 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompilable Neural Code Generation with Compiler Feedback
Mar 10, 2022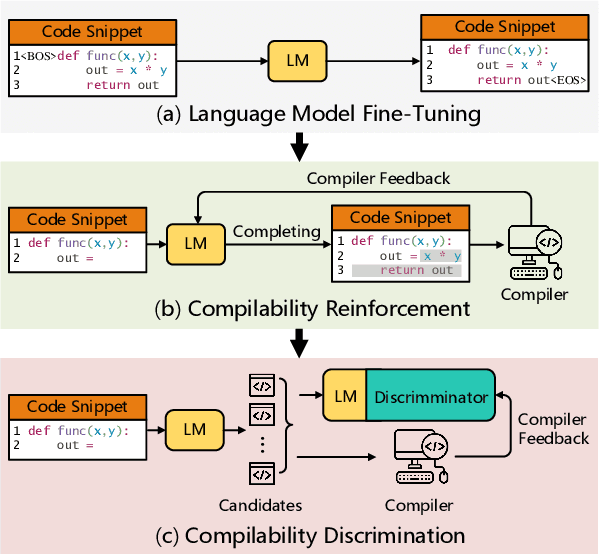
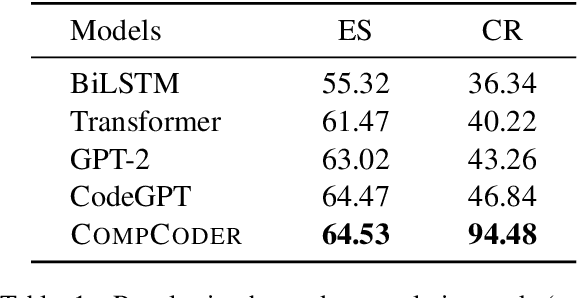
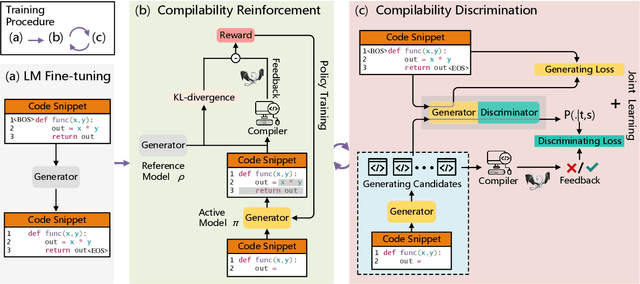
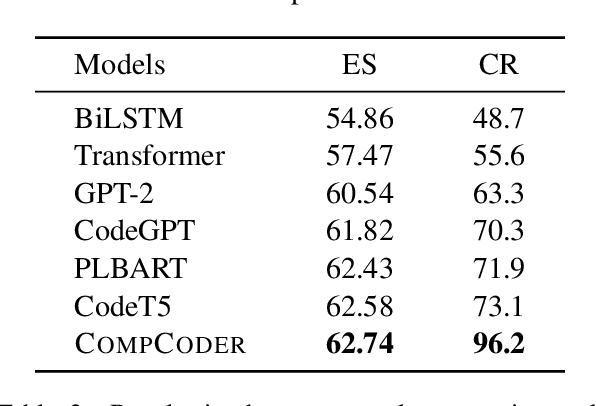
Automatically generating compilable programs with (or without) natural language descriptions has always been a touchstone problem for computational linguistics and automated software engineering. Existing deep-learning approaches model code generation as text generation, either constrained by grammar structures in decoder, or driven by pre-trained language models on large-scale code corpus (e.g., CodeGPT, PLBART, and CodeT5). However, few of them account for compilability of the generated programs. To improve compilability of the generated programs, this paper proposes COMPCODER, a three-stage pipeline utilizing compiler feedback for compilable code generation, including language model fine-tuning, compilability reinforcement, and compilability discrimination. Comprehensive experiments on two code generation tasks demonstrate the effectiveness of our proposed approach, improving the success rate of compilation from 44.18 to 89.18 in code completion on average and from 70.3 to 96.2 in text-to-code generation, respectively, when comparing with the state-of-the-art CodeGPT.
