 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing Video Anomaly Detection: A Bi-Directional Hybrid Framework for Enhanced Single- and Multi-Task Approaches
Apr 20, 2025



Despite the prevailing transition from single-task to multi-task approaches in video anomaly detection, we observe that many adopt sub-optimal frameworks for individual proxy tasks. Motivated by this, we contend that optimizing single-task frameworks can advance both single- and multi-task approaches. Accordingly, we leverage middle-frame prediction as the primary proxy task, and introduce an effective hybrid framework designed to generate accurate predictions for normal frames and flawed predictions for abnormal frames. This hybrid framework is built upon a bi-directional structure that seamlessly integrates both vision transformers and ConvLSTMs. Specifically, we utilize this bi-directional structure to fully analyze the temporal dimension by predicting frames in both forward and backward directions, significantly boosting the detection stability. Given the transformer's capacity to model long-range contextual dependencies, we develop a convolutional temporal transformer that efficiently associates feature maps from all context frames to generate attention-based predictions for target frames. Furthermore, we devise a layer-interactive ConvLSTM bridge that facilitates the smooth flow of low-level features across layers and time-steps, thereby strengthening predictions with fine details. Anomalies are eventually identified by scrutinizing the discrepancies between target frames and their corresponding predictions. Several experiments conducted on public benchmarks affirm the efficacy of our hybrid framework, whether used as a standalone single-task approach or integrated as a branch in a multi-task approach. These experiments also underscore the advantages of merging vision transformers and ConvLSTMs for video anomaly detection.
* Accepted by IEEE Transactions on Image Processing (TIP)
RoleMRC: A Fine-Grained Composite Benchmark for Role-Playing and Instruction-Following
Feb 17, 2025Role-playing is important for Large Language Models (LLMs) to follow diverse instructions while maintaining role identity and the role's pre-defined ability limits. Existing role-playing datasets mostly contribute to controlling role style and knowledge boundaries, but overlook role-playing in instruction-following scenarios. We introduce a fine-grained role-playing and instruction-following composite benchmark, named RoleMRC, including: (1) Multi-turn dialogues between ideal roles and humans, including free chats or discussions upon given passages; (2) Role-playing machine reading comprehension, involving response, refusal, and attempts according to passage answerability and role ability; (3) More complex scenarios with nested, multi-turn and prioritized instructions. The final RoleMRC features a 10.2k role profile meta-pool, 37.9k well-synthesized role-playing instructions, and 1.4k testing samples. We develop a pipeline to quantitatively evaluate the fine-grained role-playing and instruction-following capabilities of several mainstream LLMs, as well as models that are fine-tuned on our data. Moreover, cross-evaluation on external role-playing datasets confirms that models fine-tuned on RoleMRC enhances instruction-following without compromising general role-playing and reasoning capabilities. We also probe the neural-level activation maps of different capabilities over post-tuned LLMs. Access to our RoleMRC, RoleMRC-mix and Codes: https://github.com/LuJunru/RoleMRC.
Stochastic Multivariate Universal-Radix Finite-State Machine: a Theoretically and Practically Elegant Nonlinear Function Approximator
May 03, 2024



Nonlinearities are crucial for capturing complex input-output relationships especially in deep neural networks. However, nonlinear functions often incur various hardware and compute overheads. Meanwhile, stochastic computing (SC) has emerged as a promising approach to tackle this challenge by trading output precision for hardware simplicity. To this end, this paper proposes a first-of-its-kind stochastic multivariate universal-radix finite-state machine (SMURF) that harnesses SC for hardware-simplistic multivariate nonlinear function generation at high accuracy. We present the finite-state machine (FSM) architecture for SMURF, as well as analytical derivations of sampling gate coefficients for accurately approximating generic nonlinear functions. Experiments demonstrate the superiority of SMURF, requiring only 16.07% area and 14.45% power consumption of Taylor-series approximation, and merely 2.22% area of look-up table (LUT) schemes.
ChemDFM: Dialogue Foundation Model for Chemistry
Jan 26, 2024



