 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-bit Model Quantization for Deep Neural Networks: A Survey
Paper and Code


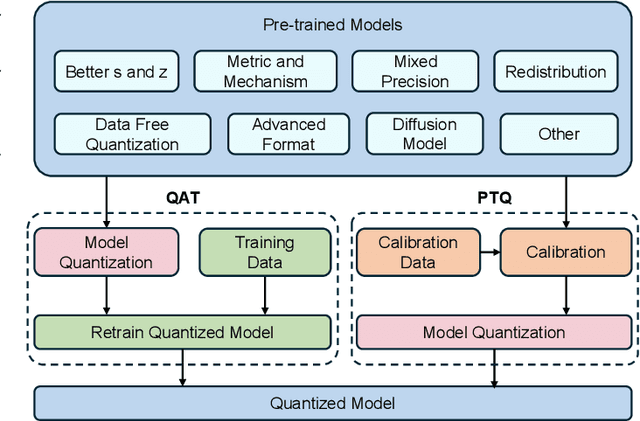
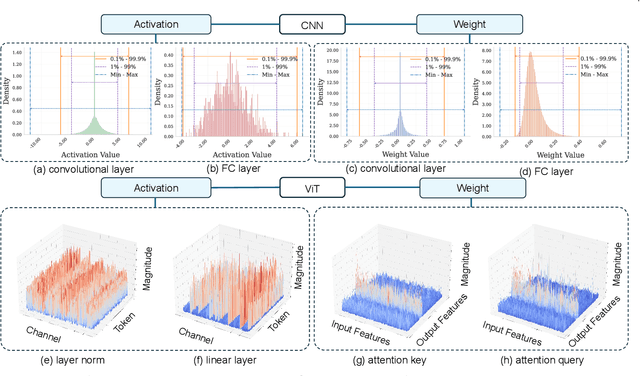
With unprecedented rapid development, deep neural networks (DNNs) have deeply influenced almost all fields. However, their heavy computation costs and model sizes are usually unacceptable in real-world deployment. Model quantization, an effective weight-lighting technique, has become an indispensable procedure in the whole deployment pipeline. The essence of quantization acceleration is the conversion from continuous floating-point numbers to discrete integer ones, which significantly speeds up the memory I/O and calculation, i.e., addition and multiplication. However, performance degradation also comes with the conversion because of the loss of precision. Therefore, it has become increasingly popular and critical to investigate how to perform the conversion and how to compensate for the information loss. This article surveys the recent five-year progress towards low-bit quantization on DNNs. We discuss and compare the state-of-the-art quantization methods and classify them into 8 main categories and 24 sub-categories according to their core techniques. Furthermore, we shed light on the potential research opportunities in the field of model quantization. A curated list of model quantization is provided at https://github.com/Kai-Liu001/Awesome-Model-Quantization.