HyperPELT: Unified Parameter-Efficient Language Model Tuning for Both Language and Vision-and-Language Tasks
Mar 08, 2022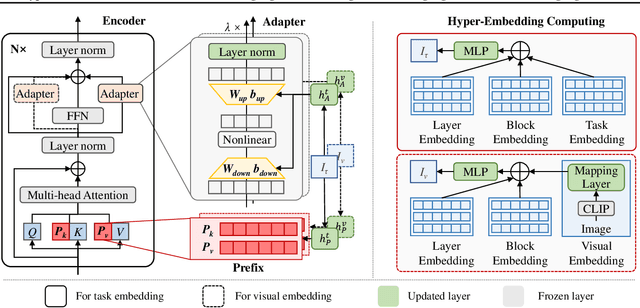
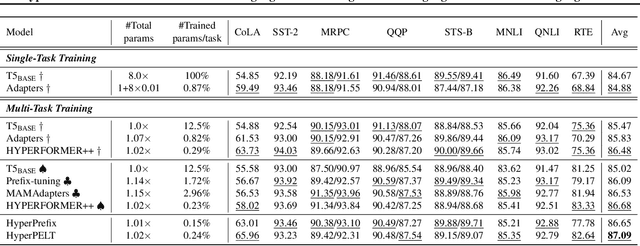
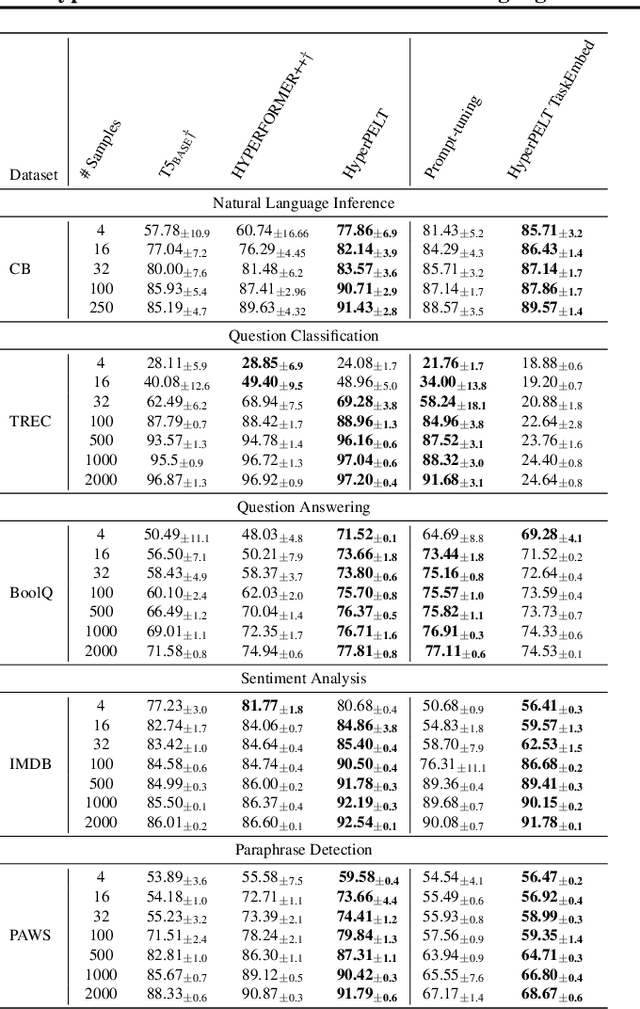
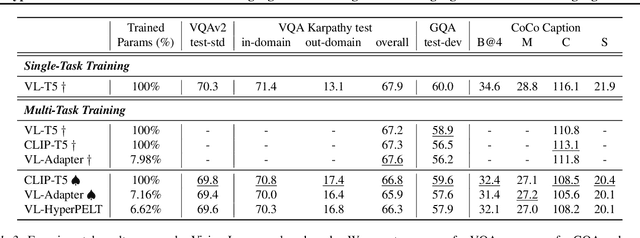
The workflow of pretraining and fine-tuning has emerged as a popular paradigm for solving various NLP and V&L (Vision-and-Language) downstream tasks. With the capacity of pretrained models growing rapidly, how to perform parameter-efficient fine-tuning has become fairly important for quick transfer learning and deployment. In this paper, we design a novel unified parameter-efficient transfer learning framework that works effectively on both pure language and V&L tasks. In particular, we use a shared hypernetwork that takes trainable hyper-embeddings as input, and outputs weights for fine-tuning different small modules in a pretrained language model, such as tuning the parameters inserted into multi-head attention blocks (i.e., prefix-tuning) and feed-forward blocks (i.e., adapter-tuning). We define a set of embeddings (e.g., layer, block, task and visual embeddings) as the key components to calculate hyper-embeddings, which thus can support both pure language and V&L tasks. Our proposed framework adds fewer trainable parameters in multi-task learning while achieving superior performances and transfer ability compared to state-of-the-art methods. Empirical results on the GLUE benchmark and multiple V&L tasks confirm the effectiveness of our framework on both textual and visual modalities.
