 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Self-Regularized Adversarial Views for Self-Supervised Vision Transformers
Oct 16, 2022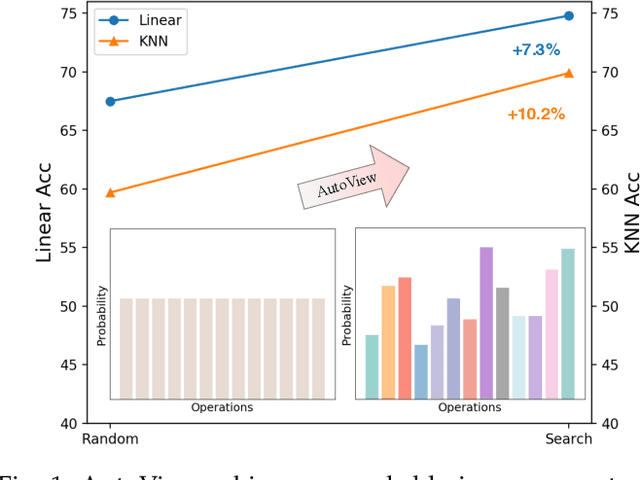
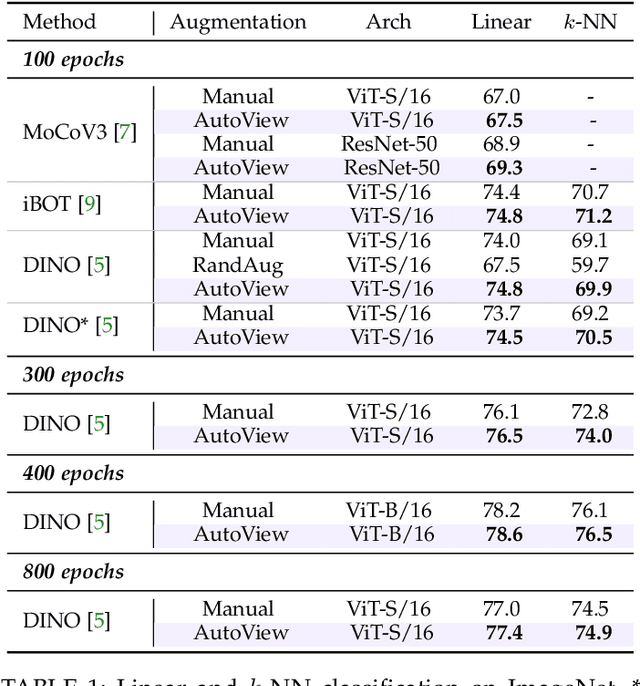
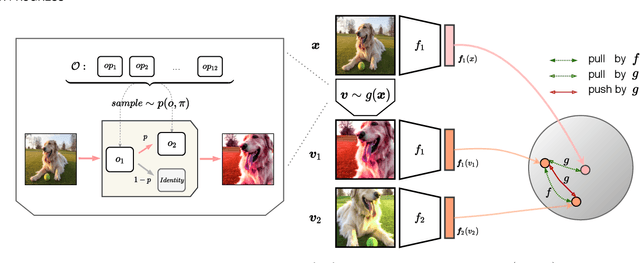

Automatic data augmentation (AutoAugment) strategies are indispensable in supervised data-efficient training protocols of vision transformers, and have led to state-of-the-art results in supervised learning. Despite the success, its development and application on self-supervised vision transformers have been hindered by several barriers, including the high search cost, the lack of supervision, and the unsuitable search space. In this work, we propose AutoView, a self-regularized adversarial AutoAugment method, to learn views for self-supervised vision transformers, by addressing the above barriers. First, we reduce the search cost of AutoView to nearly zero by learning views and network parameters simultaneously in a single forward-backward step, minimizing and maximizing the mutual information among different augmented views, respectively. Then, to avoid information collapse caused by the lack of label supervision, we propose a self-regularized loss term to guarantee the information propagation. Additionally, we present a curated augmentation policy search space for self-supervised learning, by modifying the generally used search space designed for supervised learning. On ImageNet, our AutoView achieves remarkable improvement over RandAug baseline (+10.2% k-NN accuracy), and consistently outperforms sota manually tuned view policy by a clear margin (up to +1.3% k-NN accuracy). Extensive experiments show that AutoView pretraining also benefits downstream tasks (+1.2% mAcc on ADE20K Semantic Segmentation and +2.8% mAP on revisited Oxford Image Retrieval benchmark) and improves model robustness (+2.3% Top-1 Acc on ImageNet-A and +1.0% AUPR on ImageNet-O). Code and models will be available at https://github.com/Trent-tangtao/AutoView.
