 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHiCAST: Highly Customized Arbitrary Style Transfer with Adapter Enhanced Diffusion Models
Jan 11, 2024



The goal of Arbitrary Style Transfer (AST) is injecting the artistic features of a style reference into a given image/video. Existing methods usually focus on pursuing the balance between style and content, whereas ignoring the significant demand for flexible and customized stylization results and thereby limiting their practical application. To address this critical issue, a novel AST approach namely HiCAST is proposed, which is capable of explicitly customizing the stylization results according to various source of semantic clues. In the specific, our model is constructed based on Latent Diffusion Model (LDM) and elaborately designed to absorb content and style instance as conditions of LDM. It is characterized by introducing of \textit{Style Adapter}, which allows user to flexibly manipulate the output results by aligning multi-level style information and intrinsic knowledge in LDM. Lastly, we further extend our model to perform video AST. A novel learning objective is leveraged for video diffusion model training, which significantly improve cross-frame temporal consistency in the premise of maintaining stylization strength. Qualitative and quantitative comparisons as well as comprehensive user studies demonstrate that our HiCAST outperforms the existing SoTA methods in generating visually plausible stylization results.
Exploiting Diffusion Priors for All-in-One Image Restoration
Dec 02, 2023



All-in-one aims to solve various tasks of image restoration in a single model. To this end, we present a feasible way of exploiting the image priors captured by the pretrained diffusion model, through addressing the two challenges, i.e., degradation modeling and diffusion guidance. The former aims to simulate the process of the clean image degenerated by certain degradations, and the latter aims at guiding the diffusion model to generate the corresponding clean image. With the motivations, we propose a zero-shot framework for all-in-one image restoration, termed ZeroAIR, which alternatively performs the test-time degradation modeling (TDM) and the three-stage diffusion guidance (TDG) at each timestep of the reverse sampling. To be specific, TDM exploits the diffusion priors to learn a degradation model from a given degraded image, and TDG divides the timesteps into three stages for taking full advantage of the varying diffusion priors. Thanks to their degradation-agnostic property, the all-in-one image restoration could be achieved in a zero-shot way by ZeroAIR. Through extensive experiments, we show that our ZeroAIR achieves comparable even better performance than those task-specific methods. The code will be available on Github.
UNIMO-3: Multi-granularity Interaction for Vision-Language Representation Learning
May 23, 2023



Vision-and-language (VL) pre-training, which aims to learn a general representation of image-text pairs that can be transferred to various vision-and-language tasks. Compared with modeling uni-modal data, the main challenge of the VL model is: how to learn the cross-modal interaction from multimodal data, especially the fine-grained interaction. Existing works have shown that fully transformer-based models that adopt attention mechanisms to learn in-layer cross-model interaction can demonstrate impressive performance on various cross-modal downstream tasks. However, they ignored that the semantic information of the different modals at the same layer was not uniform, which leads to the cross-modal interaction collapsing into a limited multi-modal semantic information interaction. In this work, we propose the UNIMO-3 model, which has the capacity to simultaneously learn the multimodal in-layer interaction and cross-layer interaction. UNIMO-3 model can establish effective connections between different layers in a cross-modal encoder, and adaptively capture the interaction between two modalities at different levels. The experimental results show that our model achieves state-of-the-art performance in various downstream tasks, and through ablation study can prove that effective cross-layer learning improves the model's ability of multimodal representation.
