 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlutus: Benchmarking Large Language Models in Low-Resource Greek Finance
Feb 26, 2025Despite Greece's pivotal role in the global economy, large language models (LLMs) remain underexplored for Greek financial context due to the linguistic complexity of Greek and the scarcity of domain-specific datasets. Previous efforts in multilingual financial natural language processing (NLP) have exposed considerable performance disparities, yet no dedicated Greek financial benchmarks or Greek-specific financial LLMs have been developed until now. To bridge this gap, we introduce Plutus-ben, the first Greek Financial Evaluation Benchmark, and Plutus-8B, the pioneering Greek Financial LLM, fine-tuned with Greek domain-specific data. Plutus-ben addresses five core financial NLP tasks in Greek: numeric and textual named entity recognition, question answering, abstractive summarization, and topic classification, thereby facilitating systematic and reproducible LLM assessments. To underpin these tasks, we present three novel, high-quality Greek financial datasets, thoroughly annotated by expert native Greek speakers, augmented by two existing resources. Our comprehensive evaluation of 22 LLMs on Plutus-ben reveals that Greek financial NLP remains challenging due to linguistic complexity, domain-specific terminology, and financial reasoning gaps. These findings underscore the limitations of cross-lingual transfer, the necessity for financial expertise in Greek-trained models, and the challenges of adapting financial LLMs to Greek text. We release Plutus-ben, Plutus-8B, and all associated datasets publicly to promote reproducible research and advance Greek financial NLP, fostering broader multilingual inclusivity in finance.
CoopDETR: A Unified Cooperative Perception Framework for 3D Detection via Object Query
Feb 26, 2025



Cooperative perception enhances the individual perception capabilities of autonomous vehicles (AVs) by providing a comprehensive view of the environment. However, balancing perception performance and transmission costs remains a significant challenge. Current approaches that transmit region-level features across agents are limited in interpretability and demand substantial bandwidth, making them unsuitable for practical applications. In this work, we propose CoopDETR, a novel cooperative perception framework that introduces object-level feature cooperation via object query. Our framework consists of two key modules: single-agent query generation, which efficiently encodes raw sensor data into object queries, reducing transmission cost while preserving essential information for detection; and cross-agent query fusion, which includes Spatial Query Matching (SQM) and Object Query Aggregation (OQA) to enable effective interaction between queries. Our experiments on the OPV2V and V2XSet datasets demonstrate that CoopDETR achieves state-of-the-art performance and significantly reduces transmission costs to 1/782 of previous methods.
MDN: Mamba-Driven Dualstream Network For Medical Hyperspectral Image Segmentation
Feb 24, 2025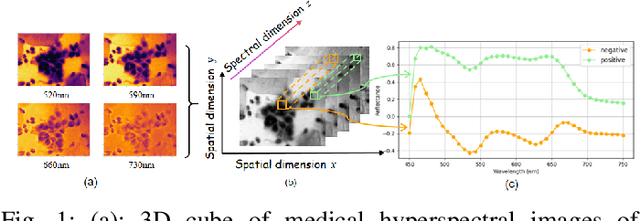
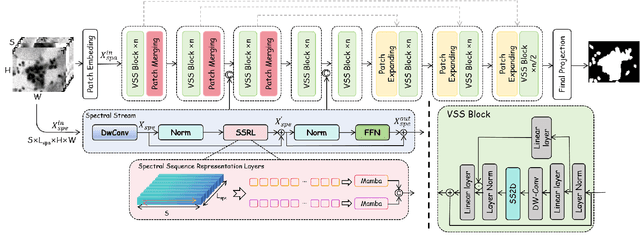
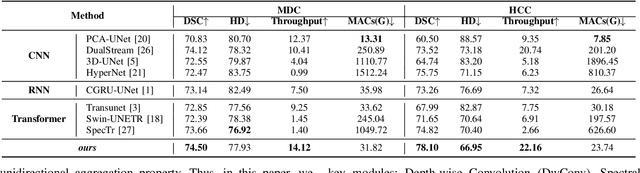
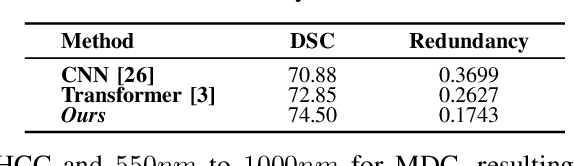
Medical Hyperspectral Imaging (MHSI) offers potential for computational pathology and precision medicine. However, existing CNN and Transformer struggle to balance segmentation accuracy and speed due to high spatial-spectral dimensionality. In this study, we leverage Mamba's global context modeling to propose a dual-stream architecture for joint spatial-spectral feature extraction. To address the limitation of Mamba's unidirectional aggregation, we introduce a recurrent spectral sequence representation to capture low-redundancy global spectral features. Experiments on a public Multi-Dimensional Choledoch dataset and a private Cervical Cancer dataset show that our method outperforms state-of-the-art approaches in segmentation accuracy while minimizing resource usage and achieving the fastest inference speed. Our code will be available at https://github.com/DeepMed-Lab-ECNU/MDN.
VidLBEval: Benchmarking and Mitigating Language Bias in Video-Involved LVLMs
Feb 23, 2025