Improving Multi-turn Emotional Support Dialogue Generation with Lookahead Strategy Planning
Oct 09, 2022
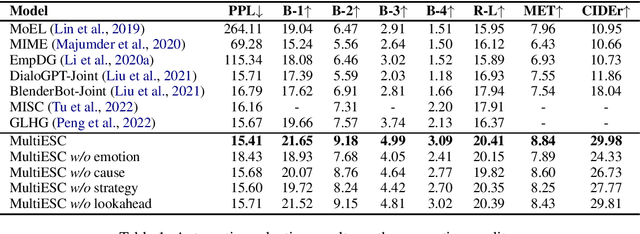
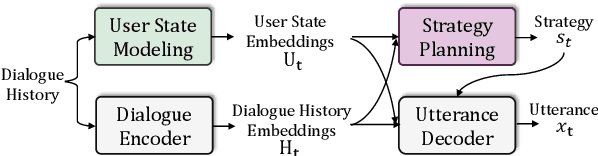
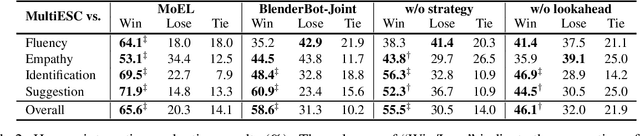
Providing Emotional Support (ES) to soothe people in emotional distress is an essential capability in social interactions. Most existing researches on building ES conversation systems only considered single-turn interactions with users, which was over-simplified. In comparison, multi-turn ES conversation systems can provide ES more effectively, but face several new technical challenges, including: (1) how to adopt appropriate support strategies to achieve the long-term dialogue goal of comforting the user's emotion; (2) how to dynamically model the user's state. In this paper, we propose a novel system MultiESC to address these issues. For strategy planning, drawing inspiration from the A* search algorithm, we propose lookahead heuristics to estimate the future user feedback after using particular strategies, which helps to select strategies that can lead to the best long-term effects. For user state modeling, MultiESC focuses on capturing users' subtle emotional expressions and understanding their emotion causes. Extensive experiments show that MultiESC significantly outperforms competitive baselines in both dialogue generation and strategy planning. Our codes are available at https://github.com/lwgkzl/MultiESC.
DetCLIP: Dictionary-Enriched Visual-Concept Paralleled Pre-training for Open-world Detection
Sep 20, 2022

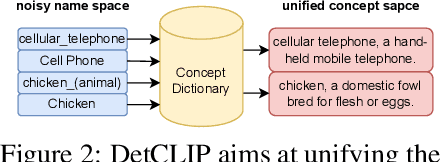

Open-world object detection, as a more general and challenging goal, aims to recognize and localize objects described by arbitrary category names. The recent work GLIP formulates this problem as a grounding problem by concatenating all category names of detection datasets into sentences, which leads to inefficient interaction between category names. This paper presents DetCLIP, a paralleled visual-concept pre-training method for open-world detection by resorting to knowledge enrichment from a designed concept dictionary. To achieve better learning efficiency, we propose a novel paralleled concept formulation that extracts concepts separately to better utilize heterogeneous datasets (i.e., detection, grounding, and image-text pairs) for training. We further design a concept dictionary~(with descriptions) from various online sources and detection datasets to provide prior knowledge for each concept. By enriching the concepts with their descriptions, we explicitly build the relationships among various concepts to facilitate the open-domain learning. The proposed concept dictionary is further used to provide sufficient negative concepts for the construction of the word-region alignment loss\, and to complete labels for objects with missing descriptions in captions of image-text pair data. The proposed framework demonstrates strong zero-shot detection performances, e.g., on the LVIS dataset, our DetCLIP-T outperforms GLIP-T by 9.9% mAP and obtains a 13.5% improvement on rare categories compared to the fully-supervised model with the same backbone as ours.
