 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePermuQuant: Lowering Per-Group Quantization Error by Reordering Channels for Diffusion Models
May 10, 2026Large-scale visual generative models have achieved remarkable performance. However, their high computational and memory costs make deployment challenging in resource-constrained scenarios, such as interactive applications and personal single-GPU usage. Post-training quantization (PTQ) offers a practical solution by compressing pretrained models without expensive retraining. However, existing PTQ methods still suffer from severe quality degradation under extremely low-bit settings. In this paper, we identify channel ordering as an important but underexplored factor in per-group quantization. In this setting, each contiguous group shares one quantization scale. When channels with very different statistics are placed in the same group, the scale can be dominated by outliers and cause large quantization errors. Based on this observation, we propose PermuQuant, a simple and effective PTQ framework for low-bit diffusion models. PermuQuant sorts channels by a joint second-moment criterion before per-group quantization, placing channels with similar activation and weight statistics into the same group. It further uses a calibration-based acceptance rule to apply reordering only when the selected permutation reduces quantization error on calibration data. The selected permutations are absorbed into adjacent modules or applied to weights offline, avoiding explicit runtime permutation operations. Extensive experiments on multiple large diffusion models show that PermuQuant consistently reduces quantization error and outperforms existing PTQ baselines. On FLUX.1-dev with an RTX 5090, PermuQuant achieves up to a 1.8$\times$ single step speedup and reduces the DiT memory footprint by 3.5$\times$ under W4A4 NVFP4 quantization. Code will be available at https://github.com/yscheng04/PermuQuant.
AcademiClaw: When Students Set Challenges for AI Agents
May 04, 2026Benchmarks within the OpenClaw ecosystem have thus far evaluated exclusively assistant-level tasks, leaving the academic-level capabilities of OpenClaw largely unexamined. We introduce AcademiClaw, a bilingual benchmark of 80 complex, long-horizon tasks sourced directly from university students' real academic workflows -- homework, research projects, competitions, and personal projects -- that they found current AI agents unable to solve effectively. Curated from 230 student-submitted candidates through rigorous expert review, the final task set spans 25+ professional domains, ranging from olympiad-level mathematics and linguistics problems to GPU-intensive reinforcement learning and full-stack system debugging, with 16 tasks requiring CUDA GPU execution. Each task executes in an isolated Docker sandbox and is scored on task completion by multi-dimensional rubrics combining six complementary techniques, with an independent five-category safety audit providing additional behavioral analysis. Experiments on six frontier models show that even the best achieves only a 55\% pass rate. Further analysis uncovers sharp capability boundaries across task domains, divergent behavioral strategies among models, and a disconnect between token consumption and output quality, providing fine-grained diagnostic signals beyond what aggregate metrics reveal. We hope that AcademiClaw and its open-sourced data and code can serve as a useful resource for the OpenClaw community, driving progress toward agents that are more capable and versatile across the full breadth of real-world academic demands. All data and code are available at https://github.com/GAIR-NLP/AcademiClaw.
Low-bit Model Quantization for Deep Neural Networks: A Survey
May 08, 2025

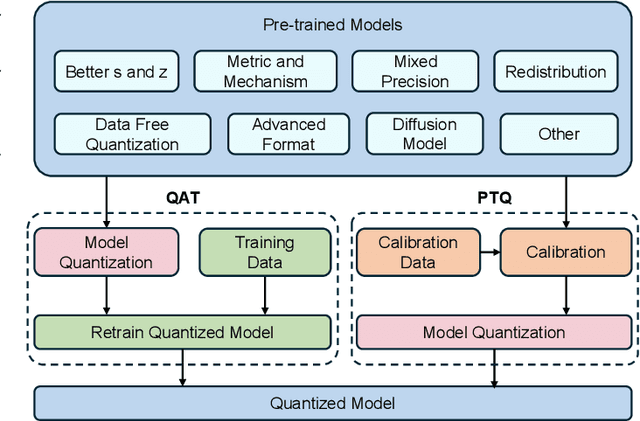
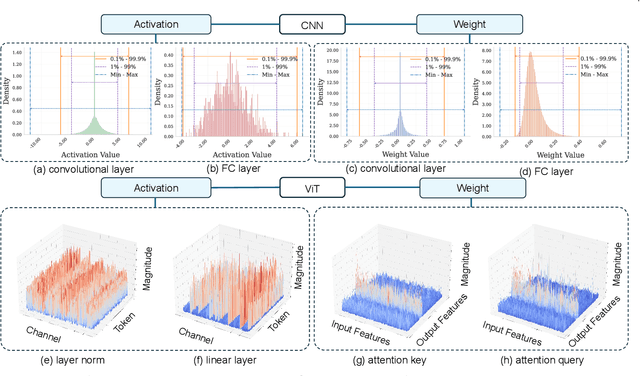
With unprecedented rapid development, deep neural networks (DNNs) have deeply influenced almost all fields. However, their heavy computation costs and model sizes are usually unacceptable in real-world deployment. Model quantization, an effective weight-lighting technique, has become an indispensable procedure in the whole deployment pipeline. The essence of quantization acceleration is the conversion from continuous floating-point numbers to discrete integer ones, which significantly speeds up the memory I/O and calculation, i.e., addition and multiplication. However, performance degradation also comes with the conversion because of the loss of precision. Therefore, it has become increasingly popular and critical to investigate how to perform the conversion and how to compensate for the information loss. This article surveys the recent five-year progress towards low-bit quantization on DNNs. We discuss and compare the state-of-the-art quantization methods and classify them into 8 main categories and 24 sub-categories according to their core techniques. Furthermore, we shed light on the potential research opportunities in the field of model quantization. A curated list of model quantization is provided at https://github.com/Kai-Liu001/Awesome-Model-Quantization.