 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOASIS: Observation-Action Space Alignment via SE(3) Trajectory Prediction for Robotic Manipulation
May 25, 2026Recent vision-language-action (VLA) models and world action models (WAMs) advance robotic manipulation by enriching intermediate representations with auxiliary spatial features or future visual-state prediction. However, these representations largely remain within the observation space and do not share the rigid-body geometry of the action space, forcing the action decoder to implicitly recover this geometry. We propose OASIS, a visuomotor policy that aligns the intermediate representation with the action space via $SE(3)$ end-effector trajectory prediction. OASIS couples a 3D-aware feature encoder that fuses vision-language and metric-depth features with an $SE(3)$ trajectory predictor that produces a camera-frame end-effector trajectory. Conditioned on the predictor's pose-supervised hidden states, the action decoder generates action chunks consistent with rigid-body motion. Across simulation and real-world experiments, OASIS outperforms VLA and WAM baselines in success rate and out-of-distribution generalization. Our project page is available at https://npuhandsome.github.io/OASIS_web.
AffordSim: A Scalable Data Generator and Benchmark for Affordance-Aware Robotic Manipulation
Apr 13, 2026Simulation-based data generation has become a dominant paradigm for training robotic manipulation policies, yet existing platforms do not incorporate object affordance information into trajectory generation. As a result, tasks requiring precise interaction with specific functional regions--grasping a mug by its handle, pouring from a cup's rim, or hanging a mug on a hook--cannot be automatically generated with semantically correct trajectories. We introduce AffordSim, the first simulation framework that integrates open-vocabulary 3D affordance prediction into the manipulation data generation pipeline. AffordSim uses our VoxAfford model, an open-vocabulary 3D affordance detector that enhances MLLM output tokens with multi-scale geometric features, to predict affordance maps on object point clouds, guiding grasp pose estimation toward task-relevant functional regions. Built on NVIDIA Isaac Sim with cross-embodiment support (Franka FR3, Panda, UR5e, Kinova), VLM-powered task generation, and novel domain randomization using DA3-based 3D Gaussian reconstruction from real photographs, AffordSim enables automated, scalable generation of affordance-aware manipulation data. We establish a benchmark of 50 tasks across 7 categories (grasping, placing, stacking, pushing/pulling, pouring, mug hanging, long-horizon composite) and evaluate 4 imitation learning baselines (BC, Diffusion Policy, ACT, Pi 0.5). Our results reveal that while grasping is largely solved (53-93% success), affordance-demanding tasks such as pouring into narrow containers (1-43%) and mug hanging (0-47%) remain significantly more challenging for current imitation learning methods, highlighting the need for affordance-aware data generation. Zero-shot sim-to-real experiments on a real Franka FR3 validate the transferability of the generated data.
Toward Reliable Sim-to-Real Predictability for MoE-based Robust Quadrupedal Locomotion
Jan 31, 2026Reinforcement learning has shown strong promise for quadrupedal agile locomotion, even with proprioception-only sensing. In practice, however, sim-to-real gap and reward overfitting in complex terrains can produce policies that fail to transfer, while physical validation remains risky and inefficient. To address these challenges, we introduce a unified framework encompassing a Mixture-of-Experts (MoE) locomotion policy for robust multi-terrain representation with RoboGauge, a predictive assessment suite that quantifies sim-to-real transferability. The MoE policy employs a gated set of specialist experts to decompose latent terrain and command modeling, achieving superior deployment robustness and generalization via proprioception alone. RoboGauge further provides multi-dimensional proprioception-based metrics via sim-to-sim tests over terrains, difficulty levels, and domain randomizations, enabling reliable MoE policy selection without extensive physical trials. Experiments on a Unitree Go2 demonstrate robust locomotion on unseen challenging terrains, including snow, sand, stairs, slopes, and 30 cm obstacles. In dedicated high-speed tests, the robot reaches 4 m/s and exhibits an emergent narrow-width gait associated with improved stability at high velocity.
UniLayDiff: A Unified Diffusion Transformer for Content-Aware Layout Generation
Dec 09, 2025



