 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBioVITA: Biological Dataset, Model, and Benchmark for Visual-Textual-Acoustic Alignment
Mar 25, 2026Understanding animal species from multimodal data poses an emerging challenge at the intersection of computer vision and ecology. While recent biological models, such as BioCLIP, have demonstrated strong alignment between images and textual taxonomic information for species identification, the integration of the audio modality remains an open problem. We propose BioVITA, a novel visual-textual-acoustic alignment framework for biological applications. BioVITA involves (i) a training dataset, (ii) a representation model, and (iii) a retrieval benchmark. First, we construct a large-scale training dataset comprising 1.3 million audio clips and 2.3 million images, covering 14,133 species annotated with 34 ecological trait labels. Second, building upon BioCLIP2, we introduce a two-stage training framework to effectively align audio representations with visual and textual representations. Third, we develop a cross-modal retrieval benchmark that covers all possible directional retrieval across the three modalities (i.e., image-to-audio, audio-to-text, text-to-image, and their reverse directions), with three taxonomic levels: Family, Genus, and Species. Extensive experiments demonstrate that our model learns a unified representation space that captures species-level semantics beyond taxonomy, advancing multimodal biodiversity understanding. The project page is available at: https://dahlian00.github.io/BioVITA_Page/
AnimalCLAP: Taxonomy-Aware Language-Audio Pretraining for Species Recognition and Trait Inference
Mar 23, 2026Animal vocalizations provide crucial insights for wildlife assessment, particularly in complex environments such as forests, aiding species identification and ecological monitoring. Recent advances in deep learning have enabled automatic species classification from their vocalizations. However, classifying species unseen during training remains challenging. To address this limitation, we introduce AnimalCLAP, a taxonomy-aware language-audio framework comprising a new dataset and model that incorporate hierarchical biological information. Specifically, our vocalization dataset consists of 4,225 hours of recordings covering 6,823 species, annotated with 22 ecological traits. The AnimalCLAP model is trained on this dataset to align audio and textual representations using taxonomic structures, improving the recognition of unseen species. We demonstrate that our proposed model effectively infers ecological and biological attributes of species directly from their vocalizations, achieving superior performance compared to CLAP. Our dataset, code, and models will be publicly available at https://dahlian00.github.io/AnimalCLAP_Page/.
HalDec-Bench: Benchmarking Hallucination Detector in Image Captioning
Mar 16, 2026Hallucination detection in captions (HalDec) assesses a vision-language model's ability to correctly align image content with text by identifying errors in captions that misrepresent the image. Beyond evaluation, effective hallucination detection is also essential for curating high-quality image-caption pairs used to train VLMs. However, the generalizability of VLMs as hallucination detectors across different captioning models and hallucination types remains unclear due to the lack of a comprehensive benchmark. In this work, we introduce HalDec-Bench, a benchmark designed to evaluate hallucination detectors in a principled and interpretable manner. HalDec-Bench contains captions generated by diverse VLMs together with human annotations indicating the presence of hallucinations, detailed hallucination-type categories, and segment-level labels. The benchmark provides tasks with a wide range of difficulty levels and reveals performance differences across models that are not visible in existing multimodal reasoning or alignment benchmarks. Our analysis further uncovers two key findings. First, detectors tend to recognize sentences appearing at the beginning of a response as correct, regardless of their actual correctness. Second, our experiments suggest that dataset noise can be substantially reduced by using strong VLMs as filters while employing recent VLMs as caption generators. Our project page is available at https://dahlian00.github.io/HalDec-Bench-Page/.