WeCheck: Strong Factual Consistency Checker via Weakly Supervised Learning
Dec 20, 2022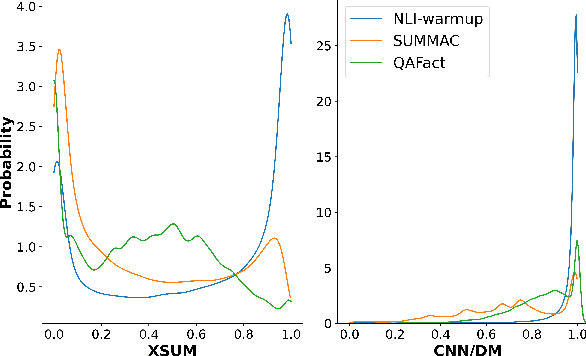
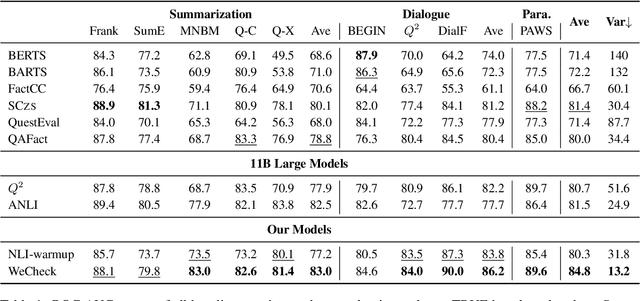
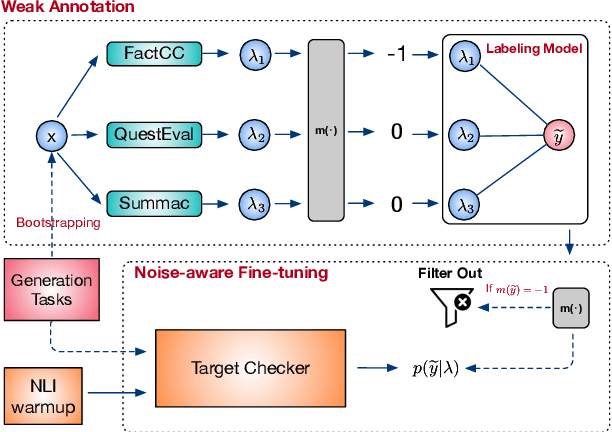
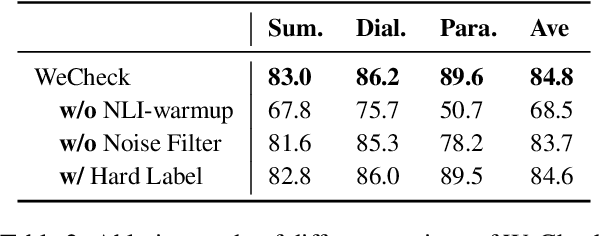
A crucial issue of current text generation models is that they often uncontrollably generate factually inconsistent text with respective of their inputs. Limited by the lack of annotated data, existing works in evaluating factual consistency directly transfer the reasoning ability of models trained on other data-rich upstream tasks like question answering (QA) and natural language inference (NLI) without any further adaptation. As a result, they perform poorly on the real generated text and are biased heavily by their single-source upstream tasks. To alleviate this problem, we propose a weakly supervised framework that aggregates multiple resources to train a precise and efficient factual metric, namely WeCheck. WeCheck first utilizes a generative model to accurately label a real generated sample by aggregating its weak labels, which are inferred from multiple resources. Then, we train the target metric model with the weak supervision while taking noises into consideration. Comprehensive experiments on a variety of tasks demonstrate the strong performance of WeCheck, which achieves a 3.4\% absolute improvement over previous state-of-the-art methods on TRUE benchmark on average.
UPainting: Unified Text-to-Image Diffusion Generation with Cross-modal Guidance
Nov 03, 2022



Diffusion generative models have recently greatly improved the power of text-conditioned image generation. Existing image generation models mainly include text conditional diffusion model and cross-modal guided diffusion model, which are good at small scene image generation and complex scene image generation respectively. In this work, we propose a simple yet effective approach, namely UPainting, to unify simple and complex scene image generation, as shown in Figure 1. Based on architecture improvements and diverse guidance schedules, UPainting effectively integrates cross-modal guidance from a pretrained image-text matching model into a text conditional diffusion model that utilizes a pretrained Transformer language model as the text encoder. Our key findings is that combining the power of large-scale Transformer language model in understanding language and image-text matching model in capturing cross-modal semantics and style, is effective to improve sample fidelity and image-text alignment of image generation. In this way, UPainting has a more general image generation capability, which can generate images of both simple and complex scenes more effectively. To comprehensively compare text-to-image models, we further create a more general benchmark, UniBench, with well-written Chinese and English prompts in both simple and complex scenes. We compare UPainting with recent models and find that UPainting greatly outperforms other models in terms of caption similarity and image fidelity in both simple and complex scenes. UPainting project page \url{https://upainting.github.io/}.