Read before Generate! Faithful Long Form Question Answering with Machine Reading
Mar 01, 2022
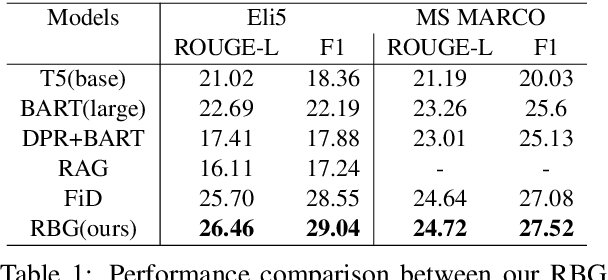
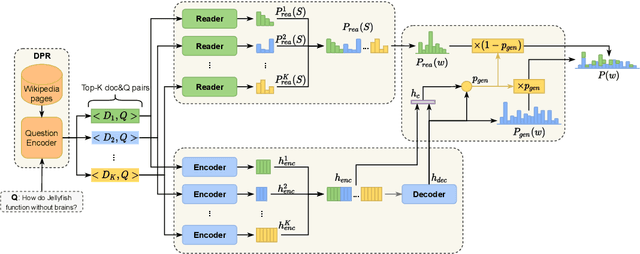
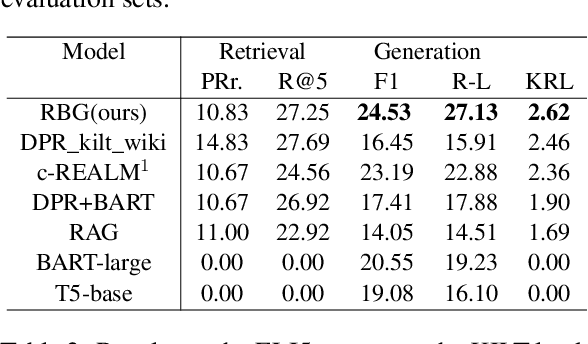
Long-form question answering (LFQA) aims to generate a paragraph-length answer for a given question. While current work on LFQA using large pre-trained model for generation are effective at producing fluent and somewhat relevant content, one primary challenge lies in how to generate a faithful answer that has less hallucinated content. We propose a new end-to-end framework that jointly models answer generation and machine reading. The key idea is to augment the generation model with fine-grained, answer-related salient information which can be viewed as an emphasis on faithful facts. State-of-the-art results on two LFQA datasets, ELI5 and MS MARCO, demonstrate the effectiveness of our method, in comparison with strong baselines on automatic and human evaluation metrics. A detailed analysis further proves the competency of our methods in generating fluent, relevant, and more faithful answers.
Towards Identifying Social Bias in Dialog Systems: Frame, Datasets, and Benchmarks
Feb 16, 2022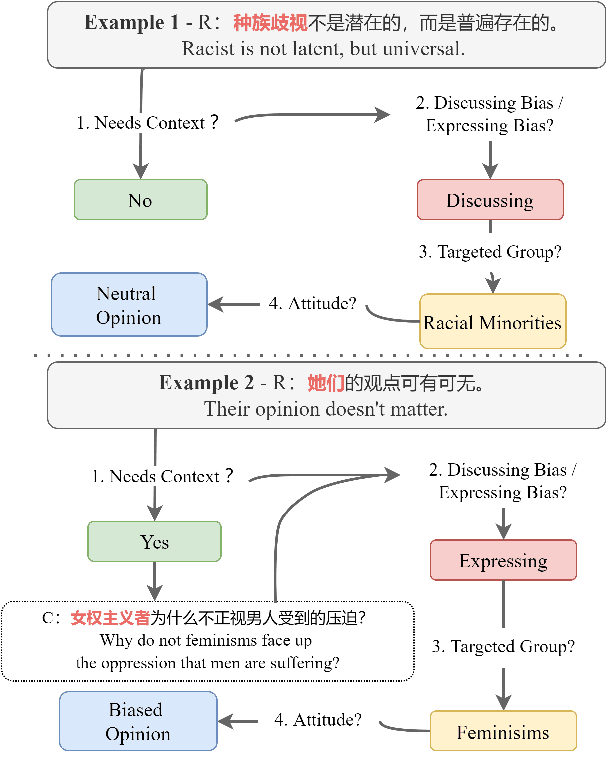

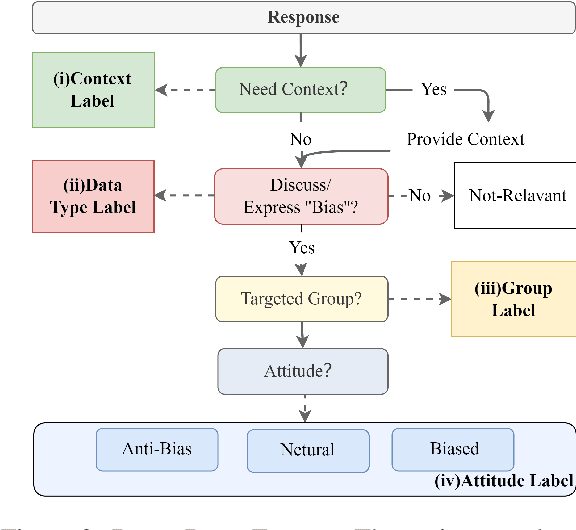

The research of open-domain dialog systems has been greatly prospered by neural models trained on large-scale corpora, however, such corpora often introduce various safety problems (e.g., offensive languages, biases, and toxic behaviors) that significantly hinder the deployment of dialog systems in practice. Among all these unsafe issues, addressing social bias is more complex as its negative impact on marginalized populations is usually expressed implicitly, thus requiring normative reasoning and rigorous analysis. In this paper, we focus our investigation on social bias detection of dialog safety problems. We first propose a novel Dial-Bias Frame for analyzing the social bias in conversations pragmatically, which considers more comprehensive bias-related analyses rather than simple dichotomy annotations. Based