 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Pre-trained Language Models and their Evaluation for Arabic Natural Language Understanding
May 21, 2022
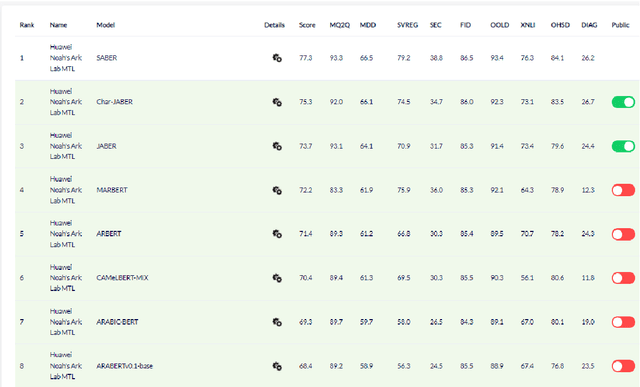
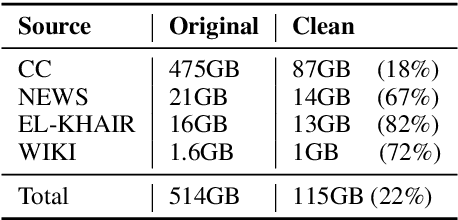
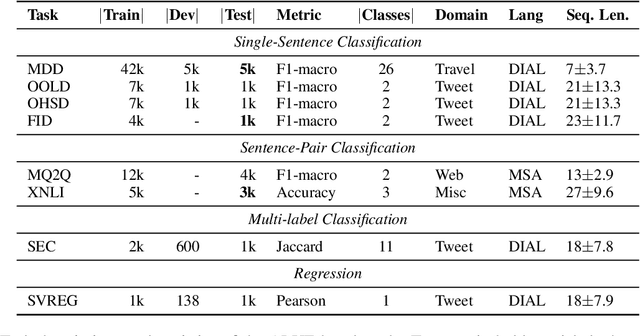
There is a growing body of work in recent years to develop pre-trained language models (PLMs) for the Arabic language. This work concerns addressing two major problems in existing Arabic PLMs which constraint progress of the Arabic NLU and NLG fields.First, existing Arabic PLMs are not well-explored and their pre-trainig can be improved significantly using a more methodical approach. Second, there is a lack of systematic and reproducible evaluation of these models in the literature. In this work, we revisit both the pre-training and evaluation of Arabic PLMs. In terms of pre-training, we explore improving Arabic LMs from three perspectives: quality of the pre-training data, size of the model, and incorporating character-level information. As a result, we release three new Arabic BERT-style models ( JABER, Char-JABER, and SABER), and two T5-style models (AT5S and AT5B). In terms of evaluation, we conduct a comprehensive empirical study to systematically evaluate the performance of existing state-of-the-art models on ALUE that is a leaderboard-powered benchmark for Arabic NLU tasks, and on a subset of the ARGEN benchmark for Arabic NLG tasks. We show that our models significantly outperform existing Arabic PLMs and achieve a new state-of-the-art performance on discriminative and generative Arabic NLU and NLG tasks. Our models and source code to reproduce of results will be made available shortly.
Exploring Extreme Parameter Compression for Pre-trained Language Models
May 20, 2022
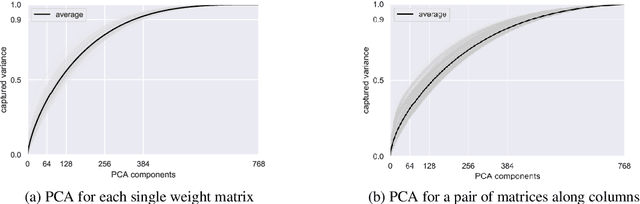
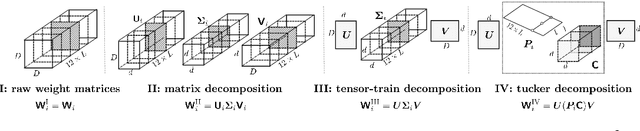

Recent work explored the potential of large-scale Transformer-based pre-trained models, especially Pre-trained Language Models (PLMs) in natural language processing. This raises many concerns from various perspectives, e.g., financial costs and carbon emissions. Compressing PLMs like BERT with negligible performance loss for faster inference and cheaper deployment has attracted much attention. In this work, we aim to explore larger compression ratios for PLMs, among which tensor decomposition is a potential but under-investigated one. Two decomposition and reconstruction protocols are further proposed to improve the effectiveness and efficiency during compression. Our compressed BERT with ${1}/{7}$ parameters in Transformer layers performs on-par with, sometimes slightly better than the original BERT in GLUE benchmark. A tiny version achieves $96.7\%$ performance of BERT-base with $ {1}/{48} $ encoder parameters (i.e., less than 2M parameters excluding the embedding layer) and $2.7 \times$ faster on inference. To show that the proposed method is orthogonal to existing compression methods like knowledge distillation, we also explore the benefit of the proposed method on a distilled BERT.