FRSUM: Towards Faithful Abstractive Summarization via Enhancing Factual Robustness
Nov 01, 2022Despite being able to generate fluent and grammatical text, current Seq2Seq summarization models still suffering from the unfaithful generation problem. In this paper, we study the faithfulness of existing systems from a new perspective of factual robustness which is the ability to correctly generate factual information over adversarial unfaithful information. We first measure a model's factual robustness by its success rate to defend against adversarial attacks when generating factual information. The factual robustness analysis on a wide range of current systems shows its good consistency with human judgments on faithfulness. Inspired by these findings, we propose to improve the faithfulness of a model by enhancing its factual robustness. Specifically, we propose a novel training strategy, namely FRSUM, which teaches the model to defend against both explicit adversarial samples and implicit factual adversarial perturbations. Extensive automatic and human evaluation results show that FRSUM consistently improves the faithfulness of various Seq2Seq models, such as T5, BART.
SeSQL: Yet Another Large-scale Session-level Chinese Text-to-SQL Dataset
Aug 26, 2022
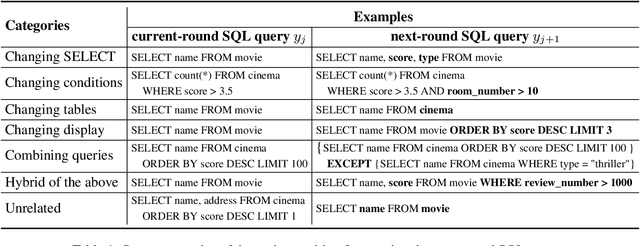
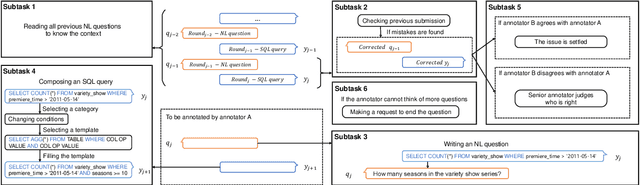
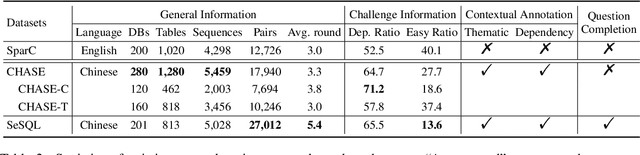
As the first session-level Chinese dataset, CHASE contains two separate parts, i.e., 2,003 sessions manually constructed from scratch (CHASE-C), and 3,456 sessions translated from English SParC (CHASE-T). We find the two parts are highly discrepant and incompatible as training and evaluation data. In this work, we present SeSQL, yet another large-scale session-level text-to-SQL dataset in Chinese, consisting of 5,028 sessions all manually constructed from scratch. In order to guarantee data quality, we adopt an iterative annotation workflow to facilitate intense and in-time review of previous-round natural language (NL) questions and SQL queries. Moreover, by completing all context-dependent NL questions, we obtain 27,012 context-independent question/SQL pairs, allowing SeSQL to be used as the largest dataset for single-round multi-DB text-to-SQL parsing. We conduct benchmark session-level text-to-SQL parsing experiments on SeSQL by employing three competitive session-level parsers, and present detailed analysis.
