 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA QP Framework for Improving Data Collection: Quantifying Device-Controller Performance in Robot Teleoperation
Nov 11, 2025



Robot learning empowers the robot system with human brain-like intelligence to autonomously acquire and adapt skills through experience, enhancing flexibility and adaptability in various environments. Aimed at achieving a similar level of capability in large language models (LLMs) for embodied intelligence, data quality plays a crucial role in training a foundational model with diverse robot skills. In this study, we investigate the collection of data for manipulation tasks using teleoperation devices. Different devices yield varying effects when paired with corresponding controller strategies, including position-based inverse kinematics (IK) control, torque-based inverse dynamics (ID) control, and optimization-based compliance control. In this paper, we develop a teleoperation pipeline that is compatible with different teleoperation devices and manipulator controllers. Within the pipeline, we construct the optimal QP formulation with the dynamic nullspace and the impedance tracking as the novel optimal controller to achieve compliant pose tracking and singularity avoidance. Regarding the optimal controller, it adaptively adjusts the weights assignment depending on the robot joint manipulability that reflects the state of joint configuration for the pose tracking in the form of impedance control and singularity avoidance with nullspace tracking. Analysis of quantitative experimental results suggests the quality of the teleoperated trajectory data, including tracking error, occurrence of singularity, and the smoothness of the joints' trajectory, with different combinations of teleoperation interface and the motion controller.
Model Debiasing via Gradient-based Explanation on Representation
May 20, 2023



Machine learning systems produce biased results towards certain demographic groups, known as the fairness problem. Recent approaches to tackle this problem learn a latent code (i.e., representation) through disentangled representation learning and then discard the latent code dimensions correlated with sensitive attributes (e.g., gender). Nevertheless, these approaches may suffer from incomplete disentanglement and overlook proxy attributes (proxies for sensitive attributes) when processing real-world data, especially for unstructured data, causing performance degradation in fairness and loss of useful information for downstream tasks. In this paper, we propose a novel fairness framework that performs debiasing with regard to both sensitive attributes and proxy attributes, which boosts the prediction performance of downstream task models without complete disentanglement. The main idea is to, first, leverage gradient-based explanation to find two model focuses, 1) one focus for predicting sensitive attributes and 2) the other focus for predicting downstream task labels, and second, use them to perturb the latent code that guides the training of downstream task models towards fairness and utility goals. We show empirically that our framework works with both disentangled and non-disentangled representation learning methods and achieves better fairness-accuracy trade-off on unstructured and structured datasets than previous state-of-the-art approaches.
Human Attention-Guided Explainable Artificial Intelligence for Computer Vision Models
May 05, 2023We examined whether embedding human attention knowledge into saliency-based explainable AI (XAI) methods for computer vision models could enhance their plausibility and faithfulness. We first developed new gradient-based XAI methods for object detection models to generate object-specific explanations by extending the current methods for image classification models. Interestingly, while these gradient-based methods worked well for explaining image classification models, when being used for explaining object detection models, the resulting saliency maps generally had lower faithfulness than human attention maps when performing the same task. We then developed Human Attention-Guided XAI (HAG-XAI) to learn from human attention how to best combine explanatory information from the models to enhance explanation plausibility by using trainable activation functions and smoothing kernels to maximize XAI saliency map's similarity to human attention maps. While for image classification models, HAG-XAI enhanced explanation plausibility at the expense of faithfulness, for object detection models it enhanced plausibility and faithfulness simultaneously and outperformed existing methods. The learned functions were model-specific, well generalizable to other databases.