Large language models (LLMs) have established great success in the general domain of natural language processing. Their emerging task generalization and free-form dialogue capabilities can greatly help to design Chemical General Intelligence (CGI) to assist real-world research in chemistry. However, the existence of specialized language and knowledge in the field of chemistry, such as the highly informative SMILES notation, hinders the performance of general-domain LLMs in chemistry. To this end, we develop ChemDFM, the first LLM towards CGI. ChemDFM-13B is trained on 34B tokens from chemical literature, textbooks, and instructions as well as various data from the general domain. Therefore, it can store, understand, and reason over chemical knowledge and languages while still possessing advanced free-form language comprehension capabilities. Extensive quantitative evaluation shows that ChemDFM can significantly outperform the representative open-sourced LLMs. Moreover, ChemDFM can also surpass GPT-4 on a great portion of chemical tasks, despite the significant size difference. Further qualitative evaluations demonstrate the efficiency and effectiveness of ChemDFM in real-world research scenarios. We will open-source the ChemDFM model soon.
Look at Adjacent Frames: Video Anomaly Detection without Offline Training
Aug 04, 2022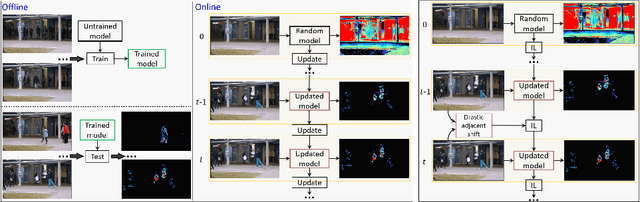
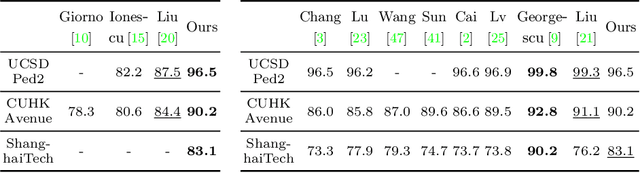

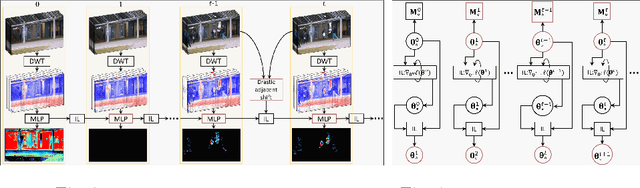
We propose a solution to detect anomalous events in videos without the need to train a model offline. Specifically, our solution is based on a randomly-initialized multilayer perceptron that is optimized online to reconstruct video frames, pixel-by-pixel, from their frequency information. Based on the information shifts between adjacent frames, an incremental learner is used to update parameters of the multilayer perceptron after observing each frame, thus allowing to detect anomalous events along the video stream. Traditional solutions that require no offline training are limited to operating on videos with only a few abnormal frames. Our solution breaks this limit and achieves strong performance on benchmark datasets.
Video Anomaly Detection via Prediction Network with Enhanced Spatio-Temporal Memory Exchange
Jun 26, 2022



Video anomaly detection is a challenging task because most anomalies are scarce and non-deterministic. Many approaches investigate the reconstruction difference between normal and abnormal patterns, but neglect that anomalies do not necessarily correspond to large reconstruction errors. To address this issue, we design a Convolutional LSTM Auto-Encoder prediction framework with enhanced spatio-temporal memory exchange using bi-directionalilty and a higher-order mechanism. The bi-directional structure promotes learning the temporal regularity through forward and backward predictions. The unique higher-order mechanism further strengthens spatial information interaction between the encoder and the decoder. Considering the limited receptive fields in Convolutional LSTMs, we also introduce an attention module to highlight informative features for prediction. Anomalies are eventually identified by comparing the frames with their corresponding predictions. Evaluations on three popular benchmarks show that our framework outperforms most existing prediction-based anomaly detection methods.