Content-aware layout generation is a critical task in graphic design automation, focused on creating visually appealing arrangements of elements that seamlessly blend with a given background image. The variety of real-world applications makes it highly challenging to develop a single model capable of unifying the diverse range of input-constrained generation sub-tasks, such as those conditioned by element types, sizes, or their relationships. Current methods either address only a subset of these tasks or necessitate separate model parameters for different conditions, failing to offer a truly unified solution. In this paper, we propose UniLayDiff: a Unified Diffusion Transformer, that for the first time, addresses various content-aware layout generation tasks with a single, end-to-end trainable model. Specifically, we treat layout constraints as a distinct modality and employ Multi-Modal Diffusion Transformer framework to capture the complex interplay between the background image, layout elements, and diverse constraints. Moreover, we integrate relation constraints through fine-tuning the model with LoRA after pretraining the model on other tasks. Such a schema not only achieves unified conditional generation but also enhances overall layout quality. Extensive experiments demonstrate that UniLayDiff achieves state-of-the-art performance across from unconditional to various conditional generation tasks and, to the best of our knowledge, is the first model to unify the full range of content-aware layout generation tasks.
MInCo: Mitigating Information Conflicts in Distracted Visual Model-based Reinforcement Learning
Apr 05, 2025


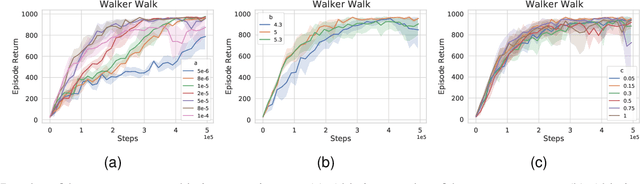
Existing visual model-based reinforcement learning (MBRL) algorithms with observation reconstruction often suffer from information conflicts, making it difficult to learn compact representations and hence result in less robust policies, especially in the presence of task-irrelevant visual distractions. In this paper, we first reveal that the information conflicts in current visual MBRL algorithms stem from visual representation learning and latent dynamics modeling with an information-theoretic perspective. Based on this finding, we present a new algorithm to resolve information conflicts for visual MBRL, named MInCo, which mitigates information conflicts by leveraging negative-free contrastive learning, aiding in learning invariant representation and robust policies despite noisy observations. To prevent the dominance of visual representation learning, we introduce time-varying reweighting to bias the learning towards dynamics modeling as training proceeds. We evaluate our method on several robotic control tasks with dynamic background distractions. Our experiments demonstrate that MInCo learns invariant representations against background noise and consistently outperforms current state-of-the-art visual MBRL methods. Code is available at https://github.com/ShiguangSun/minco.
LexRAG: Benchmarking Retrieval-Augmented Generation in Multi-Turn Legal Consultation Conversation
Feb 28, 2025Retrieval-augmented generation (RAG) has proven highly effective in improving large language models (LLMs) across various domains. However, there is no benchmark specifically designed to assess the effectiveness of RAG in the legal domain, which restricts progress in this area. To fill this gap, we propose LexRAG, the first benchmark to evaluate RAG systems for multi-turn legal consultations. LexRAG consists of 1,013 multi-turn dialogue samples and 17,228 candidate legal articles. Each sample is annotated by legal experts and consists of five rounds of progressive questioning. LexRAG includes two key tasks: (1) Conversational knowledge retrieval, requiring accurate retrieval of relevant legal articles based on multi-turn context. (2) Response generation, focusing on producing legally sound answers. To ensure reliable reproducibility, we develop LexiT, a legal RAG toolkit that provides a comprehensive implementation of RAG system components tailored for the legal domain. Additionally, we introduce an LLM-as-a-judge evaluation pipeline to enable detailed and effective assessment. Through experimental analysis of various LLMs and retrieval methods, we reveal the key limitations of existing RAG systems in handling legal consultation conversations. LexRAG establishes a new benchmark for the practical application of RAG systems in the legal domain, with its code and data available at https://github.com/CSHaitao/LexRAG.
Enhancing Decision Transformer with Diffusion-Based Trajectory Branch Generation
Nov 18, 2024



