 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDVD-Quant: Data-free Video Diffusion Transformers Quantization
May 24, 2025Diffusion Transformers (DiTs) have emerged as the state-of-the-art architecture for video generation, yet their computational and memory demands hinder practical deployment. While post-training quantization (PTQ) presents a promising approach to accelerate Video DiT models, existing methods suffer from two critical limitations: (1) dependence on lengthy, computation-heavy calibration procedures, and (2) considerable performance deterioration after quantization. To address these challenges, we propose DVD-Quant, a novel Data-free quantization framework for Video DiTs. Our approach integrates three key innovations: (1) Progressive Bounded Quantization (PBQ) and (2) Auto-scaling Rotated Quantization (ARQ) for calibration data-free quantization error reduction, as well as (3) $\delta$-Guided Bit Switching ($\delta$-GBS) for adaptive bit-width allocation. Extensive experiments across multiple video generation benchmarks demonstrate that DVD-Quant achieves an approximately 2$\times$ speedup over full-precision baselines on HunyuanVideo while maintaining visual fidelity. Notably, DVD-Quant is the first to enable W4A4 PTQ for Video DiTs without compromising video quality. Code and models will be available at https://github.com/lhxcs/DVD-Quant.
Why Can Accurate Models Be Learned from Inaccurate Annotations?
May 22, 2025



Learning from inaccurate annotations has gained significant attention due to the high cost of precise labeling. However, despite the presence of erroneous labels, models trained on noisy data often retain the ability to make accurate predictions. This intriguing phenomenon raises a fundamental yet largely unexplored question: why models can still extract correct label information from inaccurate annotations remains unexplored. In this paper, we conduct a comprehensive investigation into this issue. By analyzing weight matrices from both empirical and theoretical perspectives, we find that label inaccuracy primarily accumulates noise in lower singular components and subtly perturbs the principal subspace. Within a certain range, the principal subspaces of weights trained on inaccurate labels remain largely aligned with those learned from clean labels, preserving essential task-relevant information. We formally prove that the angles of principal subspaces exhibit minimal deviation under moderate label inaccuracy, explaining why models can still generalize effectively. Building on these insights, we propose LIP, a lightweight plug-in designed to help classifiers retain principal subspace information while mitigating noise induced by label inaccuracy. Extensive experiments on tasks with various inaccuracy conditions demonstrate that LIP consistently enhances the performance of existing algorithms. We hope our findings can offer valuable theoretical and practical insights to understand of model robustness under inaccurate supervision.
NAN: A Training-Free Solution to Coefficient Estimation in Model Merging
May 22, 2025Model merging offers a training-free alternative to multi-task learning by combining independently fine-tuned models into a unified one without access to raw data. However, existing approaches often rely on heuristics to determine the merging coefficients, limiting their scalability and generality. In this work, we revisit model merging through the lens of least-squares optimization and show that the optimal merging weights should scale with the amount of task-specific information encoded in each model. Based on this insight, we propose NAN, a simple yet effective method that estimates model merging coefficients via the inverse of parameter norm. NAN is training-free, plug-and-play, and applicable to a wide range of merging strategies. Extensive experiments on show that NAN consistently improves performance of baseline methods.
AutoBio: A Simulation and Benchmark for Robotic Automation in Digital Biology Laboratory
May 20, 2025Vision-language-action (VLA) models have shown promise as generalist robotic policies by jointly leveraging visual, linguistic, and proprioceptive modalities to generate action trajectories. While recent benchmarks have advanced VLA research in domestic tasks, professional science-oriented domains remain underexplored. We introduce AutoBio, a simulation framework and benchmark designed to evaluate robotic automation in biology laboratory environments--an application domain that combines structured protocols with demanding precision and multimodal interaction. AutoBio extends existing simulation capabilities through a pipeline for digitizing real-world laboratory instruments, specialized physics plugins for mechanisms ubiquitous in laboratory workflows, and a rendering stack that support dynamic instrument interfaces and transparent materials through physically based rendering. Our benchmark comprises biologically grounded tasks spanning three difficulty levels, enabling standardized evaluation of language-guided robotic manipulation in experimental protocols. We provide infrastructure for demonstration generation and seamless integration with VLA models. Baseline evaluations with two SOTA VLA models reveal significant gaps in precision manipulation, visual reasoning, and instruction following in scientific workflows. By releasing AutoBio, we aim to catalyze research on generalist robotic systems for complex, high-precision, and multimodal professional environments. The simulator and benchmark are publicly available to facilitate reproducible research.