Sensor Data Validation and Driving Safety in Autonomous Driving Systems
Apr 01, 2022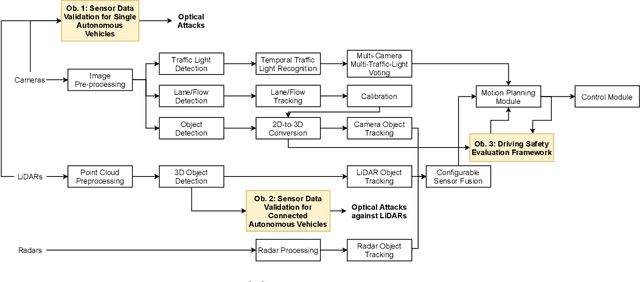
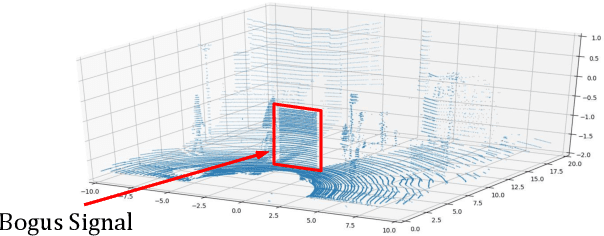

Autonomous driving technology has drawn a lot of attention due to its fast development and extremely high commercial values. The recent technological leap of autonomous driving can be primarily attributed to the progress in the environment perception. Good environment perception provides accurate high-level environment information which is essential for autonomous vehicles to make safe and precise driving decisions and strategies. Moreover, such progress in accurate environment perception would not be possible without deep learning models and advanced onboard sensors, such as optical sensors (LiDARs and cameras), radars, GPS. However, the advanced sensors and deep learning models are prone to recently invented attack methods. For example, LiDARs and cameras can be compromised by optical attacks, and deep learning models can be attacked by adversarial examples. The attacks on advanced sensors and deep learning models can largely impact the accuracy of the environment perception, posing great threats to the safety and security of autonomous vehicles. In this thesis, we study the detection methods against the attacks on onboard sensors and the linkage between attacked deep learning models and driving safety for autonomous vehicles. To detect the attacks, redundant data sources can be exploited, since information distortions caused by attacks in victim sensor data result in inconsistency with the information from other redundant sources. To study the linkage between attacked deep learning models and driving safety...
Read before Generate! Faithful Long Form Question Answering with Machine Reading
Mar 01, 2022
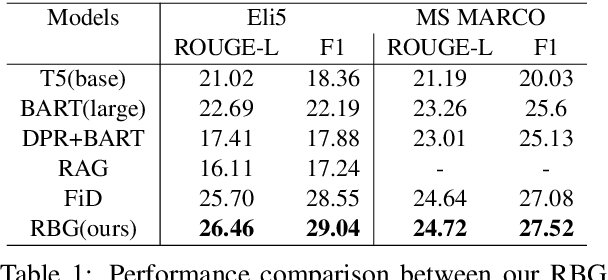
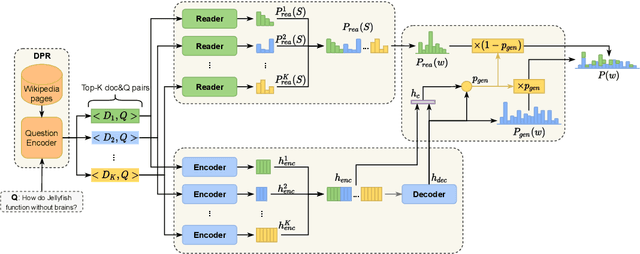
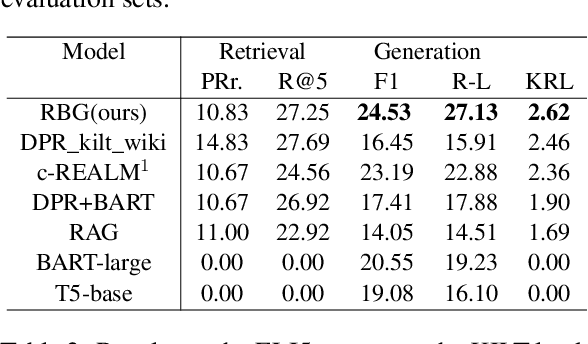
Long-form question answering (LFQA) aims to generate a paragraph-length answer for a given question. While current work on LFQA using large pre-trained model for generation are effective at producing fluent and somewhat relevant content, one primary challenge lies in how to generate a faithful answer that has less hallucinated content. We propose a new end-to-end framework that jointly models answer generation and machine reading. The key idea is to augment the generation model with fine-grained, answer-related salient information which can be viewed as an emphasis on faithful facts. State-of-the-art results on two LFQA datasets, ELI5 and MS MARCO, demonstrate the effectiveness of our method, in comparison with strong baselines on automatic and human evaluation metrics. A detailed analysis further proves the competency of our methods in generating fluent, relevant, and more faithful answers.