UTC: A Unified Transformer with Inter-Task Contrastive Learning for Visual Dialog
May 03, 2022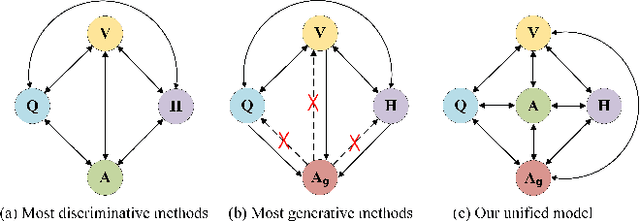
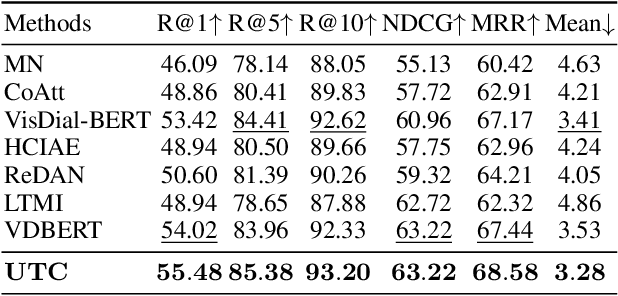
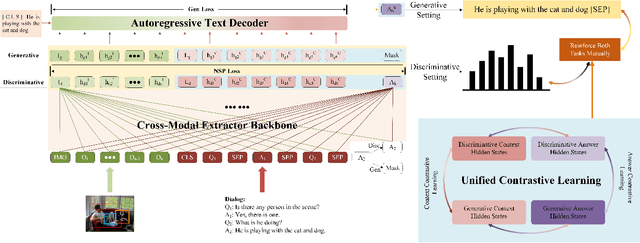
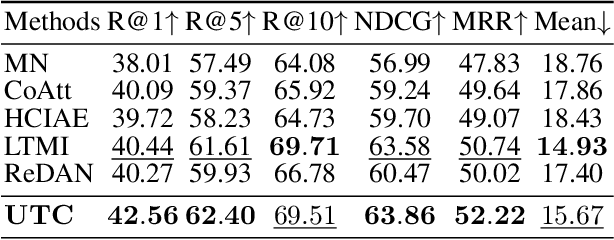
Visual Dialog aims to answer multi-round, interactive questions based on the dialog history and image content. Existing methods either consider answer ranking and generating individually or only weakly capture the relation across the two tasks implicitly by two separate models. The research on a universal framework that jointly learns to rank and generate answers in a single model is seldom explored. In this paper, we propose a contrastive learning-based framework UTC to unify and facilitate both discriminative and generative tasks in visual dialog with a single model. Specifically, considering the inherent limitation of the previous learning paradigm, we devise two inter-task contrastive losses i.e., context contrastive loss and answer contrastive loss to make the discriminative and generative tasks mutually reinforce each other. These two complementary contrastive losses exploit dialog context and target answer as anchor points to provide representation learning signals from different perspectives. We evaluate our proposed UTC on the VisDial v1.0 dataset, where our method outperforms the state-of-the-art on both discriminative and generative tasks and surpasses previous state-of-the-art generative methods by more than 2 absolute points on Recall@1.