Decision Transformer (DT) can learn effective policy from offline datasets by converting the offline reinforcement learning (RL) into a supervised sequence modeling task, where the trajectory elements are generated auto-regressively conditioned on the return-to-go (RTG).However, the sequence modeling learning approach tends to learn policies that converge on the sub-optimal trajectories within the dataset, for lack of bridging data to move to better trajectories, even if the condition is set to the highest RTG.To address this issue, we introduce Diffusion-Based Trajectory Branch Generation (BG), which expands the trajectories of the dataset with branches generated by a diffusion model.The trajectory branch is generated based on the segment of the trajectory within the dataset, and leads to trajectories with higher returns.We concatenate the generated branch with the trajectory segment as an expansion of the trajectory.After expanding, DT has more opportunities to learn policies to move to better trajectories, preventing it from converging to the sub-optimal trajectories.Empirically, after processing with BG, DT outperforms state-of-the-art sequence modeling methods on D4RL benchmark, demonstrating the effectiveness of adding branches to the dataset without further modifications.
Grounded Answers for Multi-agent Decision-making Problem through Generative World Model
Oct 03, 2024



Recent progress in generative models has stimulated significant innovations in many fields, such as image generation and chatbots. Despite their success, these models often produce sketchy and misleading solutions for complex multi-agent decision-making problems because they miss the trial-and-error experience and reasoning as humans. To address this limitation, we explore a paradigm that integrates a language-guided simulator into the multi-agent reinforcement learning pipeline to enhance the generated answer. The simulator is a world model that separately learns dynamics and reward, where the dynamics model comprises an image tokenizer as well as a causal transformer to generate interaction transitions autoregressively, and the reward model is a bidirectional transformer learned by maximizing the likelihood of trajectories in the expert demonstrations under language guidance. Given an image of the current state and the task description, we use the world model to train the joint policy and produce the image sequence as the answer by running the converged policy on the dynamics model. The empirical results demonstrate that this framework can improve the answers for multi-agent decision-making problems by showing superior performance on the training and unseen tasks of the StarCraft Multi-Agent Challenge benchmark. In particular, it can generate consistent interaction sequences and explainable reward functions at interaction states, opening the path for training generative models of the future.
DexDiff: Towards Extrinsic Dexterity Manipulation of Ungraspable Objects in Unrestricted Environments
Sep 09, 2024



Grasping large and flat objects (e.g. a book or a pan) is often regarded as an ungraspable task, which poses significant challenges due to the unreachable grasping poses. Previous works leverage Extrinsic Dexterity like walls or table edges to grasp such objects. However, they are limited to task-specific policies and lack task planning to find pre-grasp conditions. This makes it difficult to adapt to various environments and extrinsic dexterity constraints. Therefore, we present DexDiff, a robust robotic manipulation method for long-horizon planning with extrinsic dexterity. Specifically, we utilize a vision-language model (VLM) to perceive the environmental state and generate high-level task plans, followed by a goal-conditioned action diffusion (GCAD) model to predict the sequence of low-level actions. This model learns the low-level policy from offline data with the cumulative reward guided by high-level planning as the goal condition, which allows for improved prediction of robot actions. Experimental results demonstrate that our method not only effectively performs ungraspable tasks but also generalizes to previously unseen objects. It outperforms baselines by a 47% higher success rate in simulation and facilitates efficient deployment and manipulation in real-world scenarios.
Imagine, Initialize, and Explore: An Effective Exploration Method in Multi-Agent Reinforcement Learning
Mar 01, 2024



Effective exploration is crucial to discovering optimal strategies for multi-agent reinforcement learning (MARL) in complex coordination tasks. Existing methods mainly utilize intrinsic rewards to enable committed exploration or use role-based learning for decomposing joint action spaces instead of directly conducting a collective search in the entire action-observation space. However, they often face challenges obtaining specific joint action sequences to reach successful states in long-horizon tasks. To address this limitation, we propose Imagine, Initialize, and Explore (IIE), a novel method that offers a promising solution for efficient multi-agent exploration in complex scenarios. IIE employs a transformer model to imagine how the agents reach a critical state that can influence each other's transition functions. Then, we initialize the environment at this state using a simulator before the exploration phase. We formulate the imagination as a sequence modeling problem, where the states, observations, prompts, actions, and rewards are predicted autoregressively. The prompt consists of timestep-to-go, return-to-go, influence value, and one-shot demonstration, specifying the desired state and trajectory as well as guiding the action generation. By initializing agents at the critical states, IIE significantly increases the likelihood of discovering potentially important under-explored regions. Despite its simplicity, empirical results demonstrate that our method outperforms multi-agent exploration baselines on the StarCraft Multi-Agent Challenge (SMAC) and SMACv2 environments. Particularly, IIE shows improved performance in the sparse-reward SMAC tasks and produces more effective curricula over the initialized states than other generative methods, such as CVAE-GAN and diffusion models.