 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSWE-Mutation: Can LLMs Generate Reliable Test Suites in Software Engineering?
May 21, 2026Evaluating software engineering capabilities has become a core component of modern large language models (LLMs); however, the key bottleneck hindering further scaling lies not in the scarcity of high-quality solutions, but in the lack of high-quality test suites. Test suites are indispensable both for synthesizing program repair trajectories and for providing precise feedback signals in reinforcement learning. Unfortunately, due to the high cost and difficulty of annotation, high-quality test suites have long been hard to obtain, while those automatically generated by LLMs tend to be superficial and lack sufficient discriminative power. As a first step toward constructing high-quality test suites, we introduce SWE-Mutation, a benchmark for evaluating LLM-generated test suites. The benchmark characterizes test suites by introducing systematically mutated solutions that attempt to ``fool'' the test suites and pass validation. We further propose an agentic, language-agnostic framework for automatically generating complex mutants. Our benchmark consists of 2,636 mutated variants derived from 800 original instances and includes a multilingual subset spanning nine programming languages. Experiments on seven LLMs reveal that even DeepSeek-V3.1 achieves only 10.20% verification and 36.15% detection rates, highlighting the inadequacy of current LLMs. Additionally, our agentic mutation strategy enhances realism, reducing average detection rates from 71.04% to 39.81% compared to conventional methods. These findings expose persistent deficiencies in the ability of current LLMs to generate reliable and discriminative test suites.
* 24 pages, 8 figures
SCoder: Iterative Self-Distillation for Bootstrapping Small-Scale Data Synthesizers to Empower Code LLMs
Sep 09, 2025



Existing code large language models (LLMs) often rely on large-scale instruction data distilled from proprietary LLMs for fine-tuning, which typically incurs high costs. In this paper, we explore the potential of small-scale open-source LLMs (e.g., 7B) as synthesizers for high-quality code instruction data construction. We first observe that the data synthesis capability of small-scale LLMs can be enhanced by training on a few superior data synthesis samples from proprietary LLMs. Building on this, we propose a novel iterative self-distillation approach to bootstrap small-scale LLMs, transforming them into powerful synthesizers that reduce reliance on proprietary LLMs and minimize costs. Concretely, in each iteration, to obtain diverse and high-quality self-distilled data, we design multi-checkpoint sampling and multi-aspect scoring strategies for initial data selection. Furthermore, to identify the most influential samples, we introduce a gradient-based influence estimation method for final data filtering. Based on the code instruction datasets from the small-scale synthesizers, we develop SCoder, a family of code generation models fine-tuned from DeepSeek-Coder. SCoder models achieve state-of-the-art code generation capabilities, demonstrating the effectiveness of our method.
Pruning Long Chain-of-Thought of Large Reasoning Models via Small-Scale Preference Optimization
Aug 13, 2025



Recent advances in Large Reasoning Models (LRMs) have demonstrated strong performance on complex tasks through long Chain-of-Thought (CoT) reasoning. However, their lengthy outputs increase computational costs and may lead to overthinking, raising challenges in balancing reasoning effectiveness and efficiency. Current methods for efficient reasoning often compromise reasoning quality or require extensive resources. This paper investigates efficient methods to reduce the generation length of LRMs. We analyze generation path distributions and filter generated trajectories through difficulty estimation. Subsequently, we analyze the convergence behaviors of the objectives of various preference optimization methods under a Bradley-Terry loss based framework. Based on the analysis, we propose Length Controlled Preference Optimization (LCPO) that directly balances the implicit reward related to NLL loss. LCPO can effectively learn length preference with limited data and training. Extensive experiments demonstrate that our approach significantly reduces the average output length by over 50\% across multiple benchmarks while maintaining the reasoning performance. Our work highlights the potential for computationally efficient approaches in guiding LRMs toward efficient reasoning.
Simulating Human-Like Learning Dynamics with LLM-Empowered Agents
Aug 07, 2025Capturing human learning behavior based on deep learning methods has become a major research focus in both psychology and intelligent systems. Recent approaches rely on controlled experiments or rule-based models to explore cognitive processes. However, they struggle to capture learning dynamics, track progress over time, or provide explainability. To address these challenges, we introduce LearnerAgent, a novel multi-agent framework based on Large Language Models (LLMs) to simulate a realistic teaching environment. To explore human-like learning dynamics, we construct learners with psychologically grounded profiles-such as Deep, Surface, and Lazy-as well as a persona-free General Learner to inspect the base LLM's default behavior. Through weekly knowledge acquisition, monthly strategic choices, periodic tests, and peer interaction, we can track the dynamic learning progress of individual learners over a full-year journey. Our findings are fourfold: 1) Longitudinal analysis reveals that only Deep Learner achieves sustained cognitive growth. Our specially designed "trap questions" effectively diagnose Surface Learner's shallow knowledge. 2) The behavioral and cognitive patterns of distinct learners align closely with their psychological profiles. 3) Learners' self-concept scores evolve realistically, with the General Learner developing surprisingly high self-efficacy despite its cognitive limitations. 4) Critically, the default profile of base LLM is a "diligent but brittle Surface Learner"-an agent that mimics the behaviors of a good student but lacks true, generalizable understanding. Extensive simulation experiments demonstrate that LearnerAgent aligns well with real scenarios, yielding more insightful findings about LLMs' behavior.
