 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedAFD: Multimodal Federated Learning via Adversarial Fusion and Distillation
Mar 05, 2026Multimodal Federated Learning (MFL) enables clients with heterogeneous data modalities to collaboratively train models without sharing raw data, offering a privacy-preserving framework that leverages complementary cross-modal information. However, existing methods often overlook personalized client performance and struggle with modality/task discrepancies, as well as model heterogeneity. To address these challenges, we propose FedAFD, a unified MFL framework that enhances client and server learning. On the client side, we introduce a bi-level adversarial alignment strategy to align local and global representations within and across modalities, mitigating modality and task gaps. We further design a granularity-aware fusion module to integrate global knowledge into the personalized features adaptively. On the server side, to handle model heterogeneity, we propose a similarity-guided ensemble distillation mechanism that aggregates client representations on shared public data based on feature similarity and distills the fused knowledge into the global model. Extensive experiments conducted under both IID and non-IID settings demonstrate that FedAFD achieves superior performance and efficiency for both the client and the server.
Monocular Normal Estimation via Shading Sequence Estimation
Feb 11, 2026Monocular normal estimation aims to estimate the normal map from a single RGB image of an object under arbitrary lights. Existing methods rely on deep models to directly predict normal maps. However, they often suffer from 3D misalignment: while the estimated normal maps may appear to have a correct appearance, the reconstructed surfaces often fail to align with the geometric details. We argue that this misalignment stems from the current paradigm: the model struggles to distinguish and reconstruct varying geometry represented in normal maps, as the differences in underlying geometry are reflected only through relatively subtle color variations. To address this issue, we propose a new paradigm that reformulates normal estimation as shading sequence estimation, where shading sequences are more sensitive to various geometric information. Building on this paradigm, we present RoSE, a method that leverages image-to-video generative models to predict shading sequences. The predicted shading sequences are then converted into normal maps by solving a simple ordinary least-squares problem. To enhance robustness and better handle complex objects, RoSE is trained on a synthetic dataset, MultiShade, with diverse shapes, materials, and light conditions. Experiments demonstrate that RoSE achieves state-of-the-art performance on real-world benchmark datasets for object-based monocular normal estimation.
DD-Ranking: Rethinking the Evaluation of Dataset Distillation
May 19, 2025



In recent years, dataset distillation has provided a reliable solution for data compression, where models trained on the resulting smaller synthetic datasets achieve performance comparable to those trained on the original datasets. To further improve the performance of synthetic datasets, various training pipelines and optimization objectives have been proposed, greatly advancing the field of dataset distillation. Recent decoupled dataset distillation methods introduce soft labels and stronger data augmentation during the post-evaluation phase and scale dataset distillation up to larger datasets (e.g., ImageNet-1K). However, this raises a question: Is accuracy still a reliable metric to fairly evaluate dataset distillation methods? Our empirical findings suggest that the performance improvements of these methods often stem from additional techniques rather than the inherent quality of the images themselves, with even randomly sampled images achieving superior results. Such misaligned evaluation settings severely hinder the development of DD. Therefore, we propose DD-Ranking, a unified evaluation framework, along with new general evaluation metrics to uncover the true performance improvements achieved by different methods. By refocusing on the actual information enhancement of distilled datasets, DD-Ranking provides a more comprehensive and fair evaluation standard for future research advancements.
Low-bit Model Quantization for Deep Neural Networks: A Survey
May 08, 2025

