 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Robustness of Machine Unlearning for Vision-Language Models
May 26, 2026Vision-language models (VLMs) may memorize undesirable information from training data, motivating growing interest in machine unlearning. In this work, we present the first systematic survey and robustness analysis of VLM unlearning. We provide a comprehensive taxonomy and review of existing VLM unlearning methods, together with unified evaluations under multiple prompt settings. We then propose three attack paradigms to examine whether forgotten multimodal knowledge can be reactivated through contextual prompting or downstream retraining. Extensive experiments show that many existing methods remain vulnerable under these attacks, indicating that current approaches often hide rather than fully remove target knowledge. Our study provides new insights into the robustness and limitations of current VLM unlearning methods and highlights the need for more reliable multimodal unlearning strategies. Code is available at https://github.com/XMUDeepLIT/VLM-UnL-Attack.
ExPosST: Explicit Positioning with Adaptive Masking for LLM-Based Simultaneous Machine Translation
Mar 16, 2026Large language models (LLMs) have recently demonstrated promising performance in simultaneous machine translation (SimulMT). However, applying decoder-only LLMs to SimulMT introduces a positional mismatch, which leads to a dilemma between decoding efficiency and positional consistency. Existing approaches often rely on specific positional encodings or carefully designed prompting schemes, and thus fail to simultaneously achieve inference efficiency, positional consistency, and broad model compatibility. In this work, we propose ExPosST, a general framework that resolves this dilemma through explicit position allocation. ExPosST reserves fixed positional slots for incoming source tokens, enabling efficient decoding with KV cache across different positional encoding methods. To further bridge the gap between fine-tuning and inference, we introduce a policy-consistent fine-tuning strategy that aligns training with inference-time decoding behavior. Experiments across multiple language pairs demonstrate that ExPosST effectively supports simultaneous translation under diverse policies.
RoboClaw: An Agentic Framework for Scalable Long-Horizon Robotic Tasks
Mar 12, 2026Vision-Language-Action (VLA) systems have shown strong potential for language-driven robotic manipulation. However, scaling them to long-horizon tasks remains challenging. Existing pipelines typically separate data collection, policy learning, and deployment, resulting in heavy reliance on manual environment resets and brittle multi-policy execution. We present RoboClaw, an agentic robotics framework that unifies data collection, policy learning, and task execution under a single VLM-driven controller. At the policy level, RoboClaw introduces Entangled Action Pairs (EAP), which couple forward manipulation behaviors with inverse recovery actions to form self-resetting loops for autonomous data collection. This mechanism enables continuous on-policy data acquisition and iterative policy refinement with minimal human intervention. During deployment, the same agent performs high-level reasoning and dynamically orchestrates learned policy primitives to accomplish long-horizon tasks. By maintaining consistent contextual semantics across collection and execution, RoboClaw reduces mismatch between the two phases and improves multi-policy robustness. Experiments in real-world manipulation tasks demonstrate improved stability and scalability compared to conventional open-loop pipelines, while significantly reducing human effort throughout the robot lifecycle, achieving a 25% improvement in success rate over baseline methods on long-horizon tasks and reducing human time investment by 53.7%.
Text-based Aerial-Ground Person Retrieval
Nov 11, 2025This work introduces Text-based Aerial-Ground Person Retrieval (TAG-PR), which aims to retrieve person images from heterogeneous aerial and ground views with textual descriptions. Unlike traditional Text-based Person Retrieval (T-PR), which focuses solely on ground-view images, TAG-PR introduces greater practical significance and presents unique challenges due to the large viewpoint discrepancy across images. To support this task, we contribute: (1) TAG-PEDES dataset, constructed from public benchmarks with automatically generated textual descriptions, enhanced by a diversified text generation paradigm to ensure robustness under view heterogeneity; and (2) TAG-CLIP, a novel retrieval framework that addresses view heterogeneity through a hierarchically-routed mixture of experts module to learn view-specific and view-agnostic features and a viewpoint decoupling strategy to decouple view-specific features for better cross-modal alignment. We evaluate the effectiveness of TAG-CLIP on both the proposed TAG-PEDES dataset and existing T-PR benchmarks. The dataset and code are available at https://github.com/Flame-Chasers/TAG-PR.