Hyperlink-induced Pre-training for Passage Retrieval in Open-domain Question Answering
Apr 12, 2022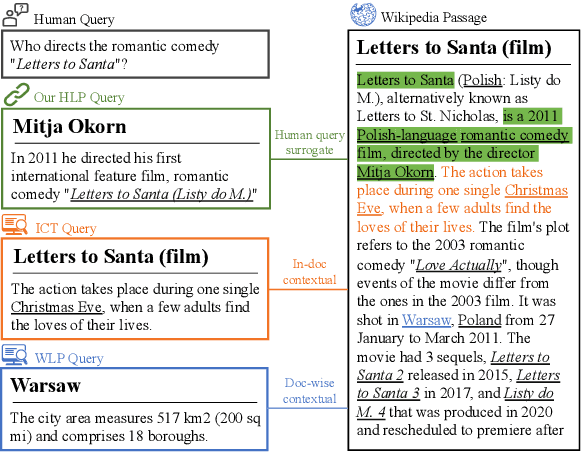
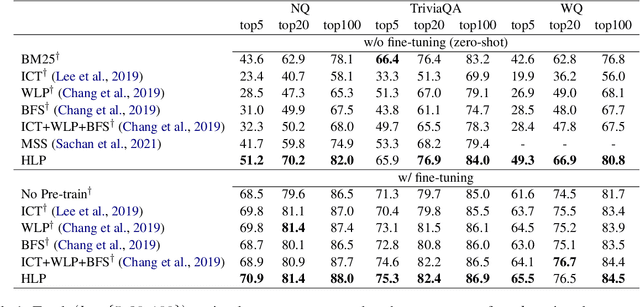
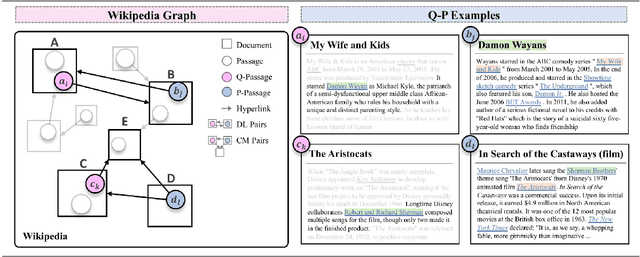
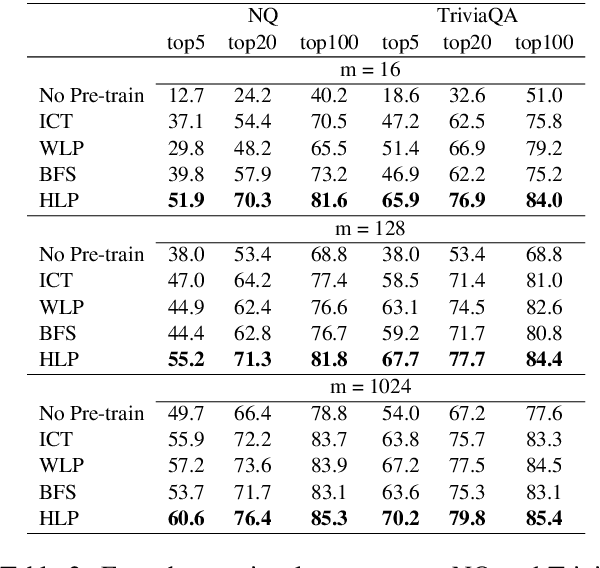
To alleviate the data scarcity problem in training question answering systems, recent works propose additional intermediate pre-training for dense passage retrieval (DPR). However, there still remains a large discrepancy between the provided upstream signals and the downstream question-passage relevance, which leads to less improvement. To bridge this gap, we propose the HyperLink-induced Pre-training (HLP), a method to pre-train the dense retriever with the text relevance induced by hyperlink-based topology within Web documents. We demonstrate that the hyperlink-based structures of dual-link and co-mention can provide effective relevance signals for large-scale pre-training that better facilitate downstream passage retrieval. We investigate the effectiveness of our approach across a wide range of open-domain QA datasets under zero-shot, few-shot, multi-hop, and out-of-domain scenarios. The experiments show our HLP outperforms the BM25 by up to 7 points as well as other pre-training methods by more than 10 points in terms of top-20 retrieval accuracy under the zero-shot scenario. Furthermore, HLP significantly outperforms other pre-training methods under the other scenarios.
