 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDP-SfM: Dual-Pixel Structure-from-Motion without Scale Ambiguity
May 03, 2026Multi-view 3D reconstruction, namely, structure-from-motion followed by multi-view stereo, is a fundamental component of 3D computer vision. In general, multi-view 3D reconstruction suffers from an unknown scale ambiguity unless a reference object of known size is present in the scene. In this article, we show that multi-view images captured using a dual-pixel (DP) sensor can automatically resolve the scale ambiguity, without requiring a reference object or prior calibration. Specifically, the defocus blur observed in DP images provides sufficient information to determine the absolute scale when paired with depth maps (up to scale) recovered from multi-view 3D reconstruction. Based on this observation, we develop a simple yet effective linear method to estimate the absolute scale, followed by the intensity-based optimization stage that aligns the left and right DP images by shifting them back toward each other using cross-view blur kernels. Experiments demonstrate the effectiveness of the proposed approach across diverse scenes captured with different cameras and lenses. Code and data are available at https://github.com/lilika-makabe/dp-sfm-tpami.git
BioVITA: Biological Dataset, Model, and Benchmark for Visual-Textual-Acoustic Alignment
Mar 25, 2026Understanding animal species from multimodal data poses an emerging challenge at the intersection of computer vision and ecology. While recent biological models, such as BioCLIP, have demonstrated strong alignment between images and textual taxonomic information for species identification, the integration of the audio modality remains an open problem. We propose BioVITA, a novel visual-textual-acoustic alignment framework for biological applications. BioVITA involves (i) a training dataset, (ii) a representation model, and (iii) a retrieval benchmark. First, we construct a large-scale training dataset comprising 1.3 million audio clips and 2.3 million images, covering 14,133 species annotated with 34 ecological trait labels. Second, building upon BioCLIP2, we introduce a two-stage training framework to effectively align audio representations with visual and textual representations. Third, we develop a cross-modal retrieval benchmark that covers all possible directional retrieval across the three modalities (i.e., image-to-audio, audio-to-text, text-to-image, and their reverse directions), with three taxonomic levels: Family, Genus, and Species. Extensive experiments demonstrate that our model learns a unified representation space that captures species-level semantics beyond taxonomy, advancing multimodal biodiversity understanding. The project page is available at: https://dahlian00.github.io/BioVITA_Page/
AnimalCLAP: Taxonomy-Aware Language-Audio Pretraining for Species Recognition and Trait Inference
Mar 23, 2026Animal vocalizations provide crucial insights for wildlife assessment, particularly in complex environments such as forests, aiding species identification and ecological monitoring. Recent advances in deep learning have enabled automatic species classification from their vocalizations. However, classifying species unseen during training remains challenging. To address this limitation, we introduce AnimalCLAP, a taxonomy-aware language-audio framework comprising a new dataset and model that incorporate hierarchical biological information. Specifically, our vocalization dataset consists of 4,225 hours of recordings covering 6,823 species, annotated with 22 ecological traits. The AnimalCLAP model is trained on this dataset to align audio and textual representations using taxonomic structures, improving the recognition of unseen species. We demonstrate that our proposed model effectively infers ecological and biological attributes of species directly from their vocalizations, achieving superior performance compared to CLAP. Our dataset, code, and models will be publicly available at https://dahlian00.github.io/AnimalCLAP_Page/.
Near-light Photometric Stereo with Symmetric Lights
Mar 17, 2026This paper describes a linear solution method for near-light photometric stereo by exploiting symmetric light source arrangements. Unlike conventional non-convex optimization approaches, by arranging multiple sets of symmetric nearby light source pairs, our method derives a closed-form solution for surface normal and depth without requiring initialization. In addition, our method works as long as the light sources are symmetrically distributed about an arbitrary point even when the entire spatial offset is uncalibrated. Experiments showcase the accuracy of shape recovery accuracy of our method, achieving comparable results to the state-of-the-art calibrated near-light photometric stereo method while significantly reducing requirements of careful depth initialization and light calibration.