Effective Adaptation in Multi-Task Co-Training for Unified Autonomous Driving
Sep 19, 2022
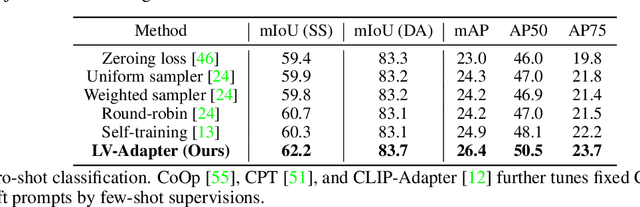
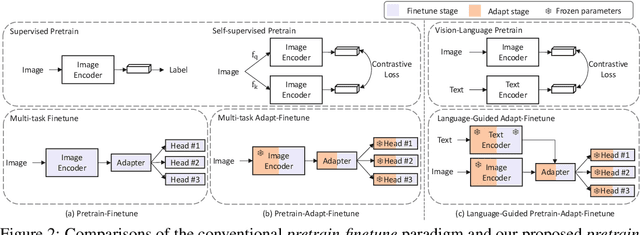
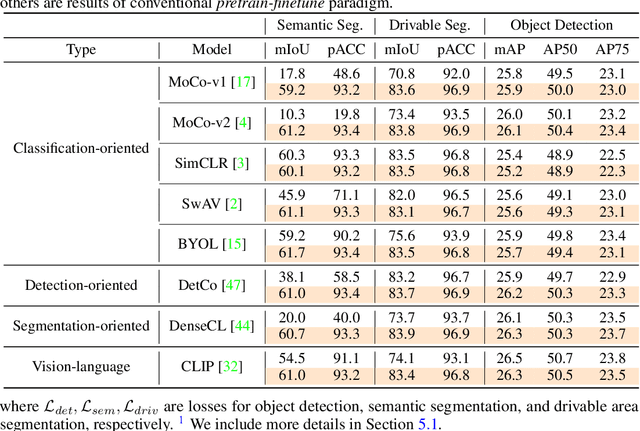
Aiming towards a holistic understanding of multiple downstream tasks simultaneously, there is a need for extracting features with better transferability. Though many latest self-supervised pre-training methods have achieved impressive performance on various vision tasks under the prevailing pretrain-finetune paradigm, their generalization capacity to multi-task learning scenarios is yet to be explored. In this paper, we extensively investigate the transfer performance of various types of self-supervised methods, e.g., MoCo and SimCLR, on three downstream tasks, including semantic segmentation, drivable area segmentation, and traffic object detection, on the large-scale driving dataset BDD100K. We surprisingly find that their performances are sub-optimal or even lag far behind the single-task baseline, which may be due to the distinctions of training objectives and architectural design lied in the pretrain-finetune paradigm. To overcome this dilemma as well as avoid redesigning the resource-intensive pre-training stage, we propose a simple yet effective pretrain-adapt-finetune paradigm for general multi-task training, where the off-the-shelf pretrained models can be effectively adapted without increasing the training overhead. During the adapt stage, we utilize learnable multi-scale adapters to dynamically adjust the pretrained model weights supervised by multi-task objectives while leaving the pretrained knowledge untouched. Furthermore, we regard the vision-language pre-training model CLIP as a strong complement to the pretrain-adapt-finetune paradigm and propose a novel adapter named LV-Adapter, which incorporates language priors in the multi-task model via task-specific prompting and alignment between visual and textual features.
