 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequential-NIAH: A Needle-In-A-Haystack Benchmark for Extracting Sequential Needles from Long Contexts
Apr 09, 2025Evaluating the ability of large language models (LLMs) to handle extended contexts is critical, particularly for retrieving information relevant to specific queries embedded within lengthy inputs. We introduce Sequential-NIAH, a benchmark specifically designed to evaluate the capability of LLMs to extract sequential information items (known as needles) from long contexts. The benchmark comprises three types of needle generation pipelines: synthetic, real, and open-domain QA. It includes contexts ranging from 8K to 128K tokens in length, with a dataset of 14,000 samples (2,000 reserved for testing). To facilitate evaluation on this benchmark, we trained a synthetic data-driven evaluation model capable of evaluating answer correctness based on chronological or logical order, achieving an accuracy of 99.49% on synthetic test data. We conducted experiments on six well-known LLMs, revealing that even the best-performing model achieved a maximum accuracy of only 63.15%. Further analysis highlights the growing challenges posed by increasing context lengths and the number of needles, underscoring substantial room for improvement. Additionally, noise robustness experiments validate the reliability of the benchmark, making Sequential-NIAH an important reference for advancing research on long text extraction capabilities of LLMs.
Epistemic Skills: Reasoning about Knowledge and Oblivion
Apr 02, 2025


This paper presents a class of epistemic logics that captures the dynamics of acquiring knowledge and descending into oblivion, while incorporating concepts of group knowledge. The approach is grounded in a system of weighted models, introducing an ``epistemic skills'' metric to represent the epistemic capacities tied to knowledge updates. Within this framework, knowledge acquisition is modeled as a process of upskilling, whereas oblivion is represented as a consequence of downskilling. The framework further enables exploration of ``knowability'' and ``forgettability,'' defined as the potential to gain knowledge through upskilling and to lapse into oblivion through downskilling, respectively. Additionally, it supports a detailed analysis of the distinctions between epistemic de re and de dicto expressions. The computational complexity of the model checking and satisfiability problems is examined, offering insights into their theoretical foundations and practical implications.
Adversarial Defense by Suppressing High-frequency Components
Sep 03, 2019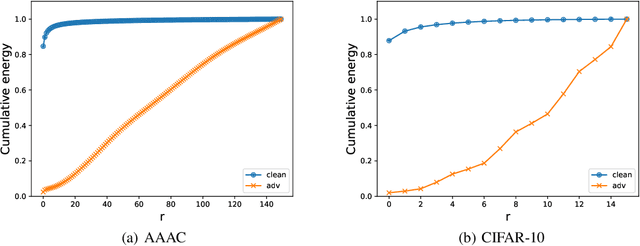

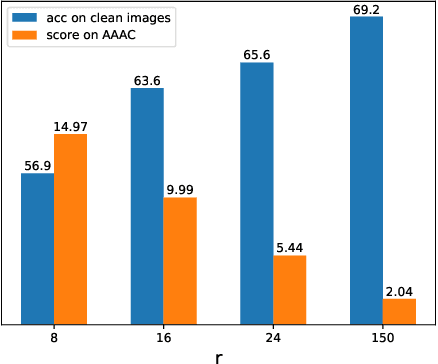
Recent works show that deep neural networks trained on image classification dataset bias towards textures. Those models are easily fooled by applying small high-frequency perturbations to clean images. In this paper, we learn robust image classification models by removing high-frequency components. Specifically, we develop a differentiable high-frequency suppression module based on discrete Fourier transform (DFT). Combining with adversarial training, we won the 5th place in the IJCAI-2019 Alibaba Adversarial AI Challenge. Our code is available online.