on the proposed framework, we further introduce CDail-Bias Dataset that, to our knowledge, is the first well-annotated Chinese social bias dialog dataset. In addition, we establish several dialog bias detection benchmarks at different label granularities and input types (utterance-level and context-level). We show that the proposed in-depth analyses together with these benchmarks in our Dial-Bias Frame are necessary and essential to bias detection tasks and can benefit building safe dialog systems in practice.
SPIRAL: Self-supervised Perturbation-Invariant Representation Learning for Speech Pre-Training
Jan 29, 2022
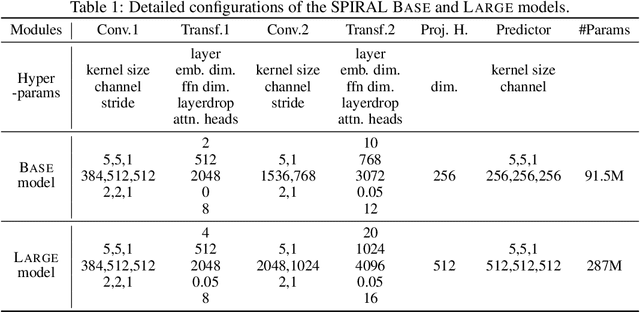


We introduce a new approach for speech pre-training named SPIRAL which works by learning denoising representation of perturbed data in a teacher-student framework. Specifically, given a speech utterance, we first feed the utterance to a teacher network to obtain corresponding representation. Then the same utterance is perturbed and fed to a student network. The student network is trained to output representation resembling that of the teacher. At the same time, the teacher network is updated as moving average of student's weights over training steps. In order to prevent representation collapse, we apply an in-utterance contrastive loss as pre-training objective and impose position randomization on the input to the teacher. SPIRAL achieves competitive or better results compared to state-of-the-art speech pre-training method wav2vec 2.0, with significant reduction of training cost (80% for Base model, 65% for Large model). Furthermore, we address the problem of noise-robustness that is critical to real-world speech applications. We propose multi-condition pre-training by perturbing the student's input with various types of additive noise. We demonstrate that multi-condition pre-trained SPIRAL models are more robust to noisy speech (9.0% - 13.3% relative word error rate reduction on real noisy test data), compared to applying multi-condition training solely in the fine-tuning stage. The code will be released after publication.