CorrectSpeech: A Fully Automated System for Speech Correction and Accent Reduction
Apr 12, 2022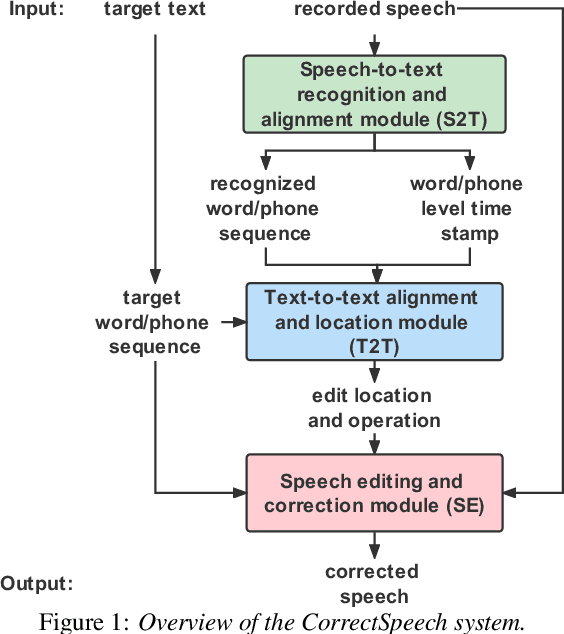
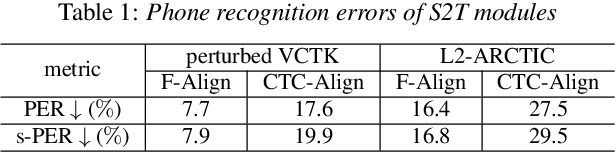
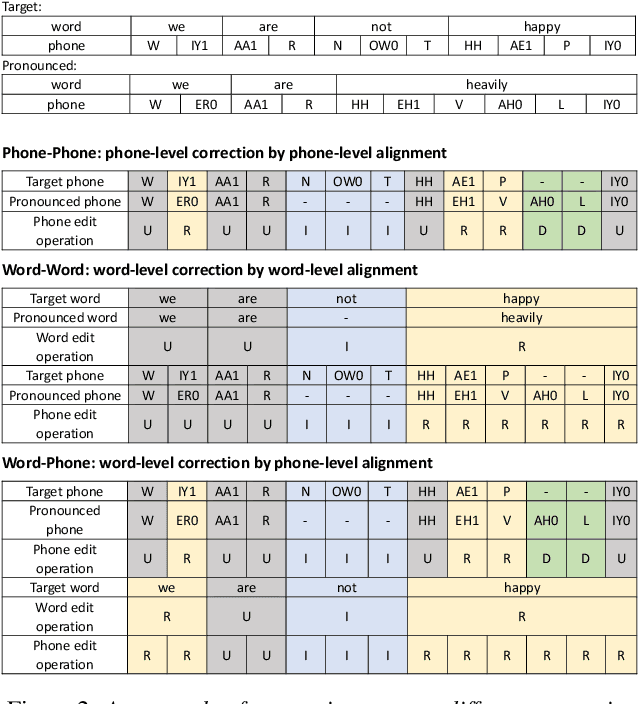
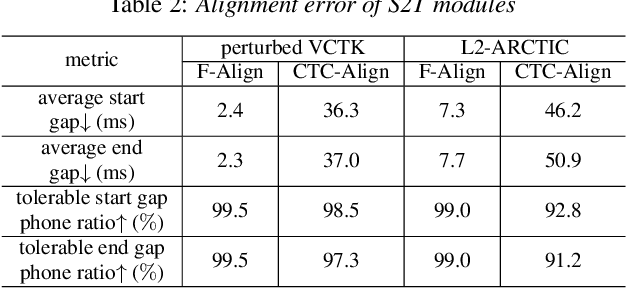
This study extends our previous work on text-based speech editing to developing a fully automated system for speech correction and accent reduction. Consider the application scenario that a recorded speech audio contains certain errors, e.g., inappropriate words, mispronunciations, that need to be corrected. The proposed system, named CorrectSpeech, performs the correction in three steps: recognizing the recorded speech and converting it into time-stamped symbol sequence, aligning recognized symbol sequence with target text to determine locations and types of required edit operations, and generating the corrected speech. Experiments show that the quality and naturalness of corrected speech depend on the performance of speech recognition and alignment modules, as well as the granularity level of editing operations. The proposed system is evaluated on two corpora: a manually perturbed version of VCTK and L2-ARCTIC. The results demonstrate that our system is able to correct mispronunciation and reduce accent in speech recordings. Audio samples are available online for demonstration https://daxintan-cuhk.github.io/CorrectSpeech/ .
