 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToolSample: Dual Dynamic Sampling Methods with Curriculum Learning for RL-based Tool Learning
Sep 18, 2025While reinforcement learning (RL) is increasingly used for LLM-based tool learning, its efficiency is often hampered by an overabundance of simple samples that provide diminishing learning value as training progresses. Existing dynamic sampling techniques are ill-suited for the multi-task structure and fine-grained reward mechanisms inherent to tool learning. This paper introduces Dynamic Sampling with Curriculum Learning (DSCL), a framework specifically designed to address this challenge by targeting the unique characteristics of tool learning: its multiple interdependent sub-tasks and multi-valued reward functions. DSCL features two core components: Reward-Based Dynamic Sampling, which uses multi-dimensional reward statistics (mean and variance) to prioritize valuable data, and Task-Based Dynamic Curriculum Learning, which adaptively focuses training on less-mastered sub-tasks. Through extensive experiments, we demonstrate that DSCL significantly improves training efficiency and model performance over strong baselines, achieving a 3.29\% improvement on the BFCLv3 benchmark. Our method provides a tailored solution that effectively leverages the complex reward signals and sub-task dynamics within tool learning to achieve superior results.
GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
Aug 08, 2025We present GLM-4.5, an open-source Mixture-of-Experts (MoE) large language model with 355B total parameters and 32B activated parameters, featuring a hybrid reasoning method that supports both thinking and direct response modes. Through multi-stage training on 23T tokens and comprehensive post-training with expert model iteration and reinforcement learning, GLM-4.5 achieves strong performance across agentic, reasoning, and coding (ARC) tasks, scoring 70.1% on TAU-Bench, 91.0% on AIME 24, and 64.2% on SWE-bench Verified. With much fewer parameters than several competitors, GLM-4.5 ranks 3rd overall among all evaluated models and 2nd on agentic benchmarks. We release both GLM-4.5 (355B parameters) and a compact version, GLM-4.5-Air (106B parameters), to advance research in reasoning and agentic AI systems. Code, models, and more information are available at https://github.com/zai-org/GLM-4.5.
RAIDEN-R1: Improving Role-awareness of LLMs via GRPO with Verifiable Reward
May 15, 2025Role-playing conversational agents (RPCAs) face persistent challenges in maintaining role consistency. To address this, we propose RAIDEN-R1, a novel reinforcement learning framework that integrates Verifiable Role-Awareness Reward (VRAR). The method introduces both singular and multi-term mining strategies to generate quantifiable rewards by assessing role-specific keys. Additionally, we construct a high-quality, role-aware Chain-of-Thought dataset through multi-LLM collaboration, and implement experiments to enhance reasoning coherence. Experiments on the RAIDEN benchmark demonstrate RAIDEN-R1's superiority: our 14B-GRPO model achieves 88.04% and 88.65% accuracy on Script-Based Knowledge and Conversation Memory metrics, respectively, outperforming baseline models while maintaining robustness. Case analyses further reveal the model's enhanced ability to resolve conflicting contextual cues and sustain first-person narrative consistency. This work bridges the non-quantifiability gap in RPCA training and provides insights into role-aware reasoning patterns, advancing the development of RPCAs.
Improving Generalization in Intent Detection: GRPO with Reward-Based Curriculum Sampling
Apr 21, 2025Intent detection, a critical component in task-oriented dialogue (TOD) systems, faces significant challenges in adapting to the rapid influx of integrable tools with complex interrelationships. Existing approaches, such as zero-shot reformulations and LLM-based dynamic recognition, struggle with performance degradation when encountering unseen intents, leading to erroneous task routing. To enhance the model's generalization performance on unseen tasks, we employ Reinforcement Learning (RL) combined with a Reward-based Curriculum Sampling (RCS) during Group Relative Policy Optimization (GRPO) training in intent detection tasks. Experiments demonstrate that RL-trained models substantially outperform supervised fine-tuning (SFT) baselines in generalization. Besides, the introduction of the RCS, significantly bolsters the effectiveness of RL in intent detection by focusing the model on challenging cases during training. Moreover, incorporating Chain-of-Thought (COT) processes in RL notably improves generalization in complex intent detection tasks, underscoring the importance of thought in challenging scenarios. This work advances the generalization of intent detection tasks, offering practical insights for deploying adaptable dialogue systems.