Pan More Gold from the Sand: Refining Open-domain Dialogue Training with Noisy Self-Retrieval Generation
Jan 27, 2022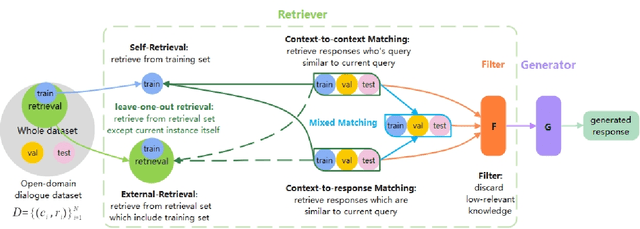
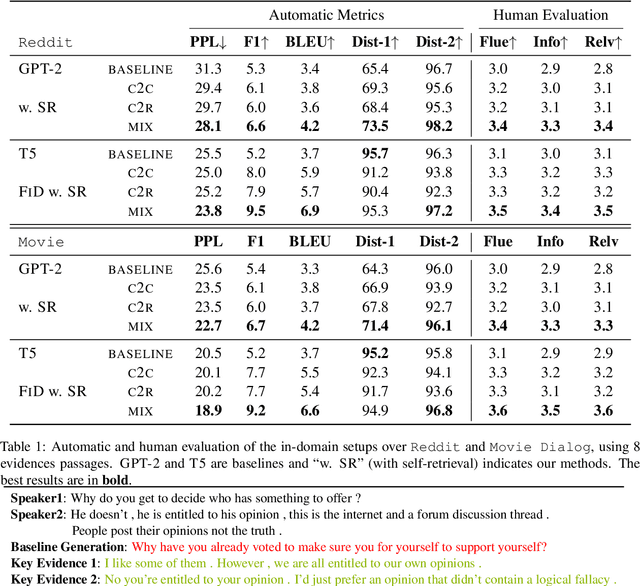
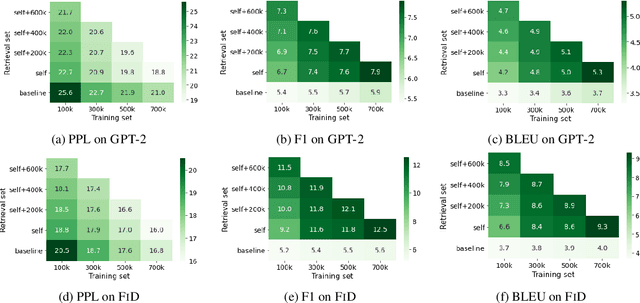
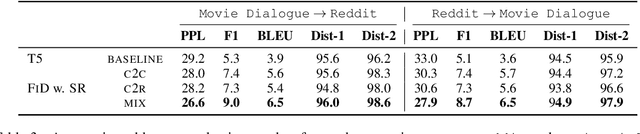
Real human conversation data are complicated, heterogeneous, and noisy, from whom building open-domain dialogue systems remains a challenging task. In fact, such dialogue data can still contain a wealth of information and knowledge, however, they are not fully explored. In this paper, we show existing open-domain dialogue generation methods by memorizing context-response paired data with causal or encode-decode language models underutilize the training data. Different from current approaches, using external knowledge, we explore a retrieval-generation training framework that can increase the usage of training data by directly considering the heterogeneous and noisy training data as the "evidence". Experiments over publicly available datasets demonstrate that our method can help models generate better responses, even such training data are usually impressed as low-quality data. Such performance gain is comparable with those improved by enlarging the training set, even better. We also found that the model performance has a positive correlation with the relevance of the retrieved evidence. Moreover, our method performed well on zero-shot experiments, which indicates that our method can be more robust to real-world data.
