 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequential-NIAH: A Needle-In-A-Haystack Benchmark for Extracting Sequential Needles from Long Contexts
Apr 09, 2025Evaluating the ability of large language models (LLMs) to handle extended contexts is critical, particularly for retrieving information relevant to specific queries embedded within lengthy inputs. We introduce Sequential-NIAH, a benchmark specifically designed to evaluate the capability of LLMs to extract sequential information items (known as needles) from long contexts. The benchmark comprises three types of needle generation pipelines: synthetic, real, and open-domain QA. It includes contexts ranging from 8K to 128K tokens in length, with a dataset of 14,000 samples (2,000 reserved for testing). To facilitate evaluation on this benchmark, we trained a synthetic data-driven evaluation model capable of evaluating answer correctness based on chronological or logical order, achieving an accuracy of 99.49% on synthetic test data. We conducted experiments on six well-known LLMs, revealing that even the best-performing model achieved a maximum accuracy of only 63.15%. Further analysis highlights the growing challenges posed by increasing context lengths and the number of needles, underscoring substantial room for improvement. Additionally, noise robustness experiments validate the reliability of the benchmark, making Sequential-NIAH an important reference for advancing research on long text extraction capabilities of LLMs.
FactGuard: Leveraging Multi-Agent Systems to Generate Answerable and Unanswerable Questions for Enhanced Long-Context LLM Extraction
Apr 08, 2025Extractive reading comprehension systems are designed to locate the correct answer to a question within a given text. However, a persistent challenge lies in ensuring these models maintain high accuracy in answering questions while reliably recognizing unanswerable queries. Despite significant advances in large language models (LLMs) for reading comprehension, this issue remains critical, particularly as the length of supported contexts continues to expand. To address this challenge, we propose an innovative data augmentation methodology grounded in a multi-agent collaborative framework. Unlike traditional methods, such as the costly human annotation process required for datasets like SQuAD 2.0, our method autonomously generates evidence-based question-answer pairs and systematically constructs unanswerable questions. Using this methodology, we developed the FactGuard-Bench dataset, which comprises 25,220 examples of both answerable and unanswerable question scenarios, with context lengths ranging from 8K to 128K. Experimental evaluations conducted on seven popular LLMs reveal that even the most advanced models achieve only 61.79% overall accuracy. Furthermore, we emphasize the importance of a model's ability to reason about unanswerable questions to avoid generating plausible but incorrect answers. By implementing efficient data selection and generation within the multi-agent collaborative framework, our method significantly reduces the traditionally high costs associated with manual annotation and provides valuable insights for the training and optimization of LLMs.
LLaVA-RadZ: Can Multimodal Large Language Models Effectively Tackle Zero-shot Radiology Recognition?
Mar 10, 2025Recently, multimodal large models (MLLMs) have demonstrated exceptional capabilities in visual understanding and reasoning across various vision-language tasks. However, MLLMs usually perform poorly in zero-shot medical disease recognition, as they do not fully exploit the captured features and available medical knowledge. To address this challenge, we propose LLaVA-RadZ, a simple yet effective framework for zero-shot medical disease recognition. Specifically, we design an end-to-end training strategy, termed Decoding-Side Feature Alignment Training (DFAT) to take advantage of the characteristics of the MLLM decoder architecture and incorporate modality-specific tokens tailored for different modalities, which effectively utilizes image and text representations and facilitates robust cross-modal alignment. Additionally, we introduce a Domain Knowledge Anchoring Module (DKAM) to exploit the intrinsic medical knowledge of large models, which mitigates the category semantic gap in image-text alignment. DKAM improves category-level alignment, allowing for accurate disease recognition. Extensive experiments on multiple benchmarks demonstrate that our LLaVA-RadZ significantly outperforms traditional MLLMs in zero-shot disease recognition and exhibits the state-of-the-art performance compared to the well-established and highly-optimized CLIP-based approaches.
