 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText-based Aerial-Ground Person Retrieval
Nov 11, 2025This work introduces Text-based Aerial-Ground Person Retrieval (TAG-PR), which aims to retrieve person images from heterogeneous aerial and ground views with textual descriptions. Unlike traditional Text-based Person Retrieval (T-PR), which focuses solely on ground-view images, TAG-PR introduces greater practical significance and presents unique challenges due to the large viewpoint discrepancy across images. To support this task, we contribute: (1) TAG-PEDES dataset, constructed from public benchmarks with automatically generated textual descriptions, enhanced by a diversified text generation paradigm to ensure robustness under view heterogeneity; and (2) TAG-CLIP, a novel retrieval framework that addresses view heterogeneity through a hierarchically-routed mixture of experts module to learn view-specific and view-agnostic features and a viewpoint decoupling strategy to decouple view-specific features for better cross-modal alignment. We evaluate the effectiveness of TAG-CLIP on both the proposed TAG-PEDES dataset and existing T-PR benchmarks. The dataset and code are available at https://github.com/Flame-Chasers/TAG-PR.
Kimi Linear: An Expressive, Efficient Attention Architecture
Oct 30, 2025We introduce Kimi Linear, a hybrid linear attention architecture that, for the first time, outperforms full attention under fair comparisons across various scenarios -- including short-context, long-context, and reinforcement learning (RL) scaling regimes. At its core lies Kimi Delta Attention (KDA), an expressive linear attention module that extends Gated DeltaNet with a finer-grained gating mechanism, enabling more effective use of limited finite-state RNN memory. Our bespoke chunkwise algorithm achieves high hardware efficiency through a specialized variant of the Diagonal-Plus-Low-Rank (DPLR) transition matrices, which substantially reduces computation compared to the general DPLR formulation while remaining more consistent with the classical delta rule. We pretrain a Kimi Linear model with 3B activated parameters and 48B total parameters, based on a layerwise hybrid of KDA and Multi-Head Latent Attention (MLA). Our experiments show that with an identical training recipe, Kimi Linear outperforms full MLA with a sizeable margin across all evaluated tasks, while reducing KV cache usage by up to 75% and achieving up to 6 times decoding throughput for a 1M context. These results demonstrate that Kimi Linear can be a drop-in replacement for full attention architectures with superior performance and efficiency, including tasks with longer input and output lengths. To support further research, we open-source the KDA kernel and vLLM implementations, and release the pre-trained and instruction-tuned model checkpoints.
FieldGen: From Teleoperated Pre-Manipulation Trajectories to Field-Guided Data Generation
Oct 23, 2025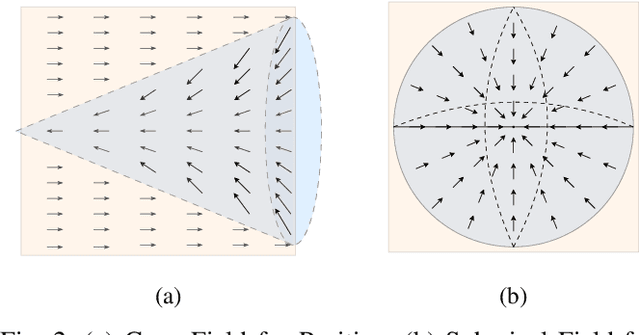

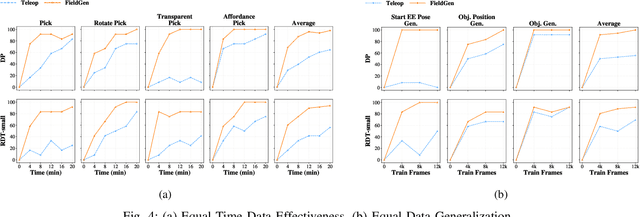

Large-scale and diverse datasets are vital for training robust robotic manipulation policies, yet existing data collection methods struggle to balance scale, diversity, and quality. Simulation offers scalability but suffers from sim-to-real gaps, while teleoperation yields high-quality demonstrations with limited diversity and high labor cost. We introduce FieldGen, a field-guided data generation framework that enables scalable, diverse, and high-quality real-world data collection with minimal human supervision. FieldGen decomposes manipulation into two stages: a pre-manipulation phase, allowing trajectory diversity, and a fine manipulation phase requiring expert precision. Human demonstrations capture key contact and pose information, after which an attraction field automatically generates diverse trajectories converging to successful configurations. This decoupled design combines scalable trajectory diversity with precise supervision. Moreover, FieldGen-Reward augments generated data with reward annotations to further enhance policy learning. Experiments demonstrate that policies trained with FieldGen achieve higher success rates and improved stability compared to teleoperation-based baselines, while significantly reducing human effort in long-term real-world data collection. Webpage is available at https://fieldgen.github.io/.