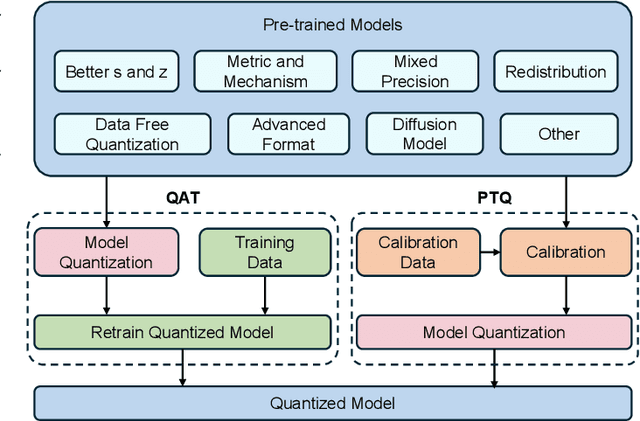
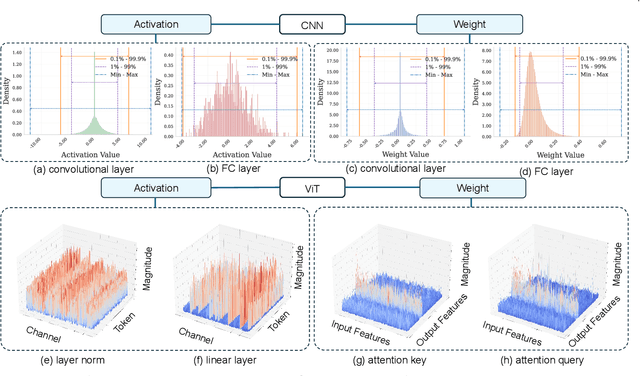
With unprecedented rapid development, deep neural networks (DNNs) have deeply influenced almost all fields. However, their heavy computation costs and model sizes are usually unacceptable in real-world deployment. Model quantization, an effective weight-lighting technique, has become an indispensable procedure in the whole deployment pipeline. The essence of quantization acceleration is the conversion from continuous floating-point numbers to discrete integer ones, which significantly speeds up the memory I/O and calculation, i.e., addition and multiplication. However, performance degradation also comes with the conversion because of the loss of precision. Therefore, it has become increasingly popular and critical to investigate how to perform the conversion and how to compensate for the information loss. This article surveys the recent five-year progress towards low-bit quantization on DNNs. We discuss and compare the state-of-the-art quantization methods and classify them into 8 main categories and 24 sub-categories according to their core techniques. Furthermore, we shed light on the potential research opportunities in the field of model quantization. A curated list of model quantization is provided at https://github.com/Kai-Liu001/Awesome-Model-Quantization.
Safe Reinforcement Learning using Finite-Horizon Gradient-based Estimation
Dec 15, 2024



A key aspect of Safe Reinforcement Learning (Safe RL) involves estimating the constraint condition for the next policy, which is crucial for guiding the optimization of safe policy updates. However, the existing Advantage-based Estimation (ABE) method relies on the infinite-horizon discounted advantage function. This dependence leads to catastrophic errors in finite-horizon scenarios with non-discounted constraints, resulting in safety-violation updates. In response, we propose the first estimation method for finite-horizon non-discounted constraints in deep Safe RL, termed Gradient-based Estimation (GBE), which relies on the analytic gradient derived along trajectories. Our theoretical and empirical analyses demonstrate that GBE can effectively estimate constraint changes over a finite horizon. Constructing a surrogate optimization problem with GBE, we developed a novel Safe RL algorithm called Constrained Gradient-based Policy Optimization (CGPO). CGPO identifies feasible optimal policies by iteratively resolving sub-problems within trust regions. Our empirical results reveal that CGPO, unlike baseline algorithms, successfully estimates the constraint functions of subsequent policies, thereby ensuring the efficiency and feasibility of each update.
Copiloting Diagnosis of Autism in Real Clinical Scenarios via LLMs
Oct 10, 2024