Interaction-via-Actions: Cattle Interaction Detection with Joint Learning of Action-Interaction Latent Space
Dec 18, 2025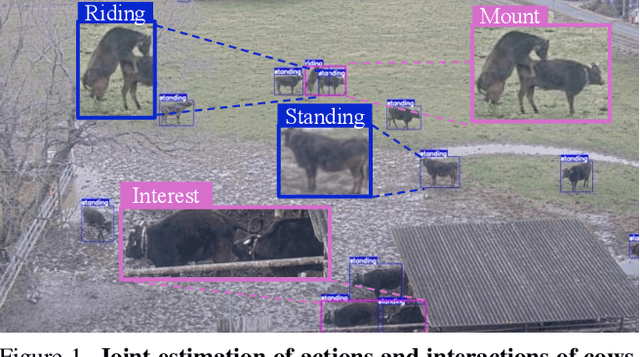
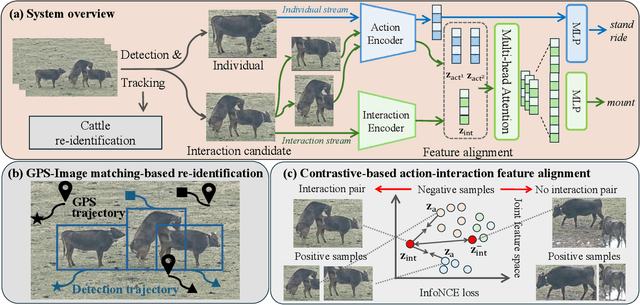
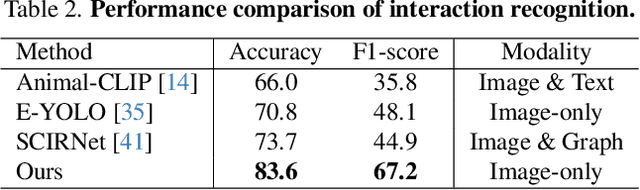
This paper introduces a method and application for automatically detecting behavioral interactions between grazing cattle from a single image, which is essential for smart livestock management in the cattle industry, such as for detecting estrus. Although interaction detection for humans has been actively studied, a non-trivial challenge lies in cattle interaction detection, specifically the lack of a comprehensive behavioral dataset that includes interactions, as the interactions of grazing cattle are rare events. We, therefore, propose CattleAct, a data-efficient method for interaction detection by decomposing interactions into the combinations of actions by individual cattle. Specifically, we first learn an action latent space from a large-scale cattle action dataset. Then, we embed rare interactions via the fine-tuning of the pre-trained latent space using contrastive learning, thereby constructing a unified latent space of actions and interactions. On top of the proposed method, we develop a practical working system integrating video and GPS inputs. Experiments on a commercial-scale pasture demonstrate the accurate interaction detection achieved by our method compared to the baselines. Our implementation is available at https://github.com/rakawanegan/CattleAct.
GaussianPlant: Structure-aligned Gaussian Splatting for 3D Reconstruction of Plants
Dec 16, 2025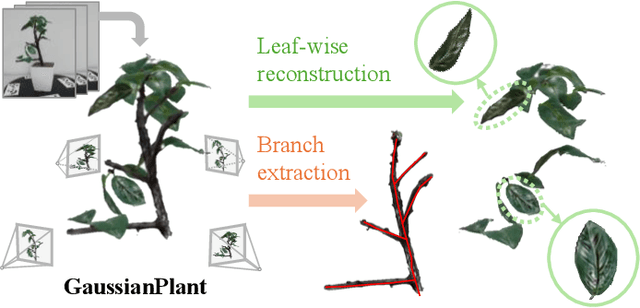



We present a method for jointly recovering the appearance and internal structure of botanical plants from multi-view images based on 3D Gaussian Splatting (3DGS). While 3DGS exhibits robust reconstruction of scene appearance for novel-view synthesis, it lacks structural representations underlying those appearances (e.g., branching patterns of plants), which limits its applicability to tasks such as plant phenotyping. To achieve both high-fidelity appearance and structural reconstruction, we introduce GaussianPlant, a hierarchical 3DGS representation, which disentangles structure and appearance. Specifically, we employ structure primitives (StPs) to explicitly represent branch and leaf geometry, and appearance primitives (ApPs) to the plants' appearance using 3D Gaussians. StPs represent a simplified structure of the plant, i.e., modeling branches as cylinders and leaves as disks. To accurately distinguish the branches and leaves, StP's attributes (i.e., branches or leaves) are optimized in a self-organized manner. ApPs are bound to each StP to represent the appearance of branches or leaves as in conventional 3DGS. StPs and ApPs are jointly optimized using a re-rendering loss on the input multi-view images, as well as the gradient flow from ApP to StP using the binding correspondence information. We conduct experiments to qualitatively evaluate the reconstruction accuracy of both appearance and structure, as well as real-world experiments to qualitatively validate the practical performance. Experiments show that the GaussianPlant achieves both high-fidelity appearance reconstruction via ApPs and accurate structural reconstruction via StPs, enabling the extraction of branch structure and leaf instances.