Your Offline Policy is Not Trustworthy: Bilevel Reinforcement Learning for Sequential Portfolio Optimization
May 19, 2025Reinforcement learning (RL) has shown significant promise for sequential portfolio optimization tasks, such as stock trading, where the objective is to maximize cumulative returns while minimizing risks using historical data. However, traditional RL approaches often produce policies that merely memorize the optimal yet impractical buying and selling behaviors within the fixed dataset. These offline policies are less generalizable as they fail to account for the non-stationary nature of the market. Our approach, MetaTrader, frames portfolio optimization as a new type of partial-offline RL problem and makes two technical contributions. First, MetaTrader employs a bilevel learning framework that explicitly trains the RL agent to improve both in-domain profits on the original dataset and out-of-domain performance across diverse transformations of the raw financial data. Second, our approach incorporates a new temporal difference (TD) method that approximates worst-case TD estimates from a batch of transformed TD targets, addressing the value overestimation issue that is particularly challenging in scenarios with limited offline data. Our empirical results on two public stock datasets show that MetaTrader outperforms existing methods, including both RL-based approaches and traditional stock prediction models.
Video-Enhanced Offline Reinforcement Learning: A Model-Based Approach
May 10, 2025Offline reinforcement learning (RL) enables policy optimization in static datasets, avoiding the risks and costs of real-world exploration. However, it struggles with suboptimal behavior learning and inaccurate value estimation due to the lack of environmental interaction. In this paper, we present Video-Enhanced Offline RL (VeoRL), a model-based approach that constructs an interactive world model from diverse, unlabeled video data readily available online. Leveraging model-based behavior guidance, VeoRL transfers commonsense knowledge of control policy and physical dynamics from natural videos to the RL agent within the target domain. Our method achieves substantial performance gains (exceeding 100% in some cases) across visuomotor control tasks in robotic manipulation, autonomous driving, and open-world video games.
Low-bit Model Quantization for Deep Neural Networks: A Survey
May 08, 2025

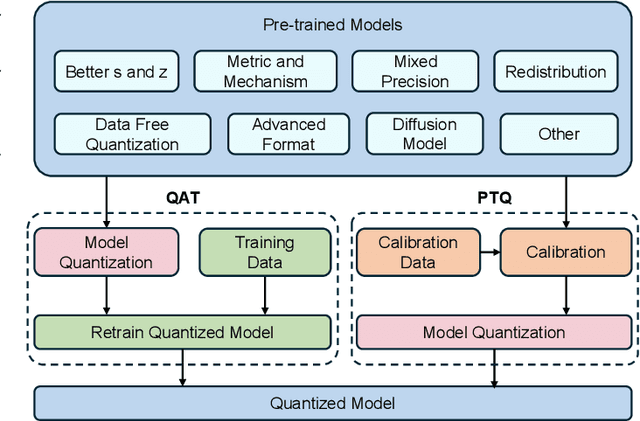
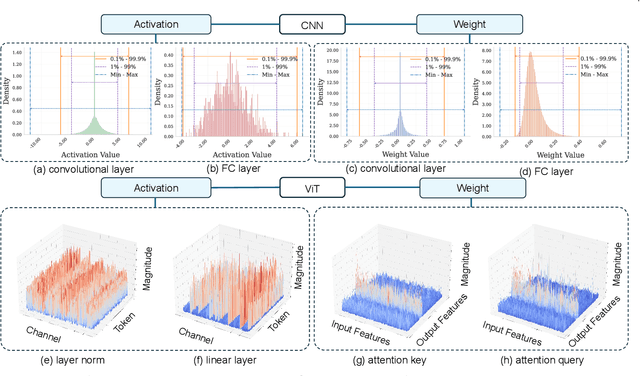
With unprecedented rapid development, deep neural networks (DNNs) have deeply influenced almost all fields. However, their heavy computation costs and model sizes are usually unacceptable in real-world deployment. Model quantization, an effective weight-lighting technique, has become an indispensable procedure in the whole deployment pipeline. The essence of quantization acceleration is the conversion from continuous floating-point numbers to discrete integer ones, which significantly speeds up the memory I/O and calculation, i.e., addition and multiplication. However, performance degradation also comes with the conversion because of the loss of precision. Therefore, it has become increasingly popular and critical to investigate how to perform the conversion and how to compensate for the information loss. This article surveys the recent five-year progress towards low-bit quantization on DNNs. We discuss and compare the state-of-the-art quantization methods and classify them into 8 main categories and 24 sub-categories according to their core techniques. Furthermore, we shed light on the potential research opportunities in the field of model quantization. A curated list of model quantization is provided at https://github.com/Kai-Liu001/Awesome-Model-Quantization.