ARMANI: Part-level Garment-Text Alignment for Unified Cross-Modal Fashion Design
Aug 11, 2022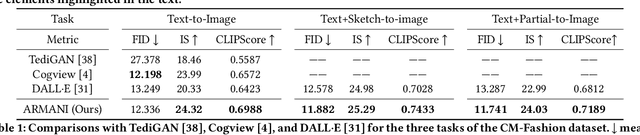

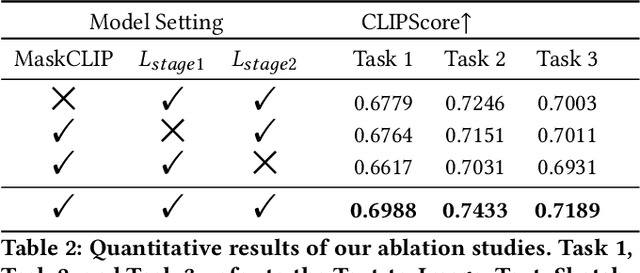
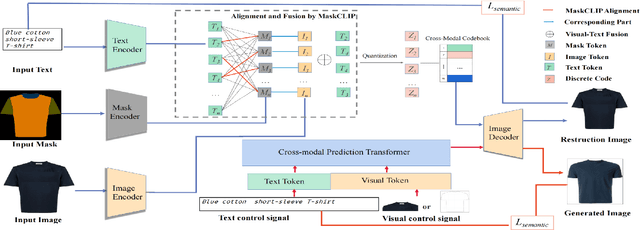
Cross-modal fashion image synthesis has emerged as one of the most promising directions in the generation domain due to the vast untapped potential of incorporating multiple modalities and the wide range of fashion image applications. To facilitate accurate generation, cross-modal synthesis methods typically rely on Contrastive Language-Image Pre-training (CLIP) to align textual and garment information. In this work, we argue that simply aligning texture and garment information is not sufficient to capture the semantics of the visual information and therefore propose MaskCLIP. MaskCLIP decomposes the garments into semantic parts, ensuring fine-grained and semantically accurate alignment between the visual and text information. Building on MaskCLIP, we propose ARMANI, a unified cross-modal fashion designer with part-level garment-text alignment. ARMANI discretizes an image into uniform tokens based on a learned cross-modal codebook in its first stage and uses a Transformer to model the distribution of image tokens for a real image given the tokens of the control signals in its second stage. Contrary to prior approaches that also rely on two-stage paradigms, ARMANI introduces textual tokens into the codebook, making it possible for the model to utilize fine-grain semantic information to generate more realistic images. Further, by introducing a cross-modal Transformer, ARMANI is versatile and can accomplish image synthesis from various control signals, such as pure text, sketch images, and partial images. Extensive experiments conducted on our newly collected cross-modal fashion dataset demonstrate that ARMANI generates photo-realistic images in diverse synthesis tasks and outperforms existing state-of-the-art cross-modal image synthesis approaches.Our code is available at https://github.com/Harvey594/ARMANI.
Composable Text Control Operations in Latent Space with Ordinary Differential Equations
Aug 01, 2022


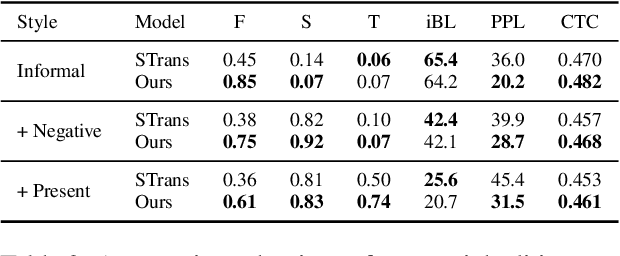
Real-world text applications often involve composing a wide range of text control operations, such as editing the text w.r.t. an attribute, manipulating keywords and structure, and generating new text of desired properties. Prior work typically learns/finetunes a language model (LM) to perform individual or specific subsets of operations. Recent research has studied combining operations in a plug-and-play manner, often with costly search or optimization in the complex sequence space. This paper proposes a new efficient approach for composable text operations in the compact latent space of text. The low-dimensionality and differentiability of the text latent vector allow us to develop an efficient sampler based on ordinary differential equations (ODEs) given arbitrary plug-in operators (e.g., attribute classifiers). By connecting pretrained LMs (e.g., GPT2) to the latent space through efficient adaption, we then decode the sampled vectors into desired text sequences. The flexible approach permits diverse control operators (sentiment, tense, formality, keywords, etc.) acquired using any relevant data from different domains. Experiments show that composing those operators within our approach manages to generate or edit high-quality text, substantially improving over previous methods in terms of generation quality and efficiency.