Do Large Language Models Excel in Complex Logical Reasoning with Formal Language?
May 22, 2025Large Language Models (LLMs) have been shown to achieve breakthrough performance on complex logical reasoning tasks. Nevertheless, most existing research focuses on employing formal language to guide LLMs to derive reliable reasoning paths, while systematic evaluations of these capabilities are still limited. In this paper, we aim to conduct a comprehensive evaluation of LLMs across various logical reasoning problems utilizing formal languages. From the perspective of three dimensions, i.e., spectrum of LLMs, taxonomy of tasks, and format of trajectories, our key findings are: 1) Thinking models significantly outperform Instruct models, especially when formal language is employed; 2) All LLMs exhibit limitations in inductive reasoning capability, irrespective of whether they use a formal language; 3) Data with PoT format achieves the best generalization performance across other languages. Additionally, we also curate the formal-relative training data to further enhance the small language models, and the experimental results indicate that a simple rejected fine-tuning method can better enable LLMs to generalize across formal languages and achieve the best overall performance. Our codes and reports are available at https://github.com/jiangjin1999/FormalEval.
VerifyBench: Benchmarking Reference-based Reward Systems for Large Language Models
May 21, 2025



Large reasoning models such as OpenAI o1 and DeepSeek-R1 have achieved remarkable performance in the domain of reasoning. A key component of their training is the incorporation of verifiable rewards within reinforcement learning (RL). However, existing reward benchmarks do not evaluate reference-based reward systems, leaving researchers with limited understanding of the accuracy of verifiers used in RL. In this paper, we introduce two benchmarks, VerifyBench and VerifyBench-Hard, designed to assess the performance of reference-based reward systems. These benchmarks are constructed through meticulous data collection and curation, followed by careful human annotation to ensure high quality. Current models still show considerable room for improvement on both VerifyBench and VerifyBench-Hard, especially smaller-scale models. Furthermore, we conduct a thorough and comprehensive analysis of evaluation results, offering insights for understanding and developing reference-based reward systems. Our proposed benchmarks serve as effective tools for guiding the development of verifier accuracy and the reasoning capabilities of models trained via RL in reasoning tasks.
FRAbench and GenEval: Scaling Fine-Grained Aspect Evaluation across Tasks, Modalities
May 19, 2025Evaluating the open-ended outputs of large language models (LLMs) has become a bottleneck as model capabilities, task diversity, and modality coverage rapidly expand. Existing "LLM-as-a-Judge" evaluators are typically narrow in a few tasks, aspects, or modalities, and easily suffer from low consistency. In this paper, we argue that explicit, fine-grained aspect specification is the key to both generalizability and objectivity in automated evaluation. To do so, we introduce a hierarchical aspect taxonomy spanning 112 aspects that unifies evaluation across four representative settings - Natural Language Generation, Image Understanding, Image Generation, and Interleaved Text-and-Image Generation. Building on this taxonomy, we create FRAbench, a benchmark comprising 60.4k pairwise samples with 325k aspect-level labels obtained from a combination of human and LLM annotations. FRAbench provides the first large-scale, multi-modal resource for training and meta-evaluating fine-grained LMM judges. Leveraging FRAbench, we develop GenEval, a fine-grained evaluator generalizable across tasks and modalities. Experiments show that GenEval (i) attains high agreement with GPT-4o and expert annotators, (ii) transfers robustly to unseen tasks and modalities, and (iii) reveals systematic weaknesses of current LMMs on evaluation.