Zero-shot Hierarchical Plant Segmentation via Foundation Segmentation Models and Text-to-image Attention
Sep 11, 2025Foundation segmentation models achieve reasonable leaf instance extraction from top-view crop images without training (i.e., zero-shot). However, segmenting entire plant individuals with each consisting of multiple overlapping leaves remains challenging. This problem is referred to as a hierarchical segmentation task, typically requiring annotated training datasets, which are often species-specific and require notable human labor. To address this, we introduce ZeroPlantSeg, a zero-shot segmentation for rosette-shaped plant individuals from top-view images. We integrate a foundation segmentation model, extracting leaf instances, and a vision-language model, reasoning about plants' structures to extract plant individuals without additional training. Evaluations on datasets with multiple plant species, growth stages, and shooting environments demonstrate that our method surpasses existing zero-shot methods and achieves better cross-domain performance than supervised methods. Implementations are available at https://github.com/JunhaoXing/ZeroPlantSeg.
Spectral Sensitivity Estimation with an Uncalibrated Diffraction Grating
Aug 01, 2025This paper introduces a practical and accurate calibration method for camera spectral sensitivity using a diffraction grating. Accurate calibration of camera spectral sensitivity is crucial for various computer vision tasks, including color correction, illumination estimation, and material analysis. Unlike existing approaches that require specialized narrow-band filters or reference targets with known spectral reflectances, our method only requires an uncalibrated diffraction grating sheet, readily available off-the-shelf. By capturing images of the direct illumination and its diffracted pattern through the grating sheet, our method estimates both the camera spectral sensitivity and the diffraction grating parameters in a closed-form manner. Experiments on synthetic and real-world data demonstrate that our method outperforms conventional reference target-based methods, underscoring its effectiveness and practicality.
TreeFormer: Single-view Plant Skeleton Estimation via Tree-constrained Graph Generation
Nov 25, 2024



Accurate estimation of plant skeletal structure (e.g., branching structure) from images is essential for smart agriculture and plant science. Unlike human skeletons with fixed topology, plant skeleton estimation presents a unique challenge, i.e., estimating arbitrary tree graphs from images. While recent graph generation methods successfully infer thin structures from images, it is challenging to constrain the output graph strictly to a tree structure. To this problem, we present TreeFormer, a plant skeleton estimator via tree-constrained graph generation. Our approach combines learning-based graph generation with traditional graph algorithms to impose the constraints during the training loop. Specifically, our method projects an unconstrained graph onto a minimum spanning tree (MST) during the training loop and incorporates this prior knowledge into the gradient descent optimization by suppressing unwanted feature values. Experiments show that our method accurately estimates target plant skeletal structures for multiple domains: Synthetic tree patterns, real botanical roots, and grapevine branches. Our implementations are available at https://github.com/huntorochi/TreeFormer/.
NeRSP: Neural 3D Reconstruction for Reflective Objects with Sparse Polarized Images
Jun 11, 2024



We present NeRSP, a Neural 3D reconstruction technique for Reflective surfaces with Sparse Polarized images. Reflective surface reconstruction is extremely challenging as specular reflections are view-dependent and thus violate the multiview consistency for multiview stereo. On the other hand, sparse image inputs, as a practical capture setting, commonly cause incomplete or distorted results due to the lack of correspondence matching. This paper jointly handles the challenges from sparse inputs and reflective surfaces by leveraging polarized images. We derive photometric and geometric cues from the polarimetric image formation model and multiview azimuth consistency, which jointly optimize the surface geometry modeled via implicit neural representation. Based on the experiments on our synthetic and real datasets, we achieve the state-of-the-art surface reconstruction results with only 6 views as input.