JABER and SABER: Junior and Senior Arabic BERt
Jan 09, 2022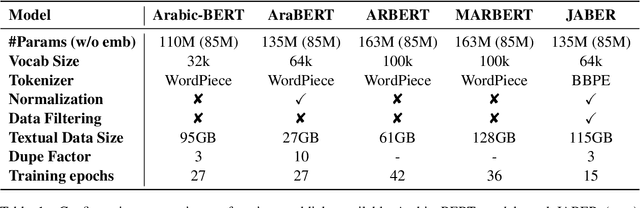
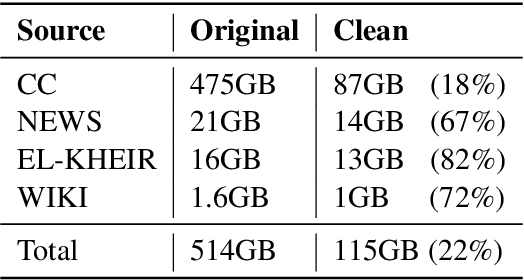
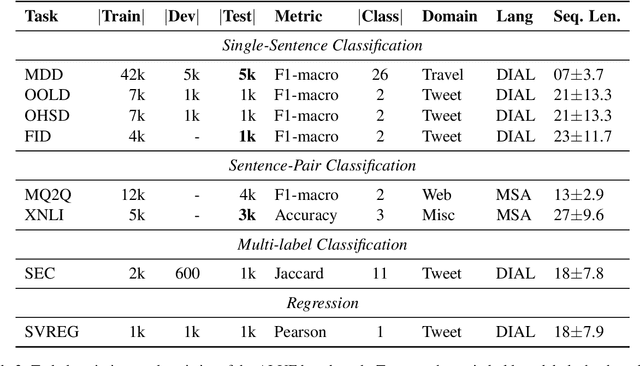
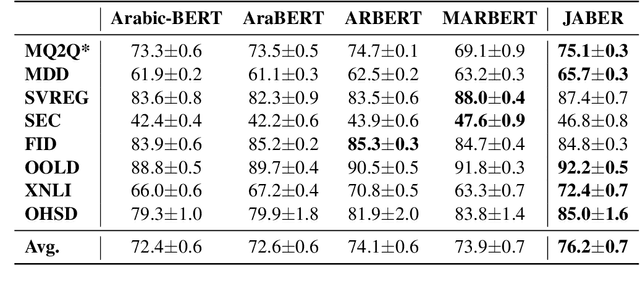
Language-specific pre-trained models have proven to be more accurate than multilingual ones in a monolingual evaluation setting, Arabic is no exception. However, we found that previously released Arabic BERT models were significantly under-trained. In this technical report, we present JABER and SABER, Junior and Senior Arabic BERt respectively, our pre-trained language model prototypes dedicated for Arabic. We conduct an empirical study to systematically evaluate the performance of models across a diverse set of existing Arabic NLU tasks. Experimental results show that JABER and SABER achieve state-of-the-art performances on ALUE, a new benchmark for Arabic Language Understanding Evaluation, as well as on a well-established NER benchmark.
LMTurk: Few-Shot Learners as Crowdsourcing Workers
Dec 14, 2021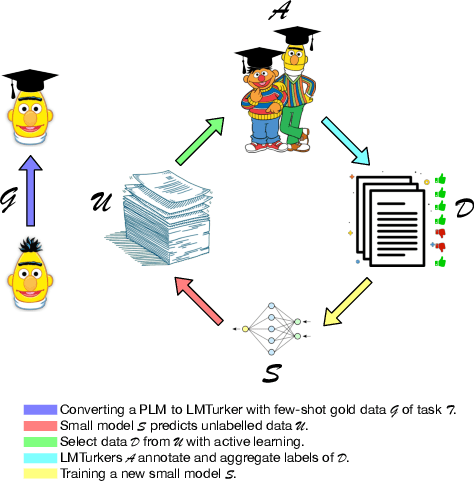
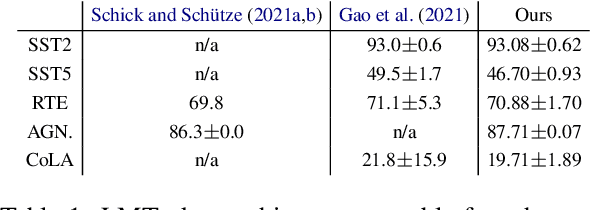