Prejudge-Before-Think: Enhancing Large Language Models at Test-Time by Process Prejudge Reasoning
Apr 18, 2025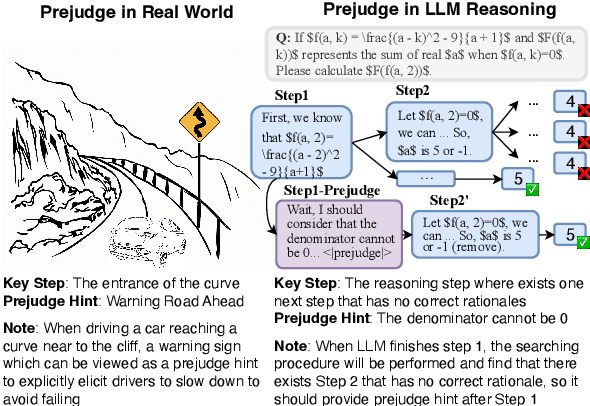
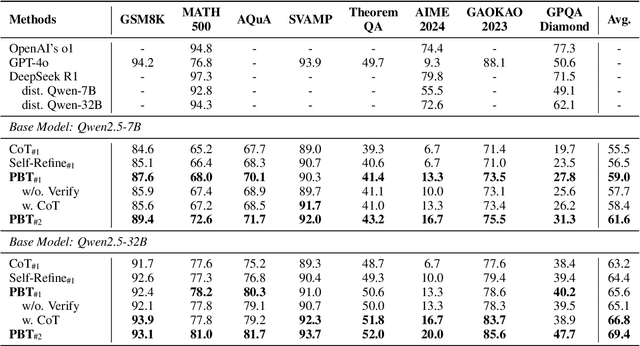
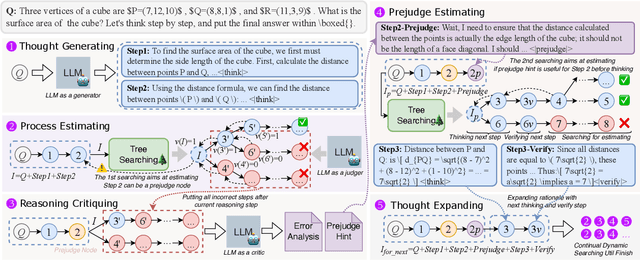
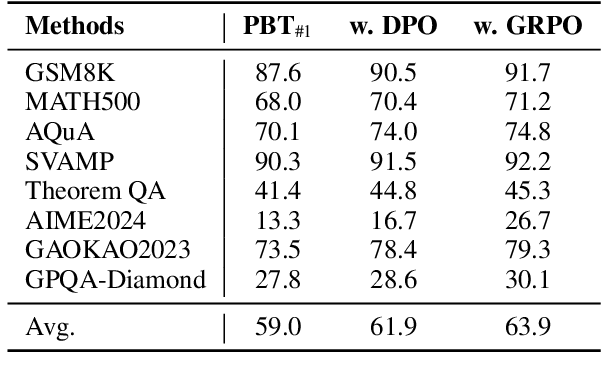
In this paper, we introduce a new \emph{process prejudge} strategy in LLM reasoning to demonstrate that bootstrapping with process prejudge allows the LLM to adaptively anticipate the errors encountered when advancing the subsequent reasoning steps, similar to people sometimes pausing to think about what mistakes may occur and how to avoid them, rather than relying solely on trial and error. Specifically, we define a prejudge node in the rationale, which represents a reasoning step, with at least one step that follows the prejudge node that has no paths toward the correct answer. To synthesize the prejudge reasoning process, we present an automated reasoning framework with a dynamic tree-searching strategy. This framework requires only one LLM to perform answer judging, response critiquing, prejudge generation, and thought completion. Furthermore, we develop a two-phase training mechanism with supervised fine-tuning (SFT) and reinforcement learning (RL) to further enhance the reasoning capabilities of LLMs. Experimental results from competition-level complex reasoning demonstrate that our method can teach the model to prejudge before thinking and significantly enhance the reasoning ability of LLMs. Code and data is released at https://github.com/wjn1996/Prejudge-Before-Think.
InftyThink: Breaking the Length Limits of Long-Context Reasoning in Large Language Models
Mar 09, 2025



Advanced reasoning in large language models has achieved remarkable performance on challenging tasks, but the prevailing long-context reasoning paradigm faces critical limitations: quadratic computational scaling with sequence length, reasoning constrained by maximum context boundaries, and performance degradation beyond pre-training context windows. Existing approaches primarily compress reasoning chains without addressing the fundamental scaling problem. To overcome these challenges, we introduce InftyThink, a paradigm that transforms monolithic reasoning into an iterative process with intermediate summarization. By interleaving short reasoning segments with concise progress summaries, our approach enables unbounded reasoning depth while maintaining bounded computational costs. This creates a characteristic sawtooth memory pattern that significantly reduces computational complexity compared to traditional approaches. Furthermore, we develop a methodology for reconstructing long-context reasoning datasets into our iterative format, transforming OpenR1-Math into 333K training instances. Experiments across multiple model architectures demonstrate that our approach reduces computational costs while improving performance, with Qwen2.5-Math-7B showing 3-13% improvements across MATH500, AIME24, and GPQA_diamond benchmarks. Our work challenges the assumed trade-off between reasoning depth and computational efficiency, providing a more scalable approach to complex reasoning without architectural modifications.
The Role of Visual Modality in Multimodal Mathematical Reasoning: Challenges and Insights
Mar 06, 2025Recent research has increasingly focused on multimodal mathematical reasoning, particularly emphasizing the creation of relevant datasets and benchmarks. Despite this, the role of visual information in reasoning has been underexplored. Our findings show that existing multimodal mathematical models minimally leverage visual information, and model performance remains largely unaffected by changes to or removal of images in the dataset. We attribute this to the dominance of textual information and answer options that inadvertently guide the model to correct answers. To improve evaluation methods, we introduce the HC-M3D dataset, specifically designed to require image reliance for problem-solving and to challenge models with similar, yet distinct, images that change the correct answer. In testing leading models, their failure to detect these subtle visual differences suggests limitations in current visual perception capabilities. Additionally, we observe that the common approach of improving general VQA capabilities by combining various types of image encoders does not contribute to math reasoning performance. This finding also presents a challenge to enhancing visual reliance during math reasoning. Our benchmark and code would be available at \href{https://github.com/Yufang-Liu/visual_modality_role}{https://github.com/Yufang-Liu/visual\_modality\_role}.