Detecting and Identifying Optical Signal Attacks on Autonomous Driving Systems
Oct 20, 2021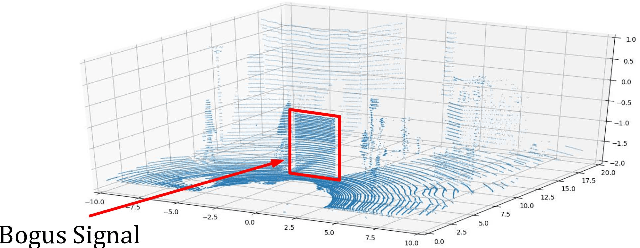

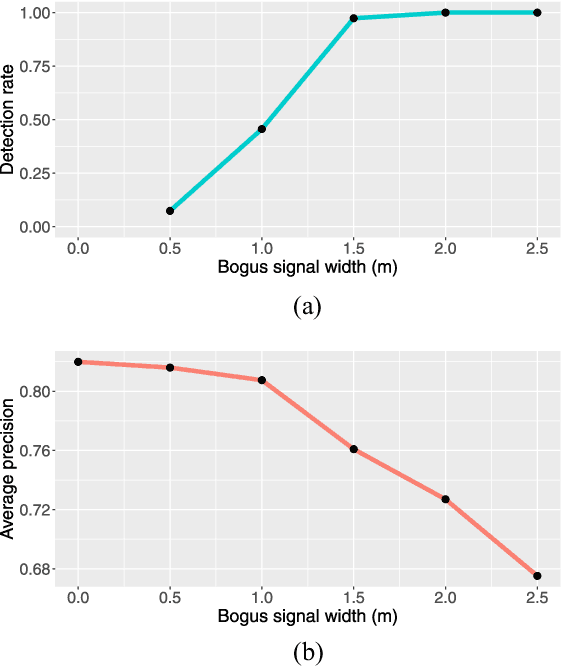
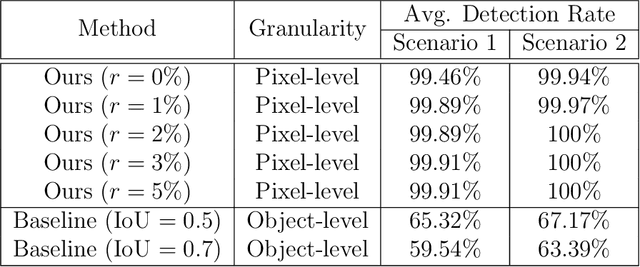
For autonomous driving, an essential task is to detect surrounding objects accurately. To this end, most existing systems use optical devices, including cameras and light detection and ranging (LiDAR) sensors, to collect environment data in real time. In recent years, many researchers have developed advanced machine learning models to detect surrounding objects. Nevertheless, the aforementioned optical devices are vulnerable to optical signal attacks, which could compromise the accuracy of object detection. To address this critical issue, we propose a framework to detect and identify sensors that are under attack. Specifically, we first develop a new technique to detect attacks on a system that consists of three sensors. Our main idea is to: 1) use data from three sensors to obtain two versions of depth maps (i.e., disparity) and 2) detect attacks by analyzing the distribution of disparity errors. In our study, we use real data sets and the state-of-the-art machine learning model to evaluate our attack detection scheme and the results confirm the effectiveness of our detection method. Based on the detection scheme, we further develop an identification model that is capable of identifying up to n-2 attacked sensors in a system with one LiDAR and n cameras. We prove the correctness of our identification scheme and conduct experiments to show the accuracy of our identification method. Finally, we investigate the overall sensitivity of our framework.