Human Cognition Inspired RAG with Knowledge Graph for Complex Problem Solving
Mar 09, 2025Large language models (LLMs) have demonstrated transformative potential across various domains, yet they face significant challenges in knowledge integration and complex problem reasoning, often leading to hallucinations and unreliable outputs. Retrieval-Augmented Generation (RAG) has emerged as a promising solution to enhance LLMs accuracy by incorporating external knowledge. However, traditional RAG systems struggle with processing complex relational information and multi-step reasoning, limiting their effectiveness in advanced problem-solving tasks. To address these limitations, we propose CogGRAG, a cognition inspired graph-based RAG framework, designed to improve LLMs performance in Knowledge Graph Question Answering (KGQA). Inspired by the human cognitive process of decomposing complex problems and performing self-verification, our framework introduces a three-stage methodology: decomposition, retrieval, and reasoning with self-verification. By integrating these components, CogGRAG enhances the accuracy of LLMs in complex problem solving. We conduct systematic experiments with three LLM backbones on four benchmark datasets, where CogGRAG outperforms the baselines.
RocketEval: Efficient Automated LLM Evaluation via Grading Checklist
Mar 07, 2025



Evaluating large language models (LLMs) in diverse and challenging scenarios is essential to align them with human preferences. To mitigate the prohibitive costs associated with human evaluations, utilizing a powerful LLM as a judge has emerged as a favored approach. Nevertheless, this methodology encounters several challenges, including substantial expenses, concerns regarding privacy and security, and reproducibility. In this paper, we propose a straightforward, replicable, and accurate automated evaluation method by leveraging a lightweight LLM as the judge, named RocketEval. Initially, we identify that the performance disparity between lightweight and powerful LLMs in evaluation tasks primarily stems from their ability to conduct comprehensive analyses, which is not easily enhanced through techniques such as chain-of-thought reasoning. By reframing the evaluation task as a multi-faceted Q&A using an instance-specific checklist, we demonstrate that the limited judgment accuracy of lightweight LLMs is largely attributes to high uncertainty and positional bias. To address these challenges, we introduce an automated evaluation process grounded in checklist grading, which is designed to accommodate a variety of scenarios and questions. This process encompasses the creation of checklists, the grading of these checklists by lightweight LLMs, and the reweighting of checklist items to align with the supervised annotations. Our experiments carried out on the automated evaluation benchmarks, MT-Bench and WildBench datasets, reveal that RocketEval, when using Gemma-2-2B as the judge, achieves a high correlation (0.965) with human preferences, which is comparable to GPT-4o. Moreover, RocketEval provides a cost reduction exceeding 50-fold for large-scale evaluation and comparison scenarios. Our code is available at https://github.com/Joinn99/RocketEval-ICLR .
FlowAgent: Achieving Compliance and Flexibility for Workflow Agents
Feb 20, 2025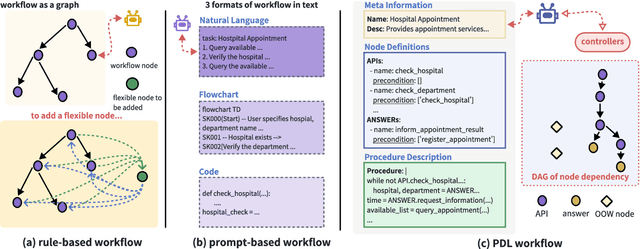

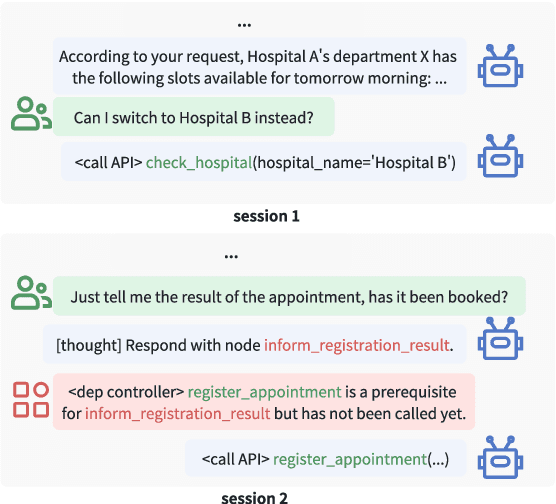
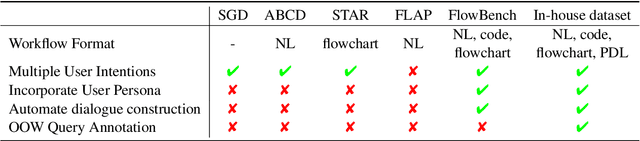