PanGu-Bot: Efficient Generative Dialogue Pre-training from Pre-trained Language Model
Apr 07, 2022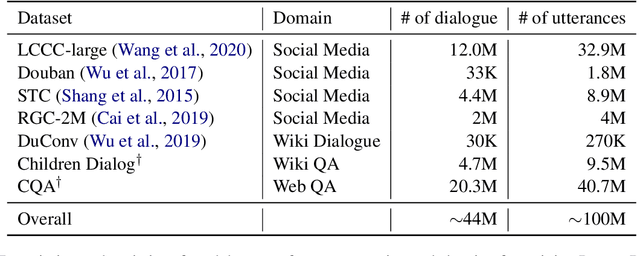
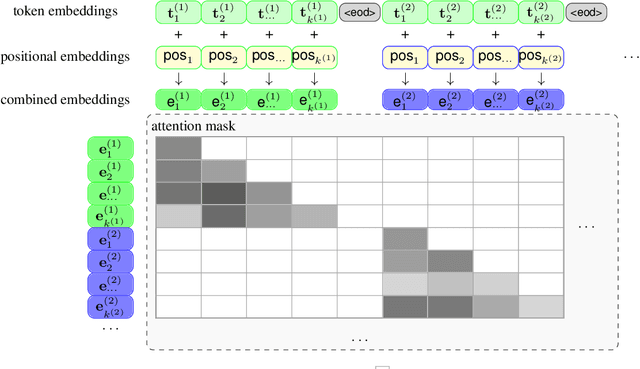
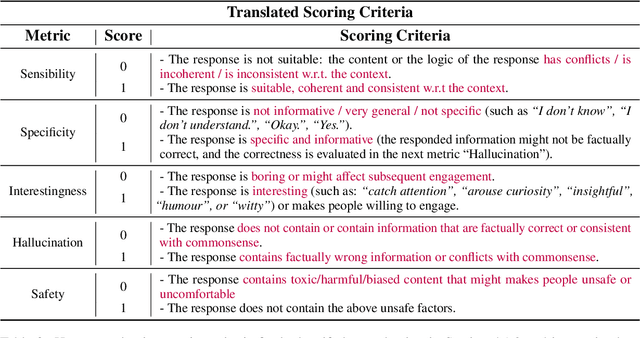
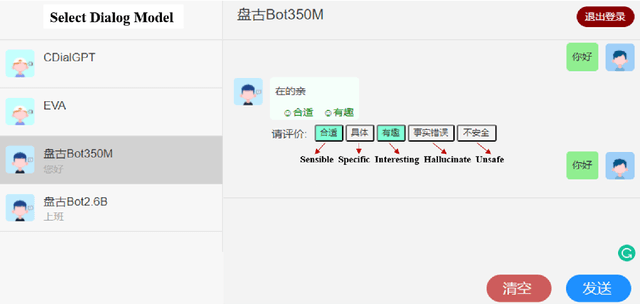
In this paper, we introduce PanGu-Bot, a Chinese pre-trained open-domain dialogue generation model based on a large pre-trained language model (PLM) PANGU-alpha (Zeng et al.,2021). Different from other pre-trained dialogue models trained over a massive amount of dialogue data from scratch, we aim to build a powerful dialogue model with relatively fewer data and computation costs by inheriting valuable language capabilities and knowledge from PLMs. To this end, we train PanGu-Bot from the large PLM PANGU-alpha, which has been proven well-performed on a variety of Chinese natural language tasks. We investigate different aspects of responses generated by PanGu-Bot, including response quality, knowledge, and safety. We show that PanGu-Bot outperforms state-of-the-art Chinese dialogue systems (CDIALGPT (Wang et al., 2020), EVA (Zhou et al., 2021)) w.r.t. the above three aspects. We also demonstrate that PanGu-Bot can be easily deployed to generate emotional responses without further training. Throughout our empirical analysis, we also point out that the PanGu-Bot response quality, knowledge correctness, and safety are still far from perfect, and further explorations are indispensable to building reliable and smart dialogue systems. Our model and code will be available at https://github.com/huawei-noah/Pretrained-Language-Model/tree/master/PanGu-Bot soon.