An Interpretability Evaluation Benchmark for Pre-trained Language Models
Jul 28, 2022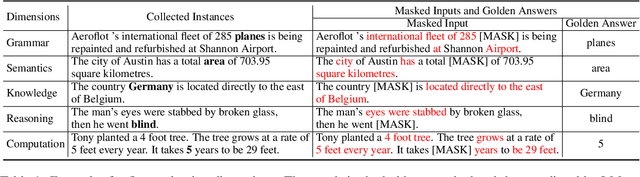
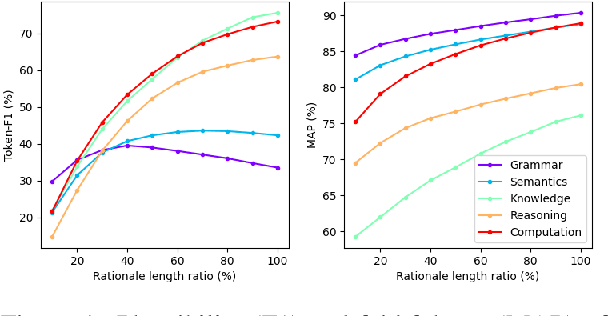

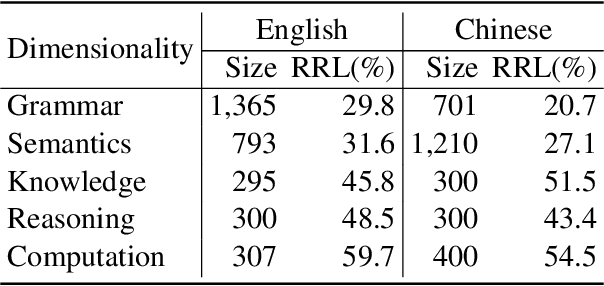
While pre-trained language models (LMs) have brought great improvements in many NLP tasks, there is increasing attention to explore capabilities of LMs and interpret their predictions. However, existing works usually focus only on a certain capability with some downstream tasks. There is a lack of datasets for directly evaluating the masked word prediction performance and the interpretability of pre-trained LMs. To fill in the gap, we propose a novel evaluation benchmark providing with both English and Chinese annotated data. It tests LMs abilities in multiple dimensions, i.e., grammar, semantics, knowledge, reasoning and computation. In addition, it provides carefully annotated token-level rationales that satisfy sufficiency and compactness. It contains perturbed instances for each original instance, so as to use the rationale consistency under perturbations as the metric for faithfulness, a perspective of interpretability. We conduct experiments on several widely-used pre-trained LMs. The results show that they perform very poorly on the dimensions of knowledge and computation. And their plausibility in all dimensions is far from satisfactory, especially when the rationale is short. In addition, the pre-trained LMs we evaluated are not robust on syntax-aware data. We will release this evaluation benchmark at \url{http://xyz}, and hope it can facilitate the research progress of pre-trained LMs.