Interaction-via-Actions: Cattle Interaction Detection with Joint Learning of Action-Interaction Latent Space
Dec 18, 2025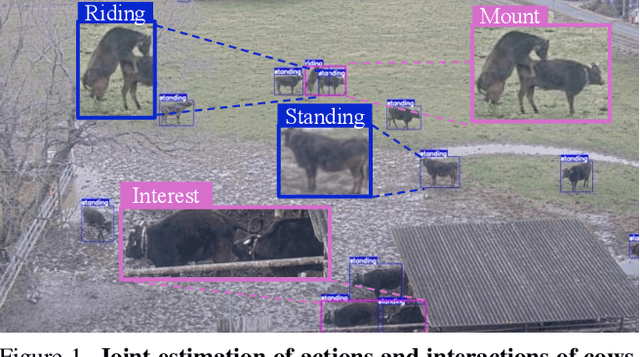
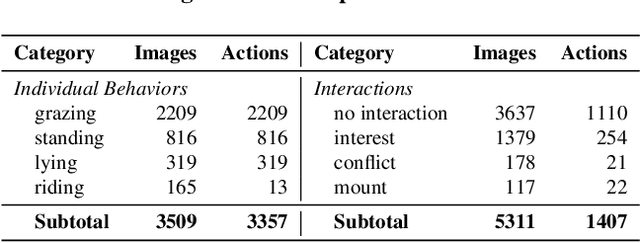
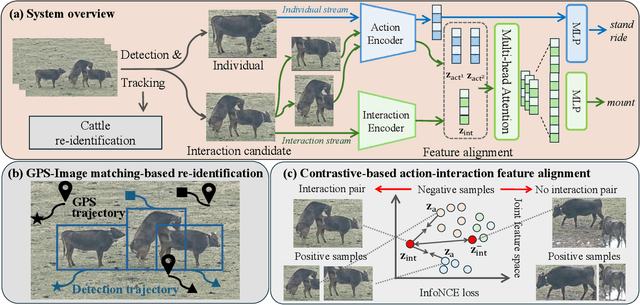
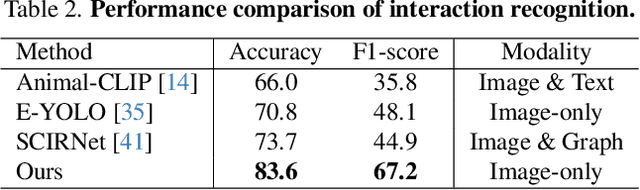
This paper introduces a method and application for automatically detecting behavioral interactions between grazing cattle from a single image, which is essential for smart livestock management in the cattle industry, such as for detecting estrus. Although interaction detection for humans has been actively studied, a non-trivial challenge lies in cattle interaction detection, specifically the lack of a comprehensive behavioral dataset that includes interactions, as the interactions of grazing cattle are rare events. We, therefore, propose CattleAct, a data-efficient method for interaction detection by decomposing interactions into the combinations of actions by individual cattle. Specifically, we first learn an action latent space from a large-scale cattle action dataset. Then, we embed rare interactions via the fine-tuning of the pre-trained latent space using contrastive learning, thereby constructing a unified latent space of actions and interactions. On top of the proposed method, we develop a practical working system integrating video and GPS inputs. Experiments on a commercial-scale pasture demonstrate the accurate interaction detection achieved by our method compared to the baselines. Our implementation is available at https://github.com/rakawanegan/CattleAct.
GaussianPlant: Structure-aligned Gaussian Splatting for 3D Reconstruction of Plants
Dec 16, 2025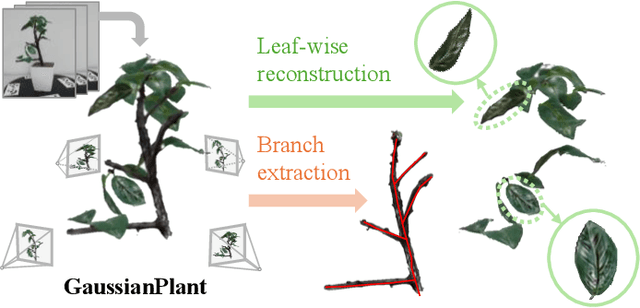



We present a method for jointly recovering the appearance and internal structure of botanical plants from multi-view images based on 3D Gaussian Splatting (3DGS). While 3DGS exhibits robust reconstruction of scene appearance for novel-view synthesis, it lacks structural representations underlying those appearances (e.g., branching patterns of plants), which limits its applicability to tasks such as plant phenotyping. To achieve both high-fidelity appearance and structural reconstruction, we introduce GaussianPlant, a hierarchical 3DGS representation, which disentangles structure and appearance. Specifically, we employ structure primitives (StPs) to explicitly represent branch and leaf geometry, and appearance primitives (ApPs) to the plants' appearance using 3D Gaussians. StPs represent a simplified structure of the plant, i.e., modeling branches as cylinders and leaves as disks. To accurately distinguish the branches and leaves, StP's attributes (i.e., branches or leaves) are optimized in a self-organized manner. ApPs are bound to each StP to represent the appearance of branches or leaves as in conventional 3DGS. StPs and ApPs are jointly optimized using a re-rendering loss on the input multi-view images, as well as the gradient flow from ApP to StP using the binding correspondence information. We conduct experiments to qualitatively evaluate the reconstruction accuracy of both appearance and structure, as well as real-world experiments to qualitatively validate the practical performance. Experiments show that the GaussianPlant achieves both high-fidelity appearance reconstruction via ApPs and accurate structural reconstruction via StPs, enabling the extraction of branch structure and leaf instances.