Marine Chlorophyll Prediction and Driver Analysis based on LSTM-RF Hybrid Models
Aug 07, 2025Marine chlorophyll concentration is an important indicator of ecosystem health and carbon cycle strength, and its accurate prediction is crucial for red tide warning and ecological response. In this paper, we propose a LSTM-RF hybrid model that combines the advantages of LSTM and RF, which solves the deficiencies of a single model in time-series modelling and nonlinear feature portrayal. Trained with multi-source ocean data(temperature, salinity, dissolved oxygen, etc.), the experimental results show that the LSTM-RF model has an R^2 of 0.5386, an MSE of 0.005806, and an MAE of 0.057147 on the test set, which is significantly better than using LSTM (R^2 = 0.0208) and RF (R^2 =0.4934) alone , respectively. The standardised treatment and sliding window approach improved the prediction accuracy of the model and provided an innovative solution for high-frequency prediction of marine ecological variables.
Kimi K2: Open Agentic Intelligence
Jul 28, 2025



We introduce Kimi K2, a Mixture-of-Experts (MoE) large language model with 32 billion activated parameters and 1 trillion total parameters. We propose the MuonClip optimizer, which improves upon Muon with a novel QK-clip technique to address training instability while enjoying the advanced token efficiency of Muon. Based on MuonClip, K2 was pre-trained on 15.5 trillion tokens with zero loss spike. During post-training, K2 undergoes a multi-stage post-training process, highlighted by a large-scale agentic data synthesis pipeline and a joint reinforcement learning (RL) stage, where the model improves its capabilities through interactions with real and synthetic environments. Kimi K2 achieves state-of-the-art performance among open-source non-thinking models, with strengths in agentic capabilities. Notably, K2 obtains 66.1 on Tau2-Bench, 76.5 on ACEBench (En), 65.8 on SWE-Bench Verified, and 47.3 on SWE-Bench Multilingual -- surpassing most open and closed-sourced baselines in non-thinking settings. It also exhibits strong capabilities in coding, mathematics, and reasoning tasks, with a score of 53.7 on LiveCodeBench v6, 49.5 on AIME 2025, 75.1 on GPQA-Diamond, and 27.1 on OJBench, all without extended thinking. These results position Kimi K2 as one of the most capable open-source large language models to date, particularly in software engineering and agentic tasks. We release our base and post-trained model checkpoints to facilitate future research and applications of agentic intelligence.
Private Model Personalization Revisited
Jun 24, 2025We study model personalization under user-level differential privacy (DP) in the shared representation framework. In this problem, there are $n$ users whose data is statistically heterogeneous, and their optimal parameters share an unknown embedding $U^* \in\mathbb{R}^{d\times k}$ that maps the user parameters in $\mathbb{R}^d$ to low-dimensional representations in $\mathbb{R}^k$, where $k\ll d$. Our goal is to privately recover the shared embedding and the local low-dimensional representations with small excess risk in the federated setting. We propose a private, efficient federated learning algorithm to learn the shared embedding based on the FedRep algorithm in [CHM+21]. Unlike [CHM+21], our algorithm satisfies differential privacy, and our results hold for the case of noisy labels. In contrast to prior work on private model personalization [JRS+21], our utility guarantees hold under a larger class of users' distributions (sub-Gaussian instead of Gaussian distributions). Additionally, in natural parameter regimes, we improve the privacy error term in [JRS+21] by a factor of $\widetilde{O}(dk)$. Next, we consider the binary classification setting. We present an information-theoretic construction to privately learn the shared embedding and derive a margin-based accuracy guarantee that is independent of $d$. Our method utilizes the Johnson-Lindenstrauss transform to reduce the effective dimensions of the shared embedding and the users' data. This result shows that dimension-independent risk bounds are possible in this setting under a margin loss.