F5R-TTS: Improving Flow Matching based Text-to-Speech with Group Relative Policy Optimization
Apr 03, 2025We present F5R-TTS, a novel text-to-speech (TTS) system that integrates Gradient Reward Policy Optimization (GRPO) into a flow-matching based architecture. By reformulating the deterministic outputs of flow-matching TTS into probabilistic Gaussian distributions, our approach enables seamless integration of reinforcement learning algorithms. During pretraining, we train a probabilistically reformulated flow-matching based model which is derived from F5-TTS with an open-source dataset. In the subsequent reinforcement learning (RL) phase, we employ a GRPO-driven enhancement stage that leverages dual reward metrics: word error rate (WER) computed via automatic speech recognition and speaker similarity (SIM) assessed by verification models. Experimental results on zero-shot voice cloning demonstrate that F5R-TTS achieves significant improvements in both speech intelligibility (relatively 29.5\% WER reduction) and speaker similarity (relatively 4.6\% SIM score increase) compared to conventional flow-matching based TTS systems. Audio samples are available at https://frontierlabs.github.io/F5R.
Interpersonal Memory Matters: A New Task for Proactive Dialogue Utilizing Conversational History
Mar 07, 2025Proactive dialogue systems aim to empower chatbots with the capability of leading conversations towards specific targets, thereby enhancing user engagement and service autonomy. Existing systems typically target pre-defined keywords or entities, neglecting user attributes and preferences implicit in dialogue history, hindering the development of long-term user intimacy. To address these challenges, we take a radical step towards building a more human-like conversational agent by integrating proactive dialogue systems with long-term memory into a unified framework. Specifically, we define a novel task named Memory-aware Proactive Dialogue (MapDia). By decomposing the task, we then propose an automatic data construction method and create the first Chinese Memory-aware Proactive Dataset (ChMapData). Furthermore, we introduce a joint framework based on Retrieval Augmented Generation (RAG), featuring three modules: Topic Summarization, Topic Retrieval, and Proactive Topic-shifting Detection and Generation, designed to steer dialogues towards relevant historical topics at the right time. The effectiveness of our dataset and models is validated through both automatic and human evaluations. We release the open-source framework and dataset at https://github.com/FrontierLabs/MapDia.
Image Comes Dancing with Collaborative Parsing-Flow Video Synthesis
Oct 28, 2021
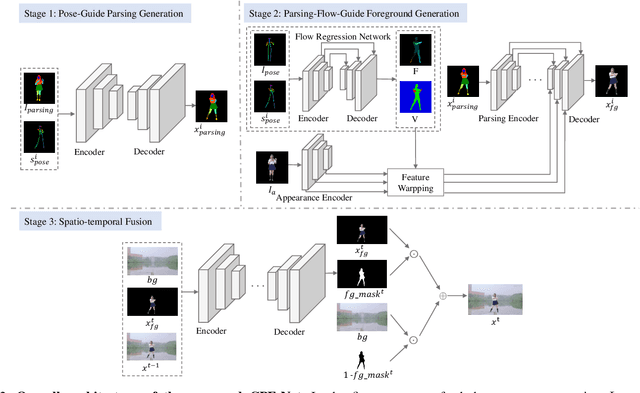


Transferring human motion from a source to a target person poses great potential in computer vision and graphics applications. A crucial step is to manipulate sequential future motion while retaining the appearance characteristic.Previous work has either relied on crafted 3D human models or trained a separate model specifically for each target person, which is not scalable in practice.This work studies a more general setting, in which we aim to learn a single model to parsimoniously transfer motion from a source video to any target person given only one image of the person, named as Collaborative Parsing-Flow Network (CPF-Net). The paucity of information regarding the target person makes the task particularly challenging to faithfully preserve the appearance in varying designated poses. To address this issue, CPF-Net integrates the structured human parsing and appearance flow to guide the realistic foreground synthesis which is merged into the background by a spatio-temporal fusion module. In particular, CPF-Net decouples the problem into stages of human parsing sequence generation, foreground sequence generation and final video generation. The human parsing generation stage captures both the pose and the body structure of the target. The appearance flow is beneficial to keep details in synthesized frames. The integration of human parsing and appearance flow effectively guides the generation of video frames with realistic appearance. Finally, the dedicated designed fusion network ensure the temporal coherence. We further collect a large set of human dancing videos to push forward this research field. Both quantitative and qualitative results show our method substantially improves over previous approaches and is able to generate appealing and photo-realistic target videos given any input person image. All source code and dataset will be released at https://github.com/xiezhy6/CPF-Net.