Autism spectrum disorder(ASD) is a pervasive developmental disorder that significantly impacts the daily functioning and social participation of individuals. Despite the abundance of research focused on supporting the clinical diagnosis of ASD, there is still a lack of systematic and comprehensive exploration in the field of methods based on Large Language Models (LLMs), particularly regarding the real-world clinical diagnostic scenarios based on Autism Diagnostic Observation Schedule, Second Edition (ADOS-2). Therefore, we have proposed a framework called ADOS-Copilot, which strikes a balance between scoring and explanation and explored the factors that influence the performance of LLMs in this task. The experimental results indicate that our proposed framework is competitive with the diagnostic results of clinicians, with a minimum MAE of 0.4643, binary classification F1-score of 81.79\%, and ternary classification F1-score of 78.37\%. Furthermore, we have systematically elucidated the strengths and limitations of current LLMs in this task from the perspectives of ADOS-2, LLMs' capabilities, language, and model scale aiming to inspire and guide the future application of LLMs in a broader fields of mental health disorders. We hope for more research to be transferred into real clinical practice, opening a window of kindness to the world for eccentric children.
Spiking GS: Towards High-Accuracy and Low-Cost Surface Reconstruction via Spiking Neuron-based Gaussian Splatting
Oct 09, 20243D Gaussian Splatting is capable of reconstructing 3D scenes in minutes. Despite recent advances in improving surface reconstruction accuracy, the reconstructed results still exhibit bias and suffer from inefficiency in storage and training. This paper provides a different observation on the cause of the inefficiency and the reconstruction bias, which is attributed to the integration of the low-opacity parts (LOPs) of the generated Gaussians. We show that LOPs consist of Gaussians with overall low-opacity (LOGs) and the low-opacity tails (LOTs) of Gaussians. We propose Spiking GS to reduce such two types of LOPs by integrating spiking neurons into the Gaussian Splatting pipeline. Specifically, we introduce global and local full-precision integrate-and-fire spiking neurons to the opacity and representation function of flattened 3D Gaussians, respectively. Furthermore, we enhance the density control strategy with spiking neurons' thresholds and an new criterion on the scale of Gaussians. Our method can represent more accurate reconstructed surfaces at a lower cost. The code is available at \url{https://github.com/shippoT/Spiking_GS}.
Connecting Consistency Distillation to Score Distillation for Text-to-3D Generation
Jul 18, 2024Although recent advancements in text-to-3D generation have significantly improved generation quality, issues like limited level of detail and low fidelity still persist, which requires further improvement. To understand the essence of those issues, we thoroughly analyze current score distillation methods by connecting theories of consistency distillation to score distillation. Based on the insights acquired through analysis, we propose an optimization framework, Guided Consistency Sampling (GCS), integrated with 3D Gaussian Splatting (3DGS) to alleviate those issues. Additionally, we have observed the persistent oversaturation in the rendered views of generated 3D assets. From experiments, we find that it is caused by unwanted accumulated brightness in 3DGS during optimization. To mitigate this issue, we introduce a Brightness-Equalized Generation (BEG) scheme in 3DGS rendering. Experimental results demonstrate that our approach generates 3D assets with more details and higher fidelity than state-of-the-art methods. The codes are released at https://github.com/LMozart/ECCV2024-GCS-BEG.
Off-OAB: Off-Policy Policy Gradient Method with Optimal Action-Dependent Baseline
May 04, 2024



Policy-based methods have achieved remarkable success in solving challenging reinforcement learning problems. Among these methods, off-policy policy gradient methods are particularly important due to that they can benefit from off-policy data. However, these methods suffer from the high variance of the off-policy policy gradient (OPPG) estimator, which results in poor sample efficiency during training. In this paper, we propose an off-policy policy gradient method with the optimal action-dependent baseline (Off-OAB) to mitigate this variance issue. Specifically, this baseline maintains the OPPG estimator's unbiasedness while theoretically minimizing its variance. To enhance practical computational efficiency, we design an approximated version of this optimal baseline. Utilizing this approximation, our method (Off-OAB) aims to decrease the OPPG estimator's variance during policy optimization. We evaluate the proposed Off-OAB method on six representative tasks from OpenAI Gym and MuJoCo, where it demonstrably surpasses state-of-the-art methods on the majority of these tasks.
Spin-UP: Spin Light for Natural Light Uncalibrated Photometric Stereo
Apr 02, 2024



Natural Light Uncalibrated Photometric Stereo (NaUPS) relieves the strict environment and light assumptions in classical Uncalibrated Photometric Stereo (UPS) methods. However, due to the intrinsic ill-posedness and high-dimensional ambiguities, addressing NaUPS is still an open question. Existing works impose strong assumptions on the environment lights and objects' material, restricting the effectiveness in more general scenarios. Alternatively, some methods leverage supervised learning with intricate models while lacking interpretability, resulting in a biased estimation. In this work, we proposed Spin Light Uncalibrated Photometric Stereo (Spin-UP), an unsupervised method to tackle NaUPS in various environment lights and objects. The proposed method uses a novel setup that captures the object's images on a rotatable platform, which mitigates NaUPS's ill-posedness by reducing unknowns and provides reliable priors to alleviate NaUPS's ambiguities. Leveraging neural inverse rendering and the proposed training strategies, Spin-UP recovers surface normals, environment light, and isotropic reflectance under complex natural light with low computational cost. Experiments have shown that Spin-UP outperforms other supervised / unsupervised NaUPS methods and achieves state-of-the-art performance on synthetic and real-world datasets. Codes and data are available at https://github.com/LMozart/CVPR2024-SpinUP.