Recently, Large Vision-Language Models (LVLMs) have made significant strides across diverse multimodal tasks and benchmarks. This paper reveals a largely under-explored problem from existing video-involved LVLMs - language bias, where models tend to prioritize language over video and thus result in incorrect responses. To address this research gap, we first collect a Video Language Bias Evaluation Benchmark, which is specifically designed to assess the language bias in video-involved LVLMs through two key tasks: ambiguous video contrast and interrogative question probing. Accordingly, we design accompanied evaluation metrics that aim to penalize LVLMs being biased by language. In addition, we also propose Multi-branch Contrastive Decoding (MCD), introducing two expert branches to simultaneously counteract language bias potentially generated by the amateur text-only branch. Our experiments demonstrate that i) existing video-involved LVLMs, including both proprietary and open-sourced, are largely limited by the language bias problem; ii) our MCD can effectively mitigate this issue and maintain general-purpose capabilities in various video-involved LVLMs without any additional retraining or alteration to model architectures.
Constructing a Norm for Children's Scientific Drawing: Distribution Features Based on Semantic Similarity of Large Language Models
Feb 21, 2025The use of children's drawings to examining their conceptual understanding has been proven to be an effective method, but there are two major problems with previous research: 1. The content of the drawings heavily relies on the task, and the ecological validity of the conclusions is low; 2. The interpretation of drawings relies too much on the subjective feelings of the researchers. To address this issue, this study uses the Large Language Model (LLM) to identify 1420 children's scientific drawings (covering 9 scientific themes/concepts), and uses the word2vec algorithm to calculate their semantic similarity. The study explores whether there are consistent drawing representations for children on the same theme, and attempts to establish a norm for children's scientific drawings, providing a baseline reference for follow-up children's drawing research. The results show that the representation of most drawings has consistency, manifested as most semantic similarity greater than 0.8. At the same time, it was found that the consistency of the representation is independent of the accuracy (of LLM's recognition), indicating the existence of consistency bias. In the subsequent exploration of influencing factors, we used Kendall rank correlation coefficient to investigate the effects of Sample Size, Abstract Degree, and Focus Points on drawings, and used word frequency statistics to explore whether children represented abstract themes/concepts by reproducing what was taught in class.
A Macro- and Micro-Hierarchical Transfer Learning Framework for Cross-Domain Fake News Detection
Feb 20, 2025



Cross-domain fake news detection aims to mitigate domain shift and improve detection performance by transferring knowledge across domains. Existing approaches transfer knowledge based on news content and user engagements from a source domain to a target domain. However, these approaches face two main limitations, hindering effective knowledge transfer and optimal fake news detection performance. Firstly, from a micro perspective, they neglect the negative impact of veracity-irrelevant features in news content when transferring domain-shared features across domains. Secondly, from a macro perspective, existing approaches ignore the relationship between user engagement and news content, which reveals shared behaviors of common users across domains and can facilitate more effective knowledge transfer. To address these limitations, we propose a novel macro- and micro- hierarchical transfer learning framework (MMHT) for cross-domain fake news detection. Firstly, we propose a micro-hierarchical disentangling module to disentangle veracity-relevant and veracity-irrelevant features from news content in the source domain for improving fake news detection performance in the target domain. Secondly, we propose a macro-hierarchical transfer learning module to generate engagement features based on common users' shared behaviors in different domains for improving effectiveness of knowledge transfer. Extensive experiments on real-world datasets demonstrate that our framework significantly outperforms the state-of-the-art baselines.
MSVCOD:A Large-Scale Multi-Scene Dataset for Video Camouflage Object Detection
Feb 19, 2025