Zero-shot Hierarchical Plant Segmentation via Foundation Segmentation Models and Text-to-image Attention
Sep 11, 2025Foundation segmentation models achieve reasonable leaf instance extraction from top-view crop images without training (i.e., zero-shot). However, segmenting entire plant individuals with each consisting of multiple overlapping leaves remains challenging. This problem is referred to as a hierarchical segmentation task, typically requiring annotated training datasets, which are often species-specific and require notable human labor. To address this, we introduce ZeroPlantSeg, a zero-shot segmentation for rosette-shaped plant individuals from top-view images. We integrate a foundation segmentation model, extracting leaf instances, and a vision-language model, reasoning about plants' structures to extract plant individuals without additional training. Evaluations on datasets with multiple plant species, growth stages, and shooting environments demonstrate that our method surpasses existing zero-shot methods and achieves better cross-domain performance than supervised methods. Implementations are available at https://github.com/JunhaoXing/ZeroPlantSeg.
AgroBench: Vision-Language Model Benchmark in Agriculture
Jul 28, 2025



Precise automated understanding of agricultural tasks such as disease identification is essential for sustainable crop production. Recent advances in vision-language models (VLMs) are expected to further expand the range of agricultural tasks by facilitating human-model interaction through easy, text-based communication. Here, we introduce AgroBench (Agronomist AI Benchmark), a benchmark for evaluating VLM models across seven agricultural topics, covering key areas in agricultural engineering and relevant to real-world farming. Unlike recent agricultural VLM benchmarks, AgroBench is annotated by expert agronomists. Our AgroBench covers a state-of-the-art range of categories, including 203 crop categories and 682 disease categories, to thoroughly evaluate VLM capabilities. In our evaluation on AgroBench, we reveal that VLMs have room for improvement in fine-grained identification tasks. Notably, in weed identification, most open-source VLMs perform close to random. With our wide range of topics and expert-annotated categories, we analyze the types of errors made by VLMs and suggest potential pathways for future VLM development. Our dataset and code are available at https://dahlian00.github.io/AgroBenchPage/ .