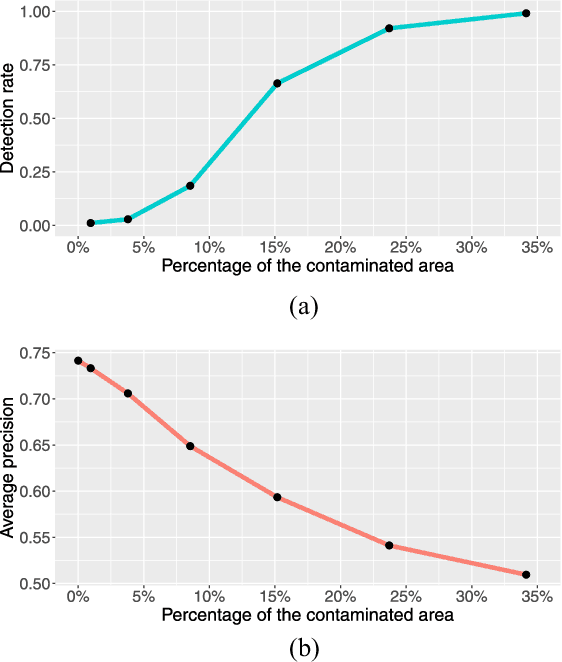
Evaluating Adversarial Attacks on Driving Safety in Vision-Based Autonomous Vehicles
Aug 06, 2021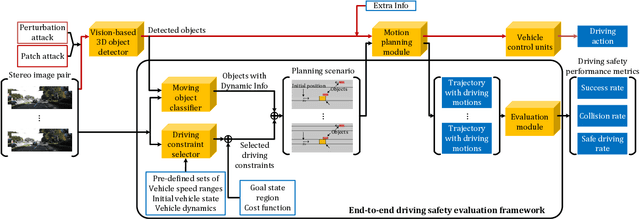

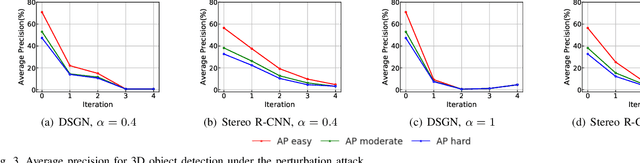
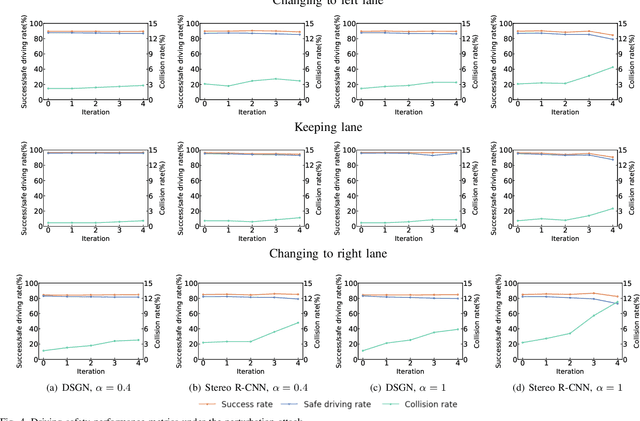
In recent years, many deep learning models have been adopted in autonomous driving. At the same time, these models introduce new vulnerabilities that may compromise the safety of autonomous vehicles. Specifically, recent studies have demonstrated that adversarial attacks can cause a significant decline in detection precision of deep learning-based 3D object detection models. Although driving safety is the ultimate concern for autonomous driving, there is no comprehensive study on the linkage between the performance of deep learning models and the driving safety of autonomous vehicles under adversarial attacks. In this paper, we investigate the impact of two primary types of adversarial attacks, perturbation attacks and patch attacks, on the driving safety of vision-based autonomous vehicles rather than the detection precision of deep learning models. In particular, we consider two state-of-the-art models in vision-based 3D object detection, Stereo R-CNN and DSGN. To evaluate driving safety, we propose an end-to-end evaluation framework with a set of driving safety performance metrics. By analyzing the results of our extensive evaluation experiments, we find that (1) the attack's impact on the driving safety of autonomous vehicles and the attack's impact on the precision of 3D object detectors are decoupled, and (2) the DSGN model demonstrates stronger robustness to adversarial attacks than the Stereo R-CNN model. In addition, we further investigate the causes behind the two findings with an ablation study. The findings of this paper provide a new perspective to evaluate adversarial attacks and guide the selection of deep learning models in autonomous driving.