PASTA-GAN++: A Versatile Framework for High-Resolution Unpaired Virtual Try-on
Jul 27, 2022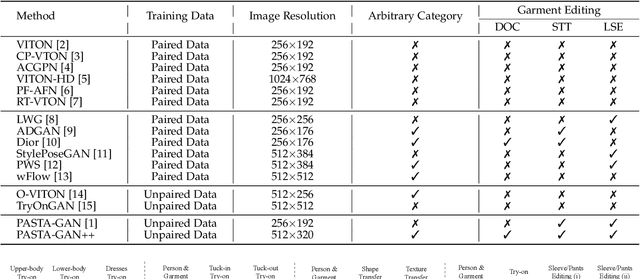

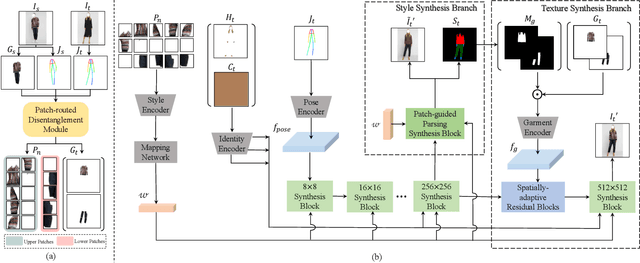

Image-based virtual try-on is one of the most promising applications of human-centric image generation due to its tremendous real-world potential. In this work, we take a step forwards to explore versatile virtual try-on solutions, which we argue should possess three main properties, namely, they should support unsupervised training, arbitrary garment categories, and controllable garment editing. To this end, we propose a characteristic-preserving end-to-end network, the PAtch-routed SpaTially-Adaptive GAN++ (PASTA-GAN++), to achieve a versatile system for high-resolution unpaired virtual try-on. Specifically, our PASTA-GAN++ consists of an innovative patch-routed disentanglement module to decouple the intact garment into normalized patches, which is capable of retaining garment style information while eliminating the garment spatial information, thus alleviating the overfitting issue during unsupervised training. Furthermore, PASTA-GAN++ introduces a patch-based garment representation and a patch-guided parsing synthesis block, allowing it to handle arbitrary garment categories and support local garment editing. Finally, to obtain try-on results with realistic texture details, PASTA-GAN++ incorporates a novel spatially-adaptive residual module to inject the coarse warped garment feature into the generator. Extensive experiments on our newly collected UnPaired virtual Try-on (UPT) dataset demonstrate the superiority of PASTA-GAN++ over existing SOTAs and its ability for controllable garment editing.
SiRi: A Simple Selective Retraining Mechanism for Transformer-based Visual Grounding
Jul 27, 2022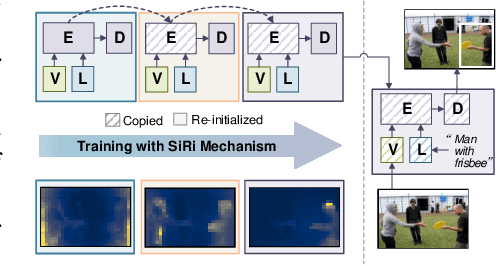
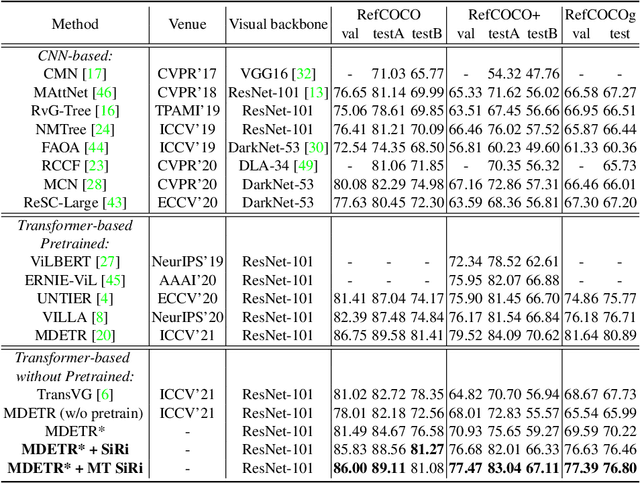
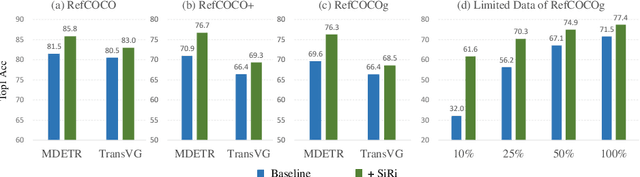
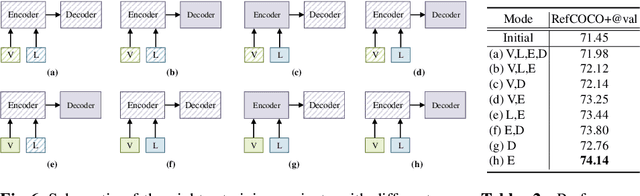
In this paper, we investigate how to achieve better visual grounding with modern vision-language transformers, and propose a simple yet powerful Selective Retraining (SiRi) mechanism for this challenging task. Particularly, SiRi conveys a significant principle to the research of visual grounding, i.e., a better initialized vision-language encoder would help the model converge to a better local minimum, advancing the performance accordingly. In specific, we continually update the parameters of the encoder as the training goes on, while periodically re-initialize rest of the parameters to compel the model to be better optimized based on an enhanced encoder. SiRi can significantly outperform previous approaches on three popular benchmarks. Specifically, our method achieves 83.04% Top1 accuracy on RefCOCO+ testA, outperforming the state-of-the-art approaches (training from scratch) by more than 10.21%. Additionally, we reveal that SiRi performs surprisingly superior even with limited training data. We also extend it to transformer-based visual grounding models and other vision-language tasks to verify the validity.