EagleEye: Fast Sub-net Evaluation for Efficient Neural Network Pruning
Jul 06, 2020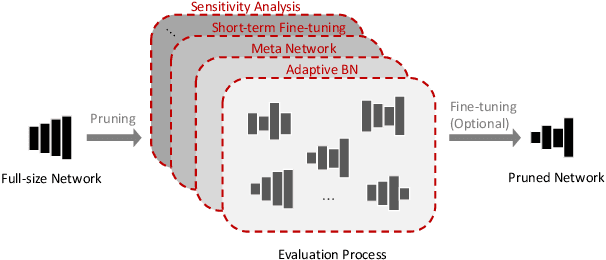
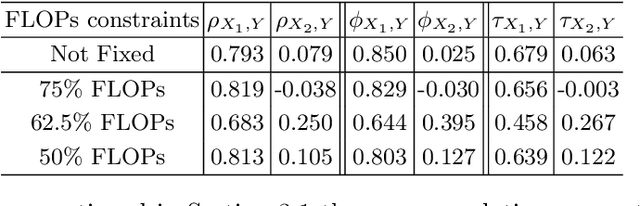
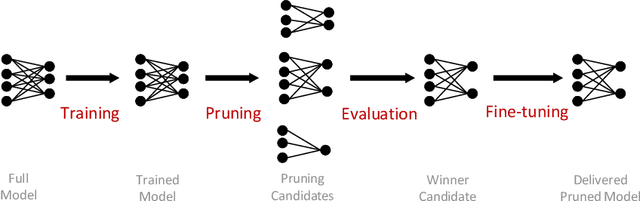
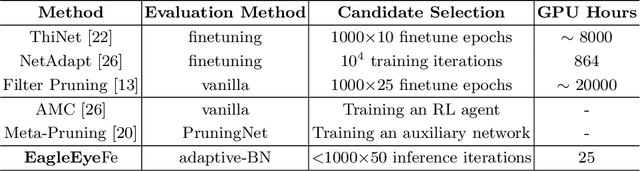
Finding out the computational redundant part of a trained Deep Neural Network (DNN) is the key question that pruning algorithms target on. Many algorithms try to predict model performance of the pruned sub-nets by introducing various evaluation methods. But they are either inaccurate or very complicated for general application. In this work, we present a pruning method called EagleEye, in which a simple yet efficient evaluation component based on adaptive batch normalization is applied to unveil a strong correlation between different pruned DNN structures and their final settled accuracy. This strong correlation allows us to fast spot the pruned candidates with highest potential accuracy without actually fine-tuning them. This module is also general to plug-in and improve some existing pruning algorithms. EagleEye achieves better pruning performance than all of the studied pruning algorithms in our experiments. Concretely, to prune MobileNet V1 and ResNet-50, EagleEye outperforms all compared methods by up to 3.8%. Even in the more challenging experiments of pruning the compact model of MobileNet V1, EagleEye achieves the highest accuracy of 70.9% with an overall 50% operations (FLOPs) pruned. All accuracy results are Top-1 ImageNet classification accuracy. Source code and models are accessible to open-source community https://github.com/anonymous47823493/EagleEye .
Towards Non-task-specific Distillation of BERT via Sentence Representation Approximation
Apr 07, 2020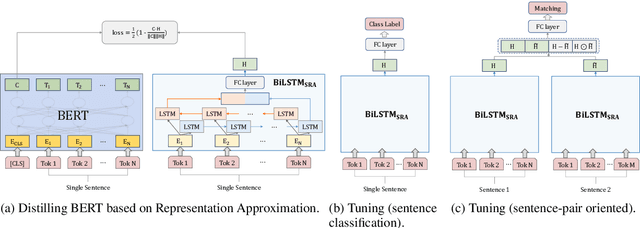
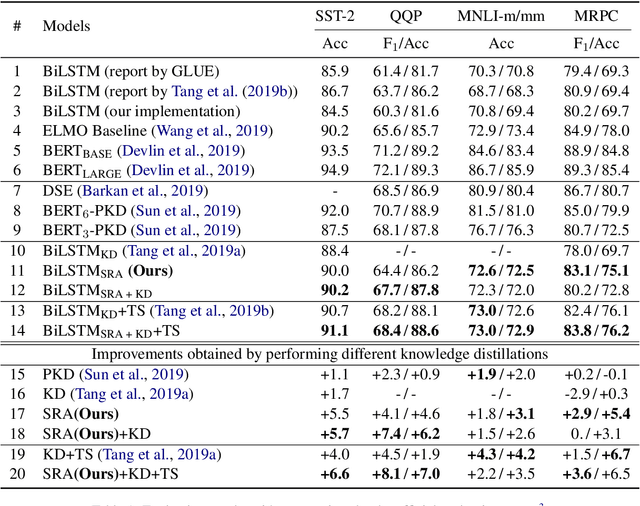