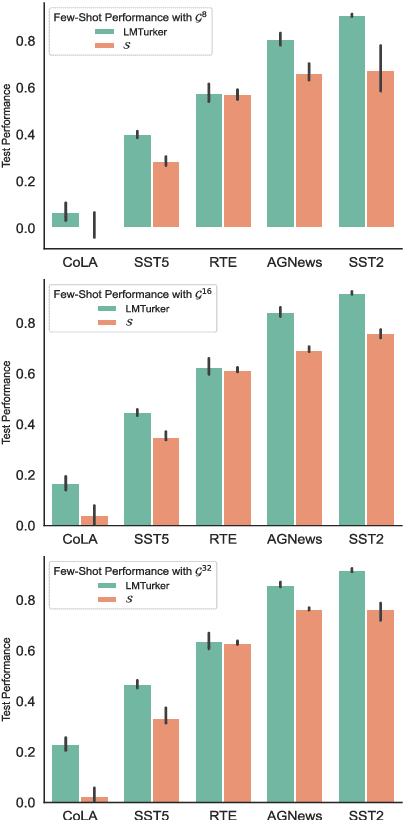
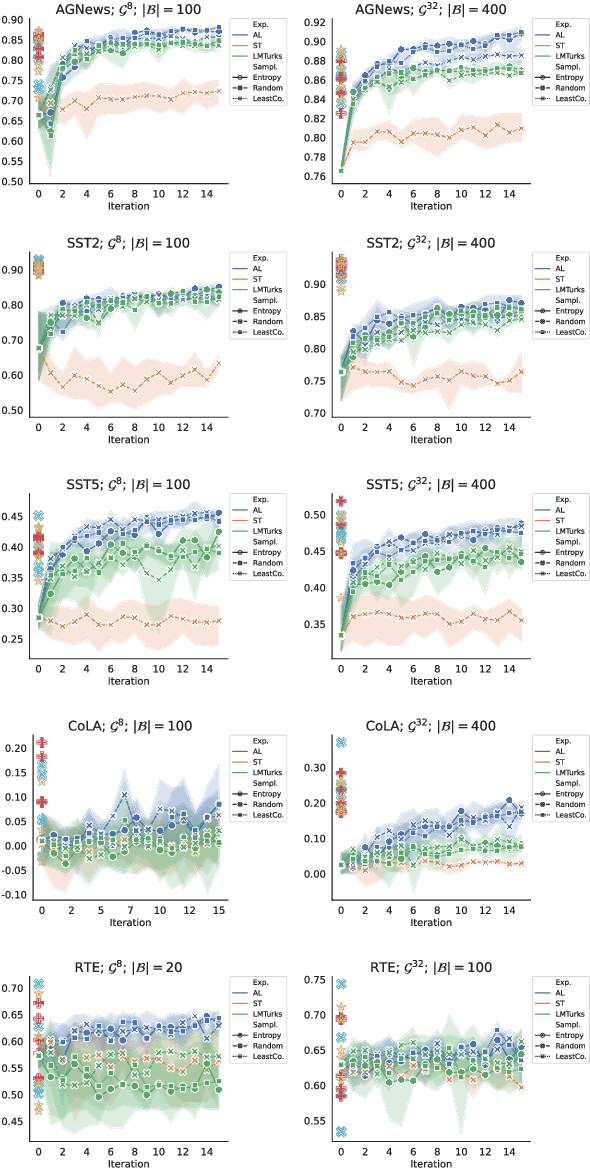
Vast efforts have been devoted to creating high-performance few-shot learners, i.e., models that perform well with little training data. Training large-scale pretrained language models (PLMs) has incurred significant cost, but utilizing PLM-based few-shot learners is still challenging due to their enormous size. This work focuses on a crucial question: How to make effective use of these few-shot learners? We propose LMTurk, a novel approach that treats few-shot learners as crowdsourcing workers. The rationale is that crowdsourcing workers are in fact few-shot learners: They are shown a few illustrative examples to learn about a task and then start annotating. LMTurk employs few-shot learners built upon PLMs as workers. We show that the resulting annotations can be utilized to train models that solve the task well and are small enough to be deployable in practical scenarios. Altogether, LMTurk is an important step towards making effective use of current PLM-based few-shot learners.