Open-world Semantic Segmentation via Contrasting and Clustering Vision-Language Embedding
Jul 19, 2022
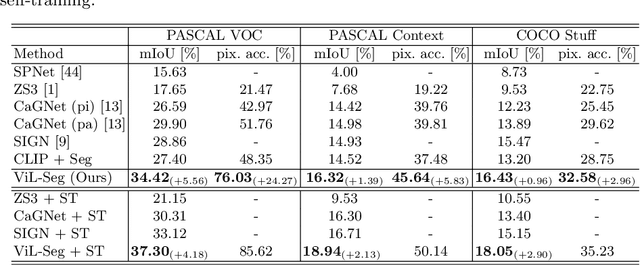
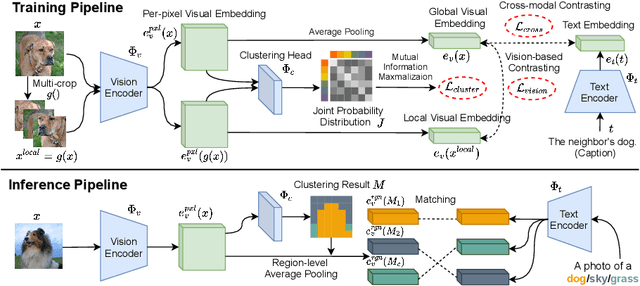
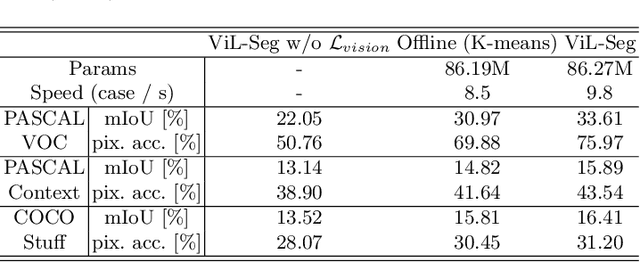
To bridge the gap between supervised semantic segmentation and real-world applications that acquires one model to recognize arbitrary new concepts, recent zero-shot segmentation attracts a lot of attention by exploring the relationships between unseen and seen object categories, yet requiring large amounts of densely-annotated data with diverse base classes. In this paper, we propose a new open-world semantic segmentation pipeline that makes the first attempt to learn to segment semantic objects of various open-world categories without any efforts on dense annotations, by purely exploiting the image-caption data that naturally exist on the Internet. Our method, Vision-language-driven Semantic Segmentation (ViL-Seg), employs an image and a text encoder to generate visual and text embeddings for the image-caption data, with two core components that endow its segmentation ability: First, the image encoder is jointly trained with a vision-based contrasting and a cross-modal contrasting, which encourage the visual embeddings to preserve both fine-grained semantics and high-level category information that are crucial for the segmentation task. Furthermore, an online clustering head is devised over the image encoder, which allows to dynamically segment the visual embeddings into distinct semantic groups such that they can be classified by comparing with various text embeddings to complete our segmentation pipeline. Experiments show that without using any data with dense annotations, our method can directly segment objects of arbitrary categories, outperforming zero-shot segmentation methods that require data labeling on three benchmark datasets.