How Pre-trained Language Models Capture Factual Knowledge? A Causal-Inspired Analysis
Mar 31, 2022
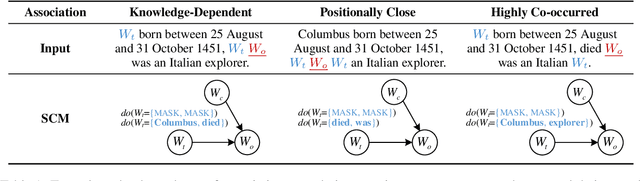
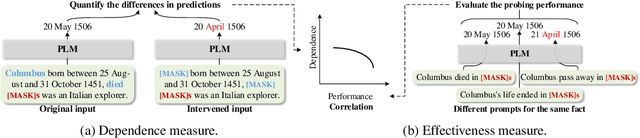
Recently, there has been a trend to investigate the factual knowledge captured by Pre-trained Language Models (PLMs). Many works show the PLMs' ability to fill in the missing factual words in cloze-style prompts such as "Dante was born in [MASK]." However, it is still a mystery how PLMs generate the results correctly: relying on effective clues or shortcut patterns? We try to answer this question by a causal-inspired analysis that quantitatively measures and evaluates the word-level patterns that PLMs depend on to generate the missing words. We check the words that have three typical associations with the missing words: knowledge-dependent, positionally close, and highly co-occurred. Our analysis shows: (1) PLMs generate the missing factual words more by the positionally close and highly co-occurred words than the knowledge-dependent words; (2) the dependence on the knowledge-dependent words is more effective than the positionally close and highly co-occurred words. Accordingly, we conclude that the PLMs capture the factual knowledge ineffectively because of depending on the inadequate associations.
Enabling Multimodal Generation on CLIP via Vision-Language Knowledge Distillation