Video Camouflaged Object Detection (VCOD) is a challenging task which aims to identify objects that seamlessly concealed within the background in videos. The dynamic properties of video enable detection of camouflaged objects through motion cues or varied perspectives. Previous VCOD datasets primarily contain animal objects, limiting the scope of research to wildlife scenarios. However, the applications of VCOD extend beyond wildlife and have significant implications in security, art, and medical fields. Addressing this problem, we construct a new large-scale multi-domain VCOD dataset MSVCOD. To achieve high-quality annotations, we design a semi-automatic iterative annotation pipeline that reduces costs while maintaining annotation accuracy. Our MSVCOD is the largest VCOD dataset to date, introducing multiple object categories including human, animal, medical, and vehicle objects for the first time, while also expanding background diversity across various environments. This expanded scope increases the practical applicability of the VCOD task in camouflaged object detection. Alongside this dataset, we introduce a one-steam video camouflage object detection model that performs both feature extraction and information fusion without additional motion feature fusion modules. Our framework achieves state-of-the-art results on the existing VCOD animal dataset and the proposed MSVCOD. The dataset and code will be made publicly available.
Low-Complexity Cooperative Payload Transportation for Nonholonomic Mobile Robots Under Scalable Constraints
Feb 19, 2025Cooperative transportation, a key aspect of logistics cyber-physical systems (CPS), is typically approached using dis tributed control and optimization-based methods. The distributed control methods consume less time, but poorly handle and extend to multiple constraints. Instead, optimization-based methods handle constraints effectively, but they are usually centralized, time-consuming and thus not easily scalable to numerous robots. To overcome drawbacks of both, we propose a novel cooperative transportation method for nonholonomic mobile robots by im proving conventional formation control, which is distributed, has a low time-complexity and accommodates scalable constraints. The proposed control-based method is testified on a cable suspended payload and divided into two parts, including robot trajectory generation and trajectory tracking. Unlike most time consuming trajectory generation methods, ours can generate trajectories with only constant time-complexity, needless of global maps. As for trajectory tracking, our control-based method not only scales easily to multiple constraints as those optimization based methods, but reduces their time-complexity from poly nomial to linear. Simulations and experiments can verify the feasibility of our method.
Component-aware Unsupervised Logical Anomaly Generation for Industrial Anomaly Detection
Feb 17, 2025



Anomaly detection is critical in industrial manufacturing for ensuring product quality and improving efficiency in automated processes. The scarcity of anomalous samples limits traditional detection methods, making anomaly generation essential for expanding the data repository. However, recent generative models often produce unrealistic anomalies increasing false positives, or require real-world anomaly samples for training. In this work, we treat anomaly generation as a compositional problem and propose ComGEN, a component-aware and unsupervised framework that addresses the gap in logical anomaly generation. Our method comprises a multi-component learning strategy to disentangle visual components, followed by subsequent generation editing procedures. Disentangled text-to-component pairs, revealing intrinsic logical constraints, conduct attention-guided residual mapping and model training with iteratively matched references across multiple scales. Experiments on the MVTecLOCO dataset confirm the efficacy of ComGEN, achieving the best AUROC score of 91.2%. Additional experiments on the real-world scenario of Diesel Engine and widely-used MVTecAD dataset demonstrate significant performance improvements when integrating simulated anomalies generated by ComGEN into automated production workflows.
Visual-based spatial audio generation system for multi-speaker environments
Feb 13, 2025



In multimedia applications such as films and video games, spatial audio techniques are widely employed to enhance user experiences by simulating 3D sound: transforming mono audio into binaural formats. However, this process is often complex and labor-intensive for sound designers, requiring precise synchronization of audio with the spatial positions of visual components. To address these challenges, we propose a visual-based spatial audio generation system - an automated system that integrates face detection YOLOv8 for object detection, monocular depth estimation, and spatial audio techniques. Notably, the system operates without requiring additional binaural dataset training. The proposed system is evaluated against existing Spatial Audio generation system using objective metrics. Experimental results demonstrate that our method significantly improves spatial consistency between audio and video, enhances speech quality, and performs robustly in multi-speaker scenarios. By streamlining the audio-visual alignment process, the proposed system enables sound engineers to achieve high-quality results efficiently, making it a valuable tool for professionals in multimedia production.