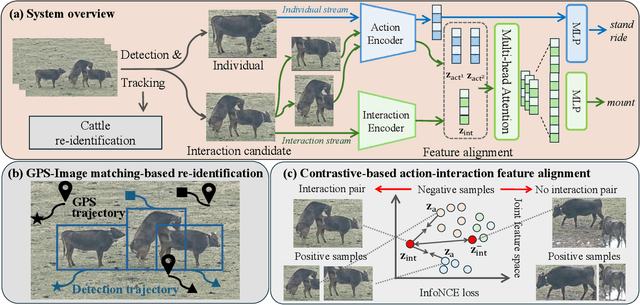
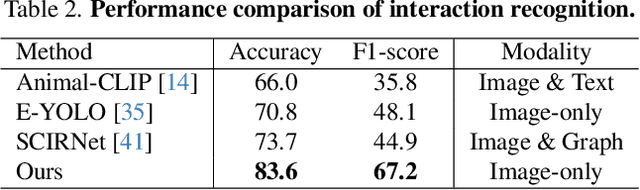
This paper introduces a method and application for automatically detecting behavioral interactions between grazing cattle from a single image, which is essential for smart livestock management in the cattle industry, such as for detecting estrus. Although interaction detection for humans has been actively studied, a non-trivial challenge lies in cattle interaction detection, specifically the lack of a comprehensive behavioral dataset that includes interactions, as the interactions of grazing cattle are rare events. We, therefore, propose CattleAct, a data-efficient method for interaction detection by decomposing interactions into the combinations of actions by individual cattle. Specifically, we first learn an action latent space from a large-scale cattle action dataset. Then, we embed rare interactions via the fine-tuning of the pre-trained latent space using contrastive learning, thereby constructing a unified latent space of actions and interactions. On top of the proposed method, we develop a practical working system integrating video and GPS inputs. Experiments on a commercial-scale pasture demonstrate the accurate interaction detection achieved by our method compared to the baselines. Our implementation is available at https://github.com/rakawanegan/CattleAct.
GaussianPlant: Structure-aligned Gaussian Splatting for 3D Reconstruction of Plants
Dec 16, 2025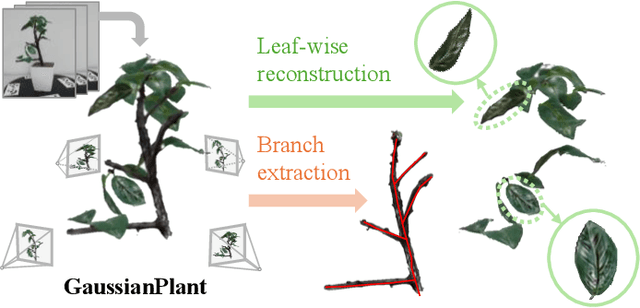



We present a method for jointly recovering the appearance and internal structure of botanical plants from multi-view images based on 3D Gaussian Splatting (3DGS). While 3DGS exhibits robust reconstruction of scene appearance for novel-view synthesis, it lacks structural representations underlying those appearances (e.g., branching patterns of plants), which limits its applicability to tasks such as plant phenotyping. To achieve both high-fidelity appearance and structural reconstruction, we introduce GaussianPlant, a hierarchical 3DGS representation, which disentangles structure and appearance. Specifically, we employ structure primitives (StPs) to explicitly represent branch and leaf geometry, and appearance primitives (ApPs) to the plants' appearance using 3D Gaussians. StPs represent a simplified structure of the plant, i.e., modeling branches as cylinders and leaves as disks. To accurately distinguish the branches and leaves, StP's attributes (i.e., branches or leaves) are optimized in a self-organized manner. ApPs are bound to each StP to represent the appearance of branches or leaves as in conventional 3DGS. StPs and ApPs are jointly optimized using a re-rendering loss on the input multi-view images, as well as the gradient flow from ApP to StP using the binding correspondence information. We conduct experiments to qualitatively evaluate the reconstruction accuracy of both appearance and structure, as well as real-world experiments to qualitatively validate the practical performance. Experiments show that the GaussianPlant achieves both high-fidelity appearance reconstruction via ApPs and accurate structural reconstruction via StPs, enabling the extraction of branch structure and leaf instances.