 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo-Enhanced Offline Reinforcement Learning: A Model-Based Approach
May 10, 2025Offline reinforcement learning (RL) enables policy optimization in static datasets, avoiding the risks and costs of real-world exploration. However, it struggles with suboptimal behavior learning and inaccurate value estimation due to the lack of environmental interaction. In this paper, we present Video-Enhanced Offline RL (VeoRL), a model-based approach that constructs an interactive world model from diverse, unlabeled video data readily available online. Leveraging model-based behavior guidance, VeoRL transfers commonsense knowledge of control policy and physical dynamics from natural videos to the RL agent within the target domain. Our method achieves substantial performance gains (exceeding 100% in some cases) across visuomotor control tasks in robotic manipulation, autonomous driving, and open-world video games.
Open-World Reinforcement Learning over Long Short-Term Imagination
Oct 04, 2024



Training visual reinforcement learning agents in a high-dimensional open world presents significant challenges. While various model-based methods have improved sample efficiency by learning interactive world models, these agents tend to be "short-sighted", as they are typically trained on short snippets of imagined experiences. We argue that the primary obstacle in open-world decision-making is improving the efficiency of off-policy exploration across an extensive state space. In this paper, we present LS-Imagine, which extends the imagination horizon within a limited number of state transition steps, enabling the agent to explore behaviors that potentially lead to promising long-term feedback. The foundation of our approach is to build a long short-term world model. To achieve this, we simulate goal-conditioned jumpy state transitions and compute corresponding affordance maps by zooming in on specific areas within single images. This facilitates the integration of direct long-term values into behavior learning. Our method demonstrates significant improvements over state-of-the-art techniques in MineDojo.
Weighted Concordance Index Loss-based Multimodal Survival Modeling for Radiation Encephalopathy Assessment in Nasopharyngeal Carcinoma Radiotherapy
Jun 23, 2022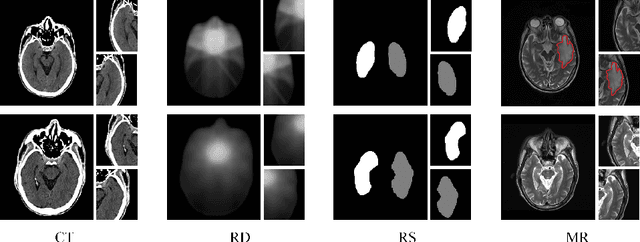
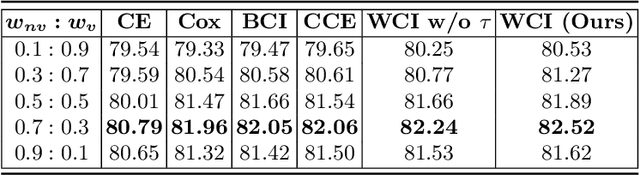
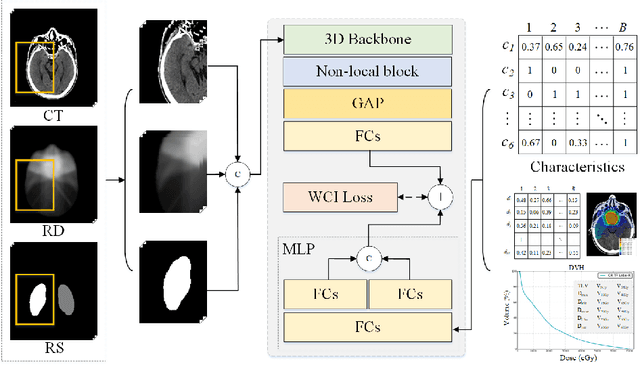
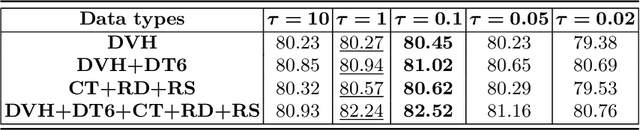
Radiation encephalopathy (REP) is the most common complication for nasopharyngeal carcinoma (NPC) radiotherapy. It is highly desirable to assist clinicians in optimizing the NPC radiotherapy regimen to reduce radiotherapy-induced temporal lobe injury (RTLI) according to the probability of REP onset. To the best of our knowledge, it is the first exploration of predicting radiotherapy-induced REP by jointly exploiting image and non-image data in NPC radiotherapy regimen. We cast REP prediction as a survival analysis task and evaluate the predictive accuracy in terms of the concordance index (CI). We design a deep multimodal survival network (MSN) with two feature extractors to learn discriminative features from multimodal data. One feature extractor imposes feature selection on non-image data, and the other learns visual features from images. Because the priorly balanced CI (BCI) loss function directly maximizing the CI is sensitive to uneven sampling per batch. Hence, we propose a novel weighted CI (WCI) loss function to leverage all REP samples effectively by assigning their different weights with a dual average operation. We further introduce a temperature hyper-parameter for our WCI to sharpen the risk difference of sample pairs to help model convergence. We extensively evaluate our WCI on a private dataset to demonstrate its favourability against its counterparts. The experimental results also show multimodal data of NPC radiotherapy can bring more gains for REP risk prediction.