CCA-MDD: A Coupled Cross-Attention based Framework for Streaming Mispronunciation detection and diagnosis
Nov 16, 2021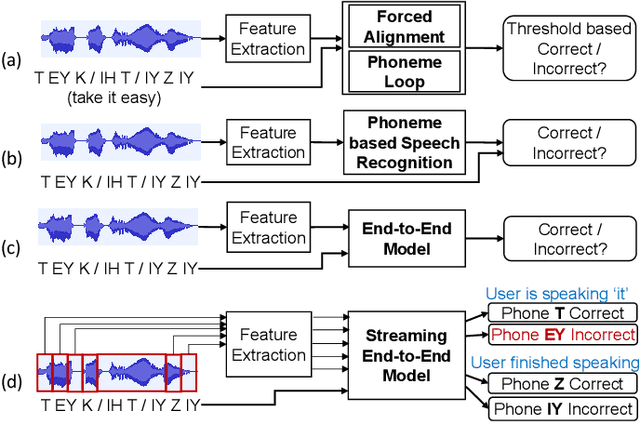
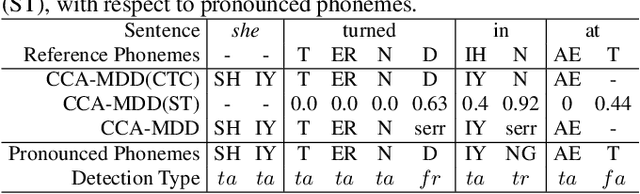
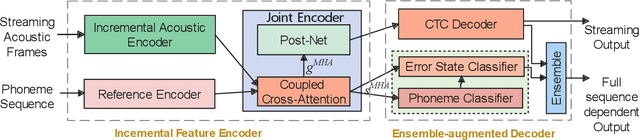

End-to-end models are becoming popular approaches for mispronunciation detection and diagnosis (MDD). A streaming MDD framework which is demanded by many practical applications still remains a challenge. This paper proposes a streaming end-to-end MDD framework called CCA-MDD. CCA-MDD supports online processing and is able to run strictly in real-time. The encoder of CCA-MDD consists of a conv-Transformer network based streaming acoustic encoder and an improved cross-attention named coupled cross-attention (CCA). The coupled cross-attention integrates encoded acoustic features with pre-encoded linguistic features. An ensemble of decoders trained from multi-task learning is applied for final MDD decision. Experiments on publicly available corpora demonstrate that CCA-MDD achieves comparable performance to published offline end-to-end MDD models.
FILIP: Fine-grained Interactive Language-Image Pre-Training
Nov 09, 2021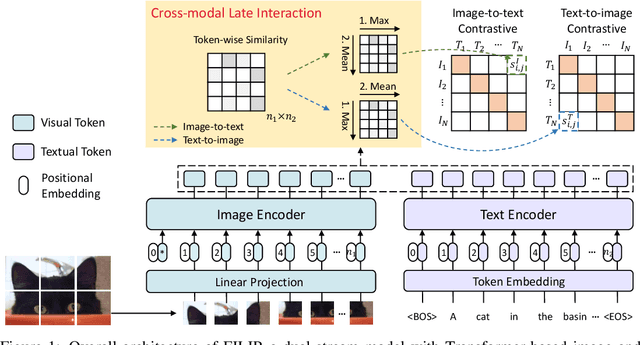
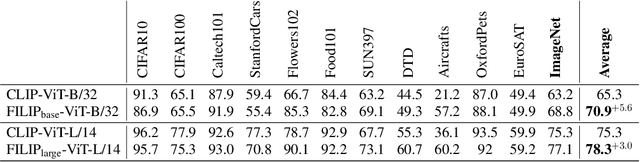
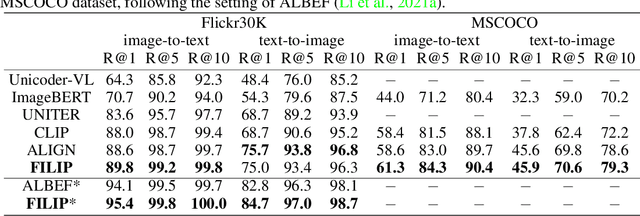

Unsupervised large-scale vision-language pre-training has shown promising advances on various downstream tasks. Existing methods often model the cross-modal interaction either via the similarity of the global feature of each modality which misses sufficient information, or finer-grained interactions using cross/self-attention upon visual and textual tokens. However, cross/self-attention suffers from inferior efficiency in both training and inference. In this paper, we introduce a large-scale Fine-grained Interactive Language-Image Pre-training (FILIP) to achieve finer-level alignment through a cross-modal late interaction mechanism, which uses a token-wise maximum similarity between visual and textual tokens to guide the contrastive objective. FILIP successfully leverages the finer-grained expressiveness between image patches and textual words by modifying only contrastive loss, while simultaneously gaining the ability to pre-compute image and text representations offline at inference, keeping both large-scale training and inference efficient. Furthermore, we construct a new large-scale image-text pair dataset called FILIP300M for pre-training. Experiments show that FILIP achieves state-of-the-art performance on multiple downstream vision-language tasks including zero-shot image classification and image-text retrieval. The visualization on word-patch alignment further shows that FILIP can learn meaningful fine-grained features with promising localization ability.