Mar 30, 2022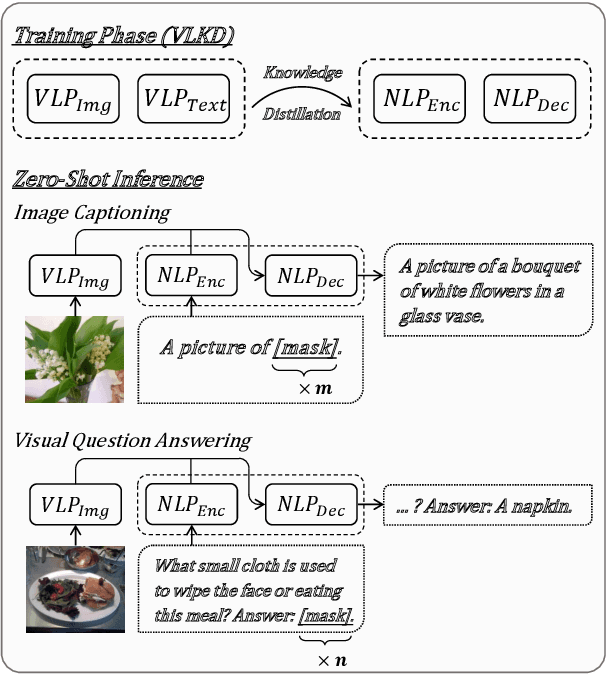
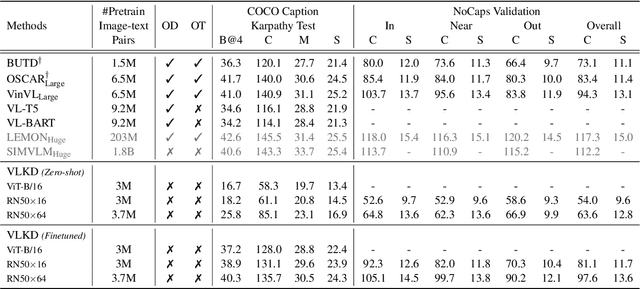
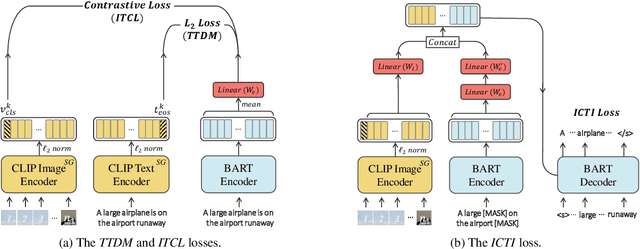
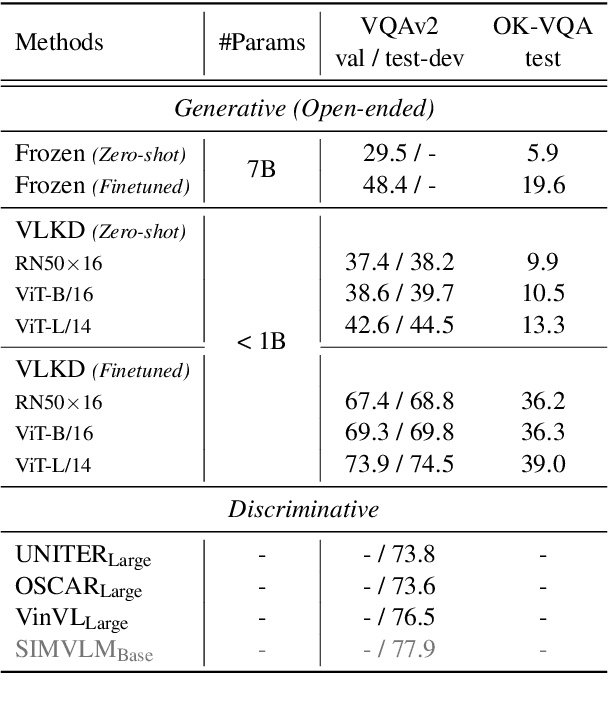
The recent large-scale vision-language pre-training (VLP) of dual-stream architectures (e.g., CLIP) with a tremendous amount of image-text pair data, has shown its superiority on various multimodal alignment tasks. Despite its success, the resulting models are not capable of multimodal generative tasks due to the weak text encoder. To tackle this problem, we propose to augment the dual-stream VLP model with a textual pre-trained language model (PLM) via vision-language knowledge distillation (VLKD), enabling the capability for multimodal generation. VLKD is pretty data- and computation-efficient compared to the pre-training from scratch. Experimental results show that the resulting model has strong zero-shot performance on multimodal generation tasks, such as open-ended visual question answering and image captioning. For example, it achieves 44.5% zero-shot accuracy on the VQAv2 dataset, surpassing the previous state-of-the-art zero-shot model with $7\times$ fewer parameters. Furthermore, the original textual language understanding and generation ability of the PLM is maintained after VLKD, which makes our model versatile for both multimodal and unimodal tasks.