The integration of workflows with large language models (LLMs) enables LLM-based agents to execute predefined procedures, enhancing automation in real-world applications. Traditional rule-based methods tend to limit the inherent flexibility of LLMs, as their predefined execution paths restrict the models' action space, particularly when the unexpected, out-of-workflow (OOW) queries are encountered. Conversely, prompt-based methods allow LLMs to fully control the flow, which can lead to diminished enforcement of procedural compliance. To address these challenges, we introduce FlowAgent, a novel agent framework designed to maintain both compliance and flexibility. We propose the Procedure Description Language (PDL), which combines the adaptability of natural language with the precision of code to formulate workflows. Building on PDL, we develop a comprehensive framework that empowers LLMs to manage OOW queries effectively, while keeping the execution path under the supervision of a set of controllers. Additionally, we present a new evaluation methodology to rigorously assess an LLM agent's ability to handle OOW scenarios, going beyond routine flow compliance tested in existing benchmarks. Experiments on three datasets demonstrate that FlowAgent not only adheres to workflows but also effectively manages OOW queries, highlighting its dual strengths in compliance and flexibility. The code is available at https://github.com/Lightblues/FlowAgent.
RoleMRC: A Fine-Grained Composite Benchmark for Role-Playing and Instruction-Following
Feb 17, 2025Role-playing is important for Large Language Models (LLMs) to follow diverse instructions while maintaining role identity and the role's pre-defined ability limits. Existing role-playing datasets mostly contribute to controlling role style and knowledge boundaries, but overlook role-playing in instruction-following scenarios. We introduce a fine-grained role-playing and instruction-following composite benchmark, named RoleMRC, including: (1) Multi-turn dialogues between ideal roles and humans, including free chats or discussions upon given passages; (2) Role-playing machine reading comprehension, involving response, refusal, and attempts according to passage answerability and role ability; (3) More complex scenarios with nested, multi-turn and prioritized instructions. The final RoleMRC features a 10.2k role profile meta-pool, 37.9k well-synthesized role-playing instructions, and 1.4k testing samples. We develop a pipeline to quantitatively evaluate the fine-grained role-playing and instruction-following capabilities of several mainstream LLMs, as well as models that are fine-tuned on our data. Moreover, cross-evaluation on external role-playing datasets confirms that models fine-tuned on RoleMRC enhances instruction-following without compromising general role-playing and reasoning capabilities. We also probe the neural-level activation maps of different capabilities over post-tuned LLMs. Access to our RoleMRC, RoleMRC-mix and Codes: https://github.com/LuJunru/RoleMRC.
Long-VITA: Scaling Large Multi-modal Models to 1 Million Tokens with Leading Short-Context Accuray
Feb 07, 2025Establishing the long-context capability of large vision-language models is crucial for video understanding, high-resolution image understanding, multi-modal agents and reasoning. We introduce Long-VITA, a simple yet effective large multi-modal model for long-context visual-language understanding tasks. It is adept at concurrently processing and analyzing modalities of image, video, and text over 4K frames or 1M tokens while delivering advanced performances on short-context multi-modal tasks. We propose an effective multi-modal training schema that starts with large language models and proceeds through vision-language alignment, general knowledge learning, and two sequential stages of long-sequence fine-tuning. We further implement context-parallelism distributed inference and logits-masked language modeling head to scale Long-VITA to infinitely long inputs of images and texts during model inference. Regarding training data, Long-VITA is built on a mix of $17$M samples from public datasets only and demonstrates the state-of-the-art performance on various multi-modal benchmarks, compared against recent cutting-edge models with internal data. Long-VITA is fully reproducible and supports both NPU and GPU platforms for training and testing. We hope Long-VITA can serve as a competitive baseline and offer valuable insights for the open-source community in advancing long-context multi-modal understanding.