A Fine-grained Interpretability Evaluation Benchmark for Neural NLP
May 23, 2022
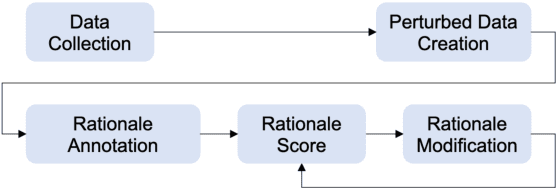
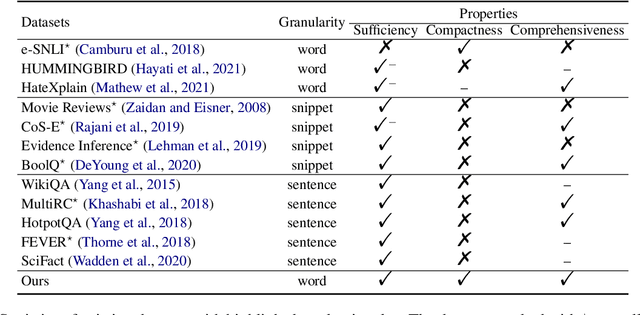
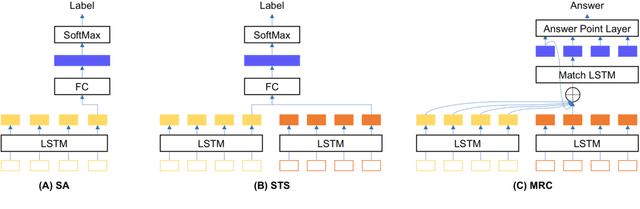
While there is increasing concern about the interpretability of neural models, the evaluation of interpretability remains an open problem, due to the lack of proper evaluation datasets and metrics. In this paper, we present a novel benchmark to evaluate the interpretability of both neural models and saliency methods. This benchmark covers three representative NLP tasks: sentiment analysis, textual similarity and reading comprehension, each provided with both English and Chinese annotated data. In order to precisely evaluate the interpretability, we provide token-level rationales that are carefully annotated to be sufficient, compact and comprehensive. We also design a new metric, i.e., the consistency between the rationales before and after perturbations, to uniformly evaluate the interpretability of models and saliency methods on different tasks. Based on this benchmark, we conduct experiments on three typical models with three saliency methods, and unveil their strengths and weakness in terms of interpretability. We will release this benchmark at \url{https://xyz} and hope it can facilitate the research in building trustworthy systems.
Faster and Better Grammar-based Text-to-SQL Parsing via Clause-level Parallel Decoding and Alignment Loss
Apr 26, 2022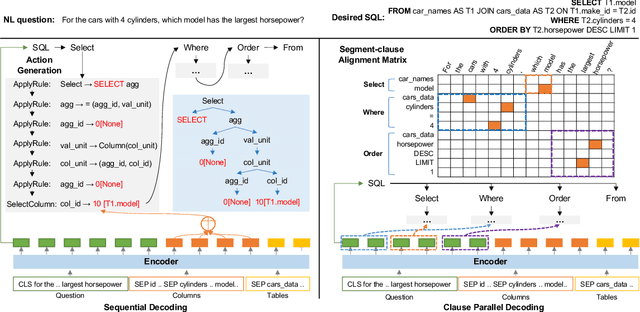
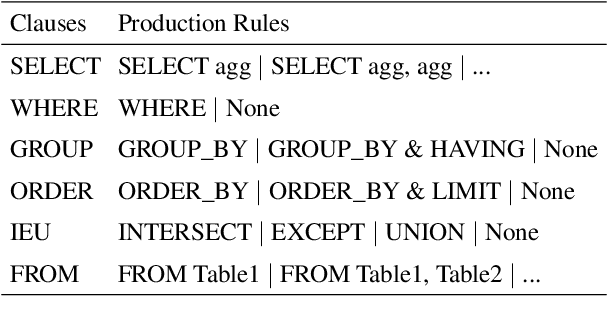
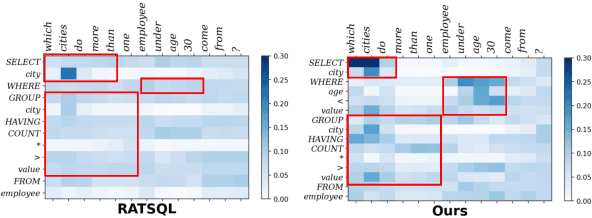

Grammar-based parsers have achieved high performance in the cross-domain text-to-SQL parsing task, but suffer from low decoding efficiency due to the much larger number of actions for grammar selection than that of tokens in SQL queries. Meanwhile, how to better align SQL clauses and question segments has been a key challenge for parsing performance. Therefore, this paper proposes clause-level parallel decoding and alignment loss to enhance two high-performance grammar-based parsers, i.e., RATSQL and LGESQL. Experimental results of two parsers show that our method obtains consistent improvements both in accuracy and decoding speed.