 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Video Retrieval by Adaptive Margin
Mar 09, 2023Video retrieval is becoming increasingly important owing to the rapid emergence of videos on the Internet. The dominant paradigm for video retrieval learns video-text representations by pushing the distance between the similarity of positive pairs and that of negative pairs apart from a fixed margin. However, negative pairs used for training are sampled randomly, which indicates that the semantics between negative pairs may be related or even equivalent, while most methods still enforce dissimilar representations to decrease their similarity. This phenomenon leads to inaccurate supervision and poor performance in learning video-text representations. While most video retrieval methods overlook that phenomenon, we propose an adaptive margin changed with the distance between positive and negative pairs to solve the aforementioned issue. First, we design the calculation framework of the adaptive margin, including the method of distance measurement and the function between the distance and the margin. Then, we explore a novel implementation called "Cross-Modal Generalized Self-Distillation" (CMGSD), which can be built on the top of most video retrieval models with few modifications. Notably, CMGSD adds few computational overheads at train time and adds no computational overhead at test time. Experimental results on three widely used datasets demonstrate that the proposed method can yield significantly better performance than the corresponding backbone model, and it outperforms state-of-the-art methods by a large margin.
WeCheck: Strong Factual Consistency Checker via Weakly Supervised Learning
Dec 20, 2022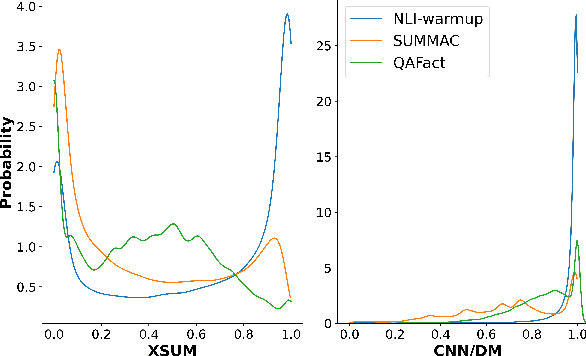
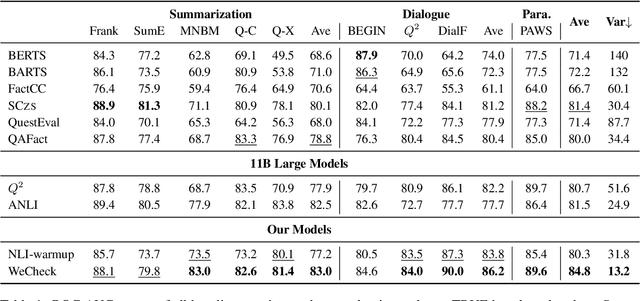
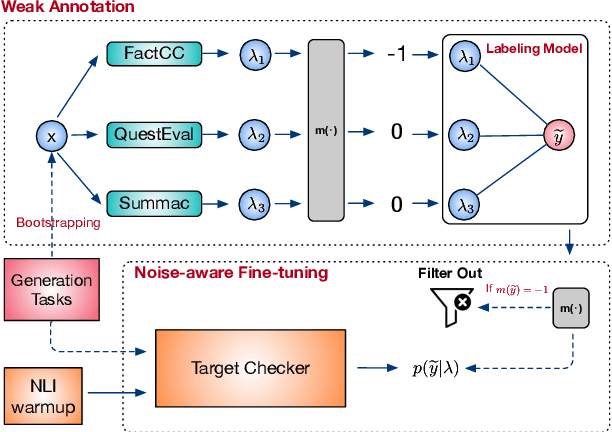
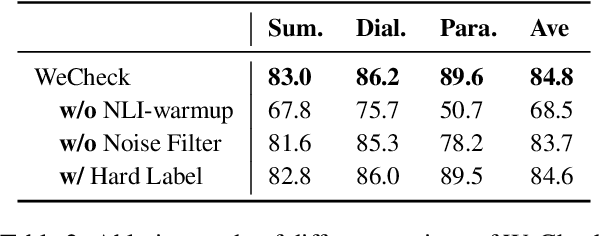
A crucial issue of current text generation models is that they often uncontrollably generate factually inconsistent text with respective of their inputs. Limited by the lack of annotated data, existing works in evaluating factual consistency directly transfer the reasoning ability of models trained on other data-rich upstream tasks like question answering (QA) and natural language inference (NLI) without any further adaptation. As a result, they perform poorly on the real generated text and are biased heavily by their single-source upstream tasks. To alleviate this problem, we propose a weakly supervised framework that aggregates multiple resources to train a precise and efficient factual metric, namely WeCheck. WeCheck first utilizes a generative model to accurately label a real generated sample by aggregating its weak labels, which are inferred from multiple resources. Then, we train the target metric model with the weak supervision while taking noises into consideration. Comprehensive experiments on a variety of tasks demonstrate the strong performance of WeCheck, which achieves a 3.4\% absolute improvement over previous state-of-the-art methods on TRUE benchmark on average.