Compression of Generative Pre-trained Language Models via Quantization
Mar 21, 2022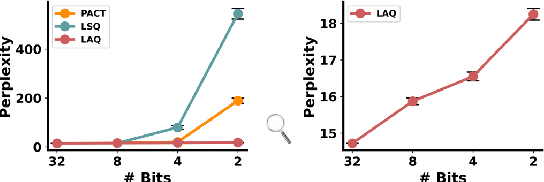
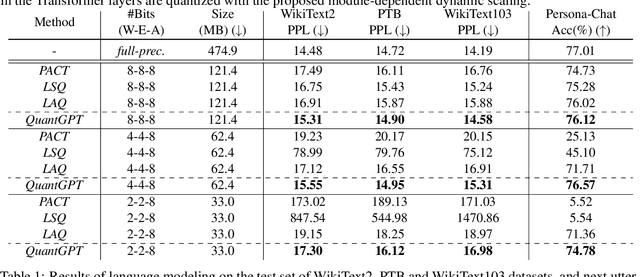

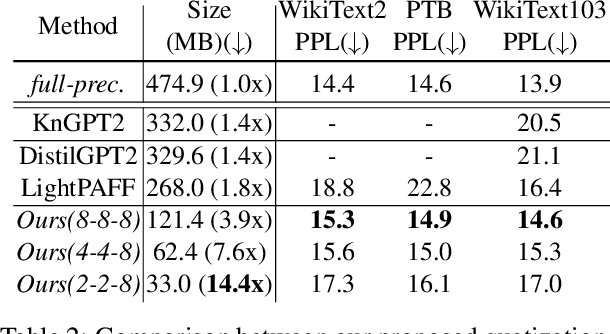
The increasing size of generative Pre-trained Language Models (PLMs) has greatly increased the demand for model compression. Despite various methods to compress BERT or its variants, there are few attempts to compress generative PLMs, and the underlying difficulty remains unclear. In this paper, we compress generative PLMs by quantization. We find that previous quantization methods fail on generative tasks due to the \textit{homogeneous word embeddings} caused by reduced capacity, and \textit{varied distribution of weights}. Correspondingly, we propose a token-level contrastive distillation to learn distinguishable word embeddings, and a module-wise dynamic scaling to make quantizers adaptive to different modules. Empirical results on various tasks show that our proposed method outperforms the state-of-the-art compression methods on generative PLMs by a clear margin. With comparable performance with the full-precision models, we achieve 14.4x and 13.4x compression rates on GPT-2 and BART, respectively.
Wukong: 100 Million Large-scale Chinese Cross-modal Pre-training Dataset and A Foundation Framework
Mar 10, 2022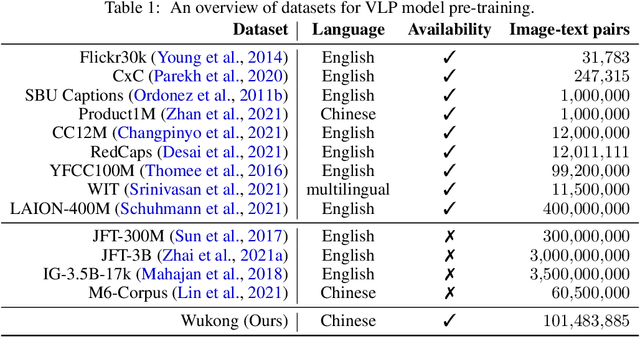
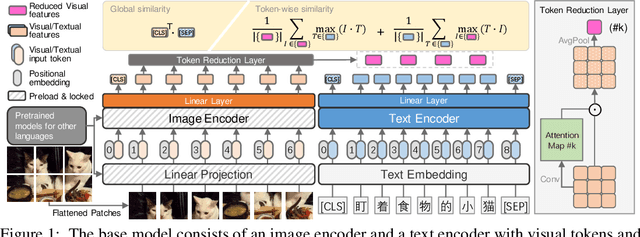


Vision-Language Pre-training (VLP) models have shown remarkable performance on various downstream tasks. Their success heavily relies on the scale of pre-trained cross-modal datasets. However, the lack of large-scale datasets and benchmarks in Chinese hinders the development of Chinese VLP models and broader multilingual applications. In this work, we release a large-scale Chinese cross-modal dataset named Wukong, containing 100 million Chinese image-text pairs from the web. Wukong aims to benchmark different multi-modal pre-training methods to facilitate the VLP research and community development. Furthermore, we release a group of models pre-trained with various image encoders (ViT-B/ViT-L/SwinT) and also apply advanced pre-training techniques into VLP such as locked-image text tuning, token-wise similarity in contrastive learning, and reduced-token interaction. Extensive experiments and a deep benchmarking of different downstream tasks are also provided. Experiments show that Wukong can serve as a promising Chinese pre-training dataset and benchmark for different cross-modal learning methods. For the zero-shot image classification task on 10 datasets, our model achieves an average accuracy of 73.03%. For the image-text retrieval task,our model achieves a mean recall of 71.6% on AIC-ICC which is 12.9% higher than the result of WenLan 2.0. More information can refer to https://wukong-dataset.github.io/wukong-dataset/.