Discourse-Aware Graph Networks for Textual Logical Reasoning
Jul 04, 2022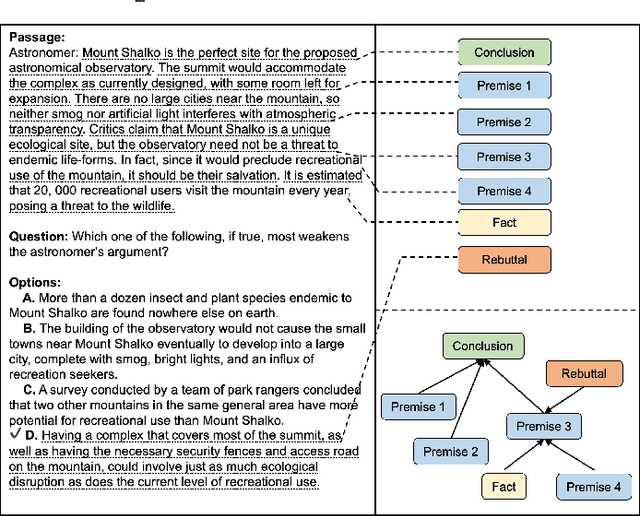
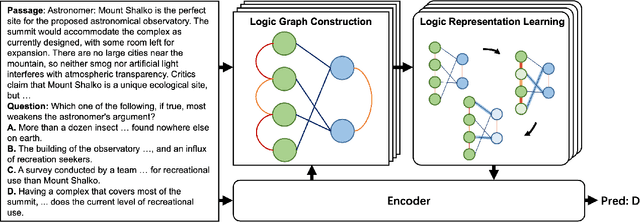
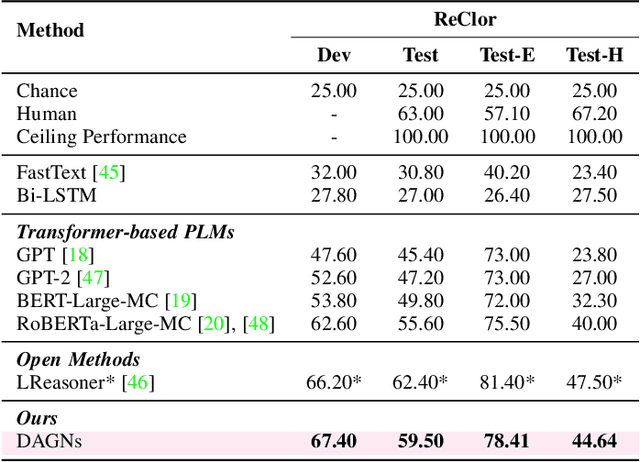
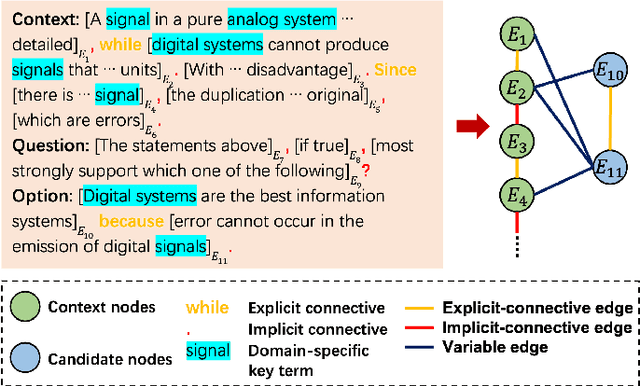
Textual logical reasoning, especially question answering (QA) tasks with logical reasoning, requires awareness of particular logical structures. The passage-level logical relations represent entailment or contradiction between propositional units (e.g., a concluding sentence). However, such structures are unexplored as current QA systems focus on entity-based relations. In this work, we propose logic structural-constraint modeling to solve the logical reasoning QA and introduce discourse-aware graph networks (DAGNs). The networks perform two procedures: (1) logic graph construction that leverages in-line discourse connectives as well as generic logic theories, (2) logic representation learning by graph networks that produces structural logic features. This pipeline is applied to a general encoder, whose fundamental features are joined with the high-level logic features for answer prediction. Experiments on three textual logical reasoning datasets demonstrate the reasonability of the logical structures built in DAGNs and the effectiveness of the learned logic features. Moreover, zero-shot transfer results show the features' generality to unseen logical texts.