VideoReasonBench: Can MLLMs Perform Vision-Centric Complex Video Reasoning?
May 29, 2025Recent studies have shown that long chain-of-thought (CoT) reasoning can significantly enhance the performance of large language models (LLMs) on complex tasks. However, this benefit is yet to be demonstrated in the domain of video understanding, since most existing benchmarks lack the reasoning depth required to demonstrate the advantages of extended CoT chains. While recent efforts have proposed benchmarks aimed at video reasoning, the tasks are often knowledge-driven and do not rely heavily on visual content. To bridge this gap, we introduce VideoReasonBench, a benchmark designed to evaluate vision-centric, complex video reasoning. To ensure visual richness and high reasoning complexity, each video in VideoReasonBench depicts a sequence of fine-grained operations on a latent state that is only visible in part of the video. The questions evaluate three escalating levels of video reasoning skills: recalling observed visual information, inferring the content of latent states, and predicting information beyond the video. Under such task setting, models have to precisely recall multiple operations in the video, and perform step-by-step reasoning to get correct final answers for these questions. Using VideoReasonBench, we comprehensively evaluate 18 state-of-the-art multimodal LLMs (MLLMs), finding that most perform poorly on complex video reasoning, e.g., GPT-4o achieves only 6.9% accuracy, while the thinking-enhanced Gemini-2.5-Pro significantly outperforms others with 56.0% accuracy. Our investigations on "test-time scaling" further reveal that extended thinking budget, while offering none or minimal benefits on existing video benchmarks, is essential for improving the performance on VideoReasonBench.
G1: Bootstrapping Perception and Reasoning Abilities of Vision-Language Model via Reinforcement Learning
May 19, 2025



Vision-Language Models (VLMs) excel in many direct multimodal tasks but struggle to translate this prowess into effective decision-making within interactive, visually rich environments like games. This ``knowing-doing'' gap significantly limits their potential as autonomous agents, as leading VLMs often performing badly in simple games. To address this, we introduce VLM-Gym, a curated reinforcement learning (RL) environment featuring diverse visual games with unified interfaces and adjustable, compositional difficulty, specifically designed for scalable multi-game parallel training. Leveraging VLM-Gym, we train G0 models using pure RL-driven self-evolution, which demonstrate emergent perception and reasoning patterns. To further mitigate challenges arising from game diversity, we develop G1 models. G1 incorporates a perception-enhanced cold start prior to RL fine-tuning. Our resulting G1 models consistently surpass their teacher across all games and outperform leading proprietary models like Claude-3.7-Sonnet-Thinking. Systematic analysis reveals an intriguing finding: perception and reasoning abilities mutually bootstrap each other throughout the RL training process. Source code including VLM-Gym and RL training are released at https://github.com/chenllliang/G1 to foster future research in advancing VLMs as capable interactive agents.
Private Transformer Inference in MLaaS: A Survey
May 15, 2025Transformer models have revolutionized AI, powering applications like content generation and sentiment analysis. However, their deployment in Machine Learning as a Service (MLaaS) raises significant privacy concerns, primarily due to the centralized processing of sensitive user data. Private Transformer Inference (PTI) offers a solution by utilizing cryptographic techniques such as secure multi-party computation and homomorphic encryption, enabling inference while preserving both user data and model privacy. This paper reviews recent PTI advancements, highlighting state-of-the-art solutions and challenges. We also introduce a structured taxonomy and evaluation framework for PTI, focusing on balancing resource efficiency with privacy and bridging the gap between high-performance inference and data privacy.