Plasticine: Accelerating Research in Plasticity-Motivated Deep Reinforcement Learning
Apr 24, 2025Developing lifelong learning agents is crucial for artificial general intelligence. However, deep reinforcement learning (RL) systems often suffer from plasticity loss, where neural networks gradually lose their ability to adapt during training. Despite its significance, this field lacks unified benchmarks and evaluation protocols. We introduce Plasticine, the first open-source framework for benchmarking plasticity optimization in deep RL. Plasticine provides single-file implementations of over 13 mitigation methods, 10 evaluation metrics, and learning scenarios with increasing non-stationarity levels from standard to open-ended environments. This framework enables researchers to systematically quantify plasticity loss, evaluate mitigation strategies, and analyze plasticity dynamics across different contexts. Our documentation, examples, and source code are available at https://github.com/RLE-Foundation/Plasticine.
Generalized Tensor-based Parameter-Efficient Fine-Tuning via Lie Group Transformations
Apr 01, 2025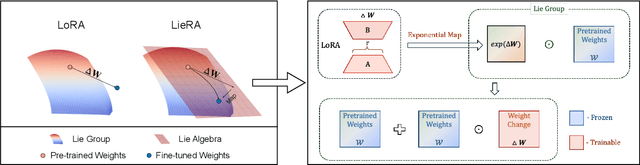
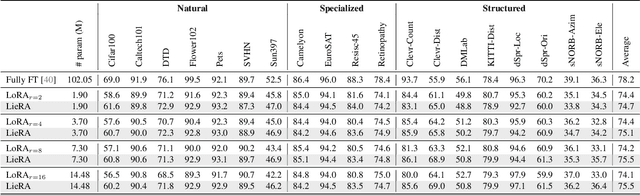
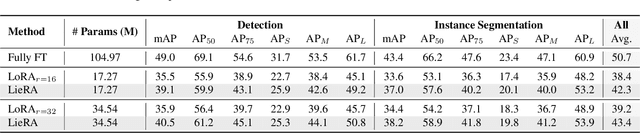

Adapting pre-trained foundation models for diverse downstream tasks is a core practice in artificial intelligence. However, the wide range of tasks and high computational costs make full fine-tuning impractical. To overcome this, parameter-efficient fine-tuning (PEFT) methods like LoRA have emerged and are becoming a growing research focus. Despite the success of these methods, they are primarily designed for linear layers, focusing on two-dimensional matrices while largely ignoring higher-dimensional parameter spaces like convolutional kernels. Moreover, directly applying these methods to higher-dimensional parameter spaces often disrupts their structural relationships. Given the rapid advancements in matrix-based PEFT methods, rather than designing a specialized strategy, we propose a generalization that extends matrix-based PEFT methods to higher-dimensional parameter spaces without compromising their structural properties. Specifically, we treat parameters as elements of a Lie group, with updates modeled as perturbations in the corresponding Lie algebra. These perturbations are mapped back to the Lie group through the exponential map, ensuring smooth, consistent updates that preserve the inherent structure of the parameter space. Extensive experiments on computer vision and natural language processing validate the effectiveness and versatility of our approach, demonstrating clear improvements over existing methods.
Dereflection Any Image with Diffusion Priors and Diversified Data
Mar 21, 2025Reflection removal of a single image remains a highly challenging task due to the complex entanglement between target scenes and unwanted reflections. Despite significant progress, existing methods are hindered by the scarcity of high-quality, diverse data and insufficient restoration priors, resulting in limited generalization across various real-world scenarios. In this paper, we propose Dereflection Any Image, a comprehensive solution with an efficient data preparation pipeline and a generalizable model for robust reflection removal. First, we introduce a dataset named Diverse Reflection Removal (DRR) created by randomly rotating reflective mediums in target scenes, enabling variation of reflection angles and intensities, and setting a new benchmark in scale, quality, and diversity. Second, we propose a diffusion-based framework with one-step diffusion for deterministic outputs and fast inference. To ensure stable learning, we design a three-stage progressive training strategy, including reflection-invariant finetuning to encourage consistent outputs across varying reflection patterns that characterize our dataset. Extensive experiments show that our method achieves SOTA performance on both common benchmarks and challenging in-the-wild images, showing superior generalization across diverse real-world scenes.