Genie Centurion: Accelerating Scalable Real-World Robot Training with Human Rewind-and-Refine Guidance
May 24, 2025



While Vision-Language-Action (VLA) models show strong generalizability in various tasks, real-world deployment of robotic policy still requires large-scale, high-quality human expert demonstrations. However, passive data collection via human teleoperation is costly, hard to scale, and often biased toward passive demonstrations with limited diversity. To address this, we propose Genie Centurion (GCENT), a scalable and general data collection paradigm based on human rewind-and-refine guidance. When the robot execution failures occur, GCENT enables the system revert to a previous state with a rewind mechanism, after which a teleoperator provides corrective demonstrations to refine the policy. This framework supports a one-human-to-many-robots supervision scheme with a Task Sentinel module, which autonomously predicts task success and solicits human intervention when necessary, enabling scalable supervision. Empirical results show that GCENT achieves up to 40% higher task success rates than state-of-the-art data collection methods, and reaches comparable performance using less than half the data. We also quantify the data yield-to-effort ratio under multi-robot scenarios, demonstrating GCENT's potential for scalable and cost-efficient robot policy training in real-world environments.
Multimodal Large Language Models for Text-rich Image Understanding: A Comprehensive Review
Feb 23, 2025


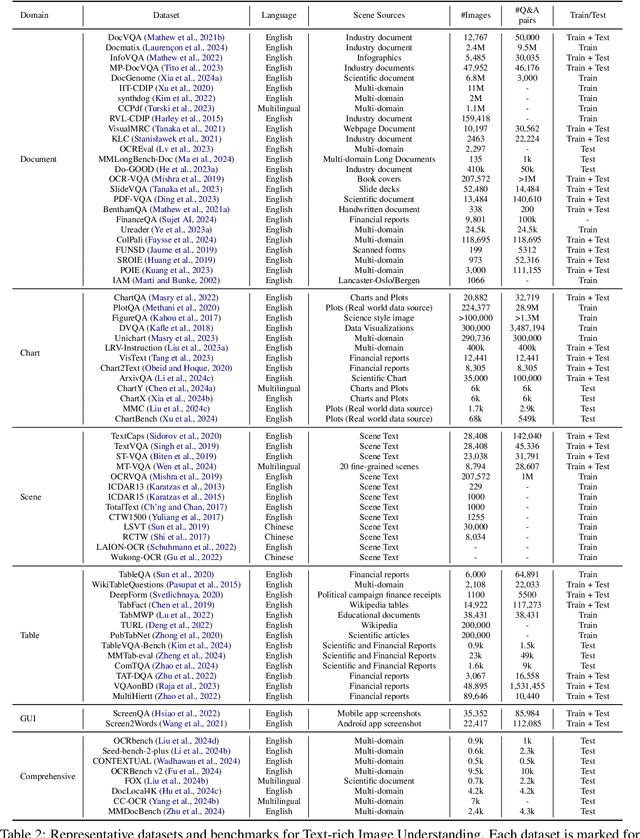
The recent emergence of Multi-modal Large Language Models (MLLMs) has introduced a new dimension to the Text-rich Image Understanding (TIU) field, with models demonstrating impressive and inspiring performance. However, their rapid evolution and widespread adoption have made it increasingly challenging to keep up with the latest advancements. To address this, we present a systematic and comprehensive survey to facilitate further research on TIU MLLMs. Initially, we outline the timeline, architecture, and pipeline of nearly all TIU MLLMs. Then, we review the performance of selected models on mainstream benchmarks. Finally, we explore promising directions, challenges, and limitations within the field.