AnimalClue: Recognizing Animals by their Traces
Jul 27, 2025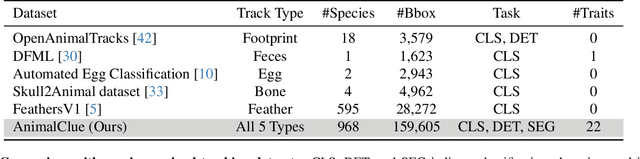

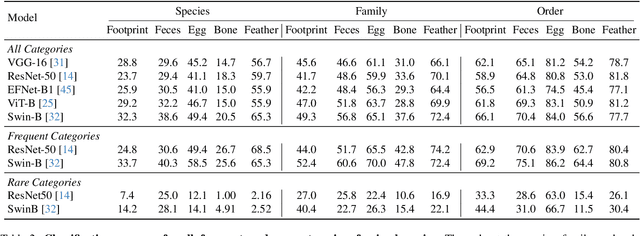
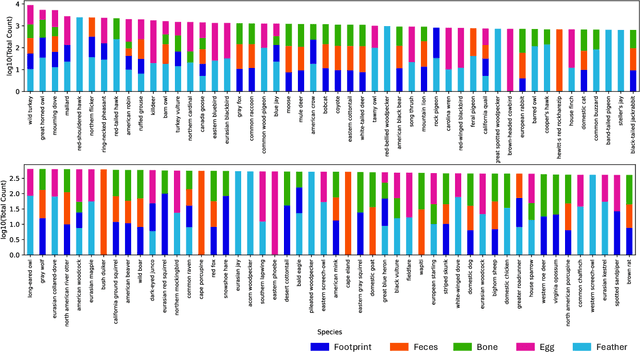
Wildlife observation plays an important role in biodiversity conservation, necessitating robust methodologies for monitoring wildlife populations and interspecies interactions. Recent advances in computer vision have significantly contributed to automating fundamental wildlife observation tasks, such as animal detection and species identification. However, accurately identifying species from indirect evidence like footprints and feces remains relatively underexplored, despite its importance in contributing to wildlife monitoring. To bridge this gap, we introduce AnimalClue, the first large-scale dataset for species identification from images of indirect evidence. Our dataset consists of 159,605 bounding boxes encompassing five categories of indirect clues: footprints, feces, eggs, bones, and feathers. It covers 968 species, 200 families, and 65 orders. Each image is annotated with species-level labels, bounding boxes or segmentation masks, and fine-grained trait information, including activity patterns and habitat preferences. Unlike existing datasets primarily focused on direct visual features (e.g., animal appearances), AnimalClue presents unique challenges for classification, detection, and instance segmentation tasks due to the need for recognizing more detailed and subtle visual features. In our experiments, we extensively evaluate representative vision models and identify key challenges in animal identification from their traces. Our dataset and code are available at https://dahlian00.github.io/AnimalCluePage/
SBS Figures: Pre-training Figure QA from Stage-by-Stage Synthesized Images
Dec 23, 2024



Building a large-scale figure QA dataset requires a considerable amount of work, from gathering and selecting figures to extracting attributes like text, numbers, and colors, and generating QAs. Although recent developments in LLMs have led to efforts to synthesize figures, most of these focus primarily on QA generation. Additionally, creating figures directly using LLMs often encounters issues such as code errors, similar-looking figures, and repetitive content in figures. To address this issue, we present SBSFigures (Stage-by-Stage Synthetic Figures), a dataset for pre-training figure QA. Our proposed pipeline enables the creation of chart figures with complete annotations of the visualized data and dense QA annotations without any manual annotation process. Our stage-by-stage pipeline makes it possible to create diverse topic and appearance figures efficiently while minimizing code errors. Our SBSFigures demonstrate a strong pre-training effect, making it possible to achieve efficient training with a limited amount of real-world chart data starting from our pre-trained weights.
PetFace: A Large-Scale Dataset and Benchmark for Animal Identification
Jul 18, 2024Automated animal face identification plays a crucial role in the monitoring of behaviors, conducting of surveys, and finding of lost animals. Despite the advancements in human face identification, the lack of datasets and benchmarks in the animal domain has impeded progress. In this paper, we introduce the PetFace dataset, a comprehensive resource for animal face identification encompassing 257,484 unique individuals across 13 animal families and 319 breed categories, including both experimental and pet animals. This large-scale collection of individuals facilitates the investigation of unseen animal face verification, an area that has not been sufficiently explored in existing datasets due to the limited number of individuals. Moreover, PetFace also has fine-grained annotations such as sex, breed, color, and pattern. We provide multiple benchmarks including re-identification for seen individuals and verification for unseen individuals. The models trained on our dataset outperform those trained on prior datasets, even for detailed breed variations and unseen animal families. Our result also indicates that there is some room to improve the performance of integrated identification on multiple animal families. We hope the PetFace dataset will facilitate animal face identification and encourage the development of non-invasive animal automatic identification methods.