LUCY: Linguistic Understanding and Control Yielding Early Stage of Her
Jan 27, 2025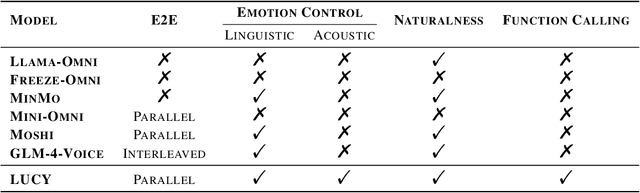
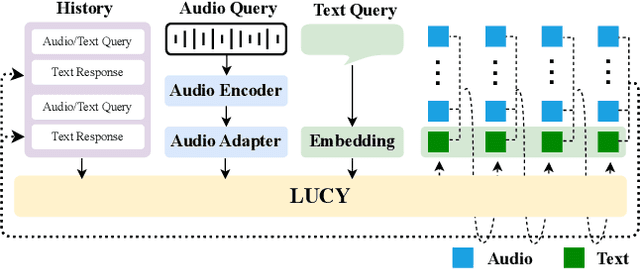
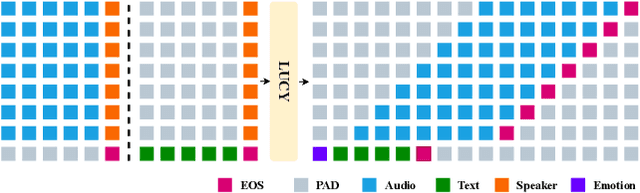
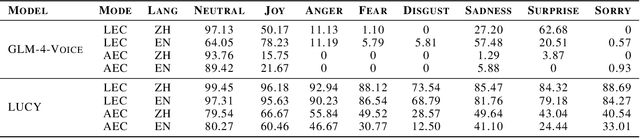
The film Her features Samantha, a sophisticated AI audio agent who is capable of understanding both linguistic and paralinguistic information in human speech and delivering real-time responses that are natural, informative and sensitive to emotional subtleties. Moving one step toward more sophisticated audio agent from recent advancement in end-to-end (E2E) speech systems, we propose LUCY, a E2E speech model that (1) senses and responds to user's emotion, (2) deliver responses in a succinct and natural style, and (3) use external tool to answer real-time inquiries. Experiment results show that LUCY is better at emotion control than peer models, generating emotional responses based on linguistic emotional instructions and responding to paralinguistic emotional cues. Lucy is also able to generate responses in a more natural style, as judged by external language models, without sacrificing much performance on general question answering. Finally, LUCY can leverage function calls to answer questions that are out of its knowledge scope.
VITA-1.5: Towards GPT-4o Level Real-Time Vision and Speech Interaction
Jan 03, 2025



Recent Multimodal Large Language Models (MLLMs) have typically focused on integrating visual and textual modalities, with less emphasis placed on the role of speech in enhancing interaction. However, speech plays a crucial role in multimodal dialogue systems, and implementing high-performance in both vision and speech tasks remains a significant challenge due to the fundamental modality differences. In this paper, we propose a carefully designed multi-stage training methodology that progressively trains LLM to understand both visual and speech information, ultimately enabling fluent vision and speech interaction. Our approach not only preserves strong vision-language capacity, but also enables efficient speech-to-speech dialogue capabilities without separate ASR and TTS modules, significantly accelerating multimodal end-to-end response speed. By comparing our method against state-of-the-art counterparts across benchmarks for image, video, and speech tasks, we demonstrate that our model is equipped with both strong visual and speech capabilities, making near real-time vision and speech interaction.