Kimi-Audio Technical Report
Apr 25, 2025
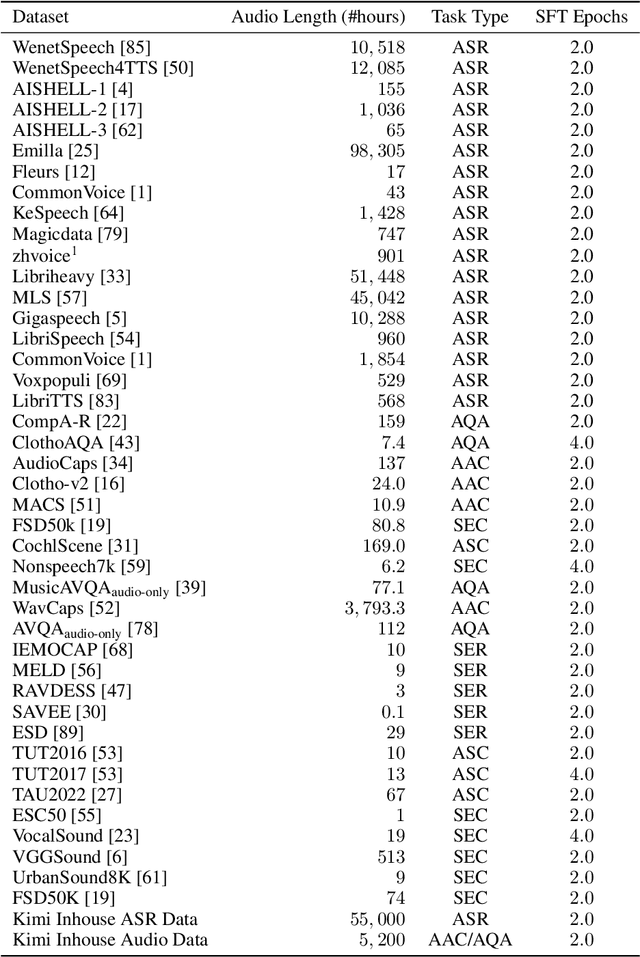
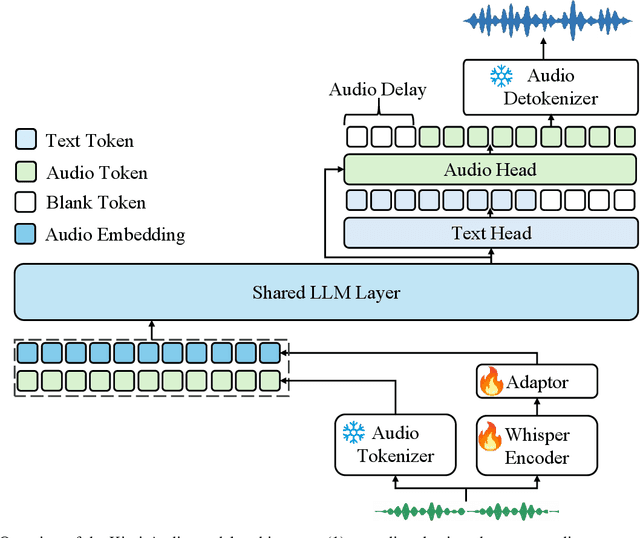
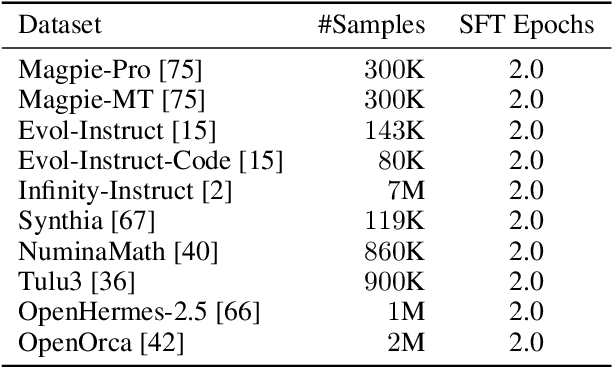
We present Kimi-Audio, an open-source audio foundation model that excels in audio understanding, generation, and conversation. We detail the practices in building Kimi-Audio, including model architecture, data curation, training recipe, inference deployment, and evaluation. Specifically, we leverage a 12.5Hz audio tokenizer, design a novel LLM-based architecture with continuous features as input and discrete tokens as output, and develop a chunk-wise streaming detokenizer based on flow matching. We curate a pre-training dataset that consists of more than 13 million hours of audio data covering a wide range of modalities including speech, sound, and music, and build a pipeline to construct high-quality and diverse post-training data. Initialized from a pre-trained LLM, Kimi-Audio is continual pre-trained on both audio and text data with several carefully designed tasks, and then fine-tuned to support a diverse of audio-related tasks. Extensive evaluation shows that Kimi-Audio achieves state-of-the-art performance on a range of audio benchmarks including speech recognition, audio understanding, audio question answering, and speech conversation. We release the codes, model checkpoints, as well as the evaluation toolkits in https://github.com/MoonshotAI/Kimi-Audio.