 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePruneTIR: Inference-Time Tool Call Pruning for Effective yet Efficient Tool-Integrated Reasoning
May 11, 2026Tool-integrated reasoning (TIR) enables large language models (LLMs) to enhance their capabilities by interacting with external tools, such as code interpreters (CI). Most recent studies focus on exploring various methods to equip LLMs with the ability to use tools. However, how to further boost the reasoning ability of already tool-capable LLMs at inference time remains underexplored. Improving reasoning at inference time requires no additional training and can help LLMs better leverage tools to solve problems. We observe that, during tool-capable LLM inference, both the number and the proportion of erroneous tool calls are negatively correlated with answer correctness. Moreover, erroneous tool calls are typically resolved successfully within a few subsequent turns. If not, LLMs often struggle to resolve such errors even with many additional turns. Building on the above observations, we propose PruneTIR, a rather effective yet efficient framework that enhances the tool-integrated reasoning at inference time. During LLM inference, PruneTIR prunes trajectories, resamples tool calls, and suspends tool usage through three components: Success-Triggered Pruning, Stuck-Triggered Pruning and Resampling, and Retry-Triggered Tool Suspension. These three components enable PruneTIR to mitigate the negative impact of erroneous tool calls and prevent LLMs from getting stuck in repeated failed resolution attempts, thereby improving overall LLM performance. Extensive experimental results demonstrate the effectiveness of PruneTIR, which significantly improves Pass@1 and efficiency while reducing the working context length for tool-capable LLMs.
Terminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces
Jan 17, 2026AI agents may soon become capable of autonomously completing valuable, long-horizon tasks in diverse domains. Current benchmarks either do not measure real-world tasks, or are not sufficiently difficult to meaningfully measure frontier models. To this end, we present Terminal-Bench 2.0: a carefully curated hard benchmark composed of 89 tasks in computer terminal environments inspired by problems from real workflows. Each task features a unique environment, human-written solution, and comprehensive tests for verification. We show that frontier models and agents score less than 65\% on the benchmark and conduct an error analysis to identify areas for model and agent improvement. We publish the dataset and evaluation harness to assist developers and researchers in future work at https://www.tbench.ai/ .
ActiShade: Activating Overshadowed Knowledge to Guide Multi-Hop Reasoning in Large Language Models
Jan 12, 2026In multi-hop reasoning, multi-round retrieval-augmented generation (RAG) methods typically rely on LLM-generated content as the retrieval query. However, these approaches are inherently vulnerable to knowledge overshadowing - a phenomenon where critical information is overshadowed during generation. As a result, the LLM-generated content may be incomplete or inaccurate, leading to irrelevant retrieval and causing error accumulation during the iteration process. To address this challenge, we propose ActiShade, which detects and activates overshadowed knowledge to guide large language models (LLMs) in multi-hop reasoning. Specifically, ActiShade iteratively detects the overshadowed keyphrase in the given query, retrieves documents relevant to both the query and the overshadowed keyphrase, and generates a new query based on the retrieved documents to guide the next-round iteration. By supplementing the overshadowed knowledge during the formulation of next-round queries while minimizing the introduction of irrelevant noise, ActiShade reduces the error accumulation caused by knowledge overshadowing. Extensive experiments show that ActiShade outperforms existing methods across multiple datasets and LLMs.
SCoder: Iterative Self-Distillation for Bootstrapping Small-Scale Data Synthesizers to Empower Code LLMs
Sep 09, 2025



Existing code large language models (LLMs) often rely on large-scale instruction data distilled from proprietary LLMs for fine-tuning, which typically incurs high costs. In this paper, we explore the potential of small-scale open-source LLMs (e.g., 7B) as synthesizers for high-quality code instruction data construction. We first observe that the data synthesis capability of small-scale LLMs can be enhanced by training on a few superior data synthesis samples from proprietary LLMs. Building on this, we propose a novel iterative self-distillation approach to bootstrap small-scale LLMs, transforming them into powerful synthesizers that reduce reliance on proprietary LLMs and minimize costs. Concretely, in each iteration, to obtain diverse and high-quality self-distilled data, we design multi-checkpoint sampling and multi-aspect scoring strategies for initial data selection. Furthermore, to identify the most influential samples, we introduce a gradient-based influence estimation method for final data filtering. Based on the code instruction datasets from the small-scale synthesizers, we develop SCoder, a family of code generation models fine-tuned from DeepSeek-Coder. SCoder models achieve state-of-the-art code generation capabilities, demonstrating the effectiveness of our method.
RefineCoder: Iterative Improving of Large Language Models via Adaptive Critique Refinement for Code Generation
Feb 13, 2025Code generation has attracted increasing attention with the rise of Large Language Models (LLMs). Many studies have developed powerful code LLMs by synthesizing code-related instruction data and applying supervised fine-tuning. However, these methods are limited by teacher model distillation and ignore the potential of iterative refinement by self-generated code. In this paper, we propose Adaptive Critique Refinement (ACR), which enables the model to refine itself by self-generated code and external critique, rather than directly imitating the code responses of the teacher model. Concretely, ACR includes a composite scoring system with LLM-as-a-Judge to evaluate the quality of code responses and a selective critique strategy with LLM-as-a-Critic to critique self-generated low-quality code responses. We develop the RefineCoder series by iteratively applying ACR, achieving continuous performance improvement on multiple code generation benchmarks. Compared to the baselines of the same size, our proposed RefineCoder series can achieve comparable or even superior performance using less data.
A Multi-turn Machine Reading Comprehension Framework with Rethink Mechanism for Emotion-Cause Pair Extraction
Sep 16, 2022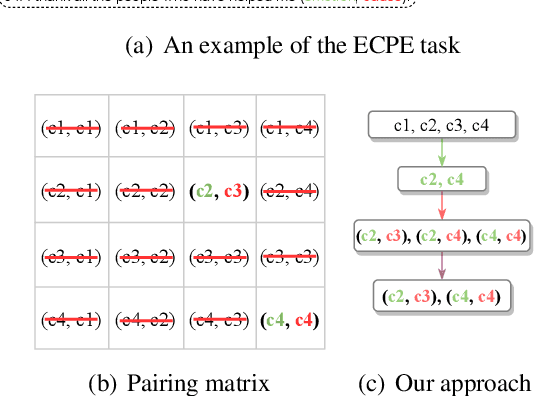
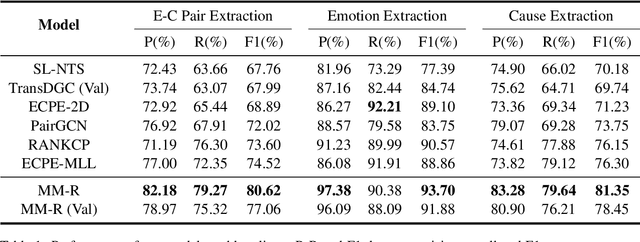
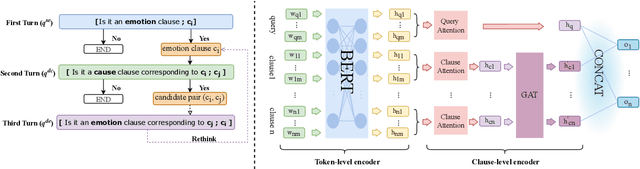

Emotion-cause pair extraction (ECPE) is an emerging task in emotion cause analysis, which extracts potential emotion-cause pairs from an emotional document. Most recent studies use end-to-end methods to tackle the ECPE task. However, these methods either suffer from a label sparsity problem or fail to model complicated relations between emotions and causes. Furthermore, they all do not consider explicit semantic information of clauses. To this end, we transform the ECPE task into a document-level machine reading comprehension (MRC) task and propose a Multi-turn MRC framework with Rethink mechanism (MM-R). Our framework can model complicated relations between emotions and causes while avoiding generating the pairing matrix (the leading cause of the label sparsity problem). Besides, the multi-turn structure can fuse explicit semantic information flow between emotions and causes. Extensive experiments on the benchmark emotion cause corpus demonstrate the effectiveness of our proposed framework, which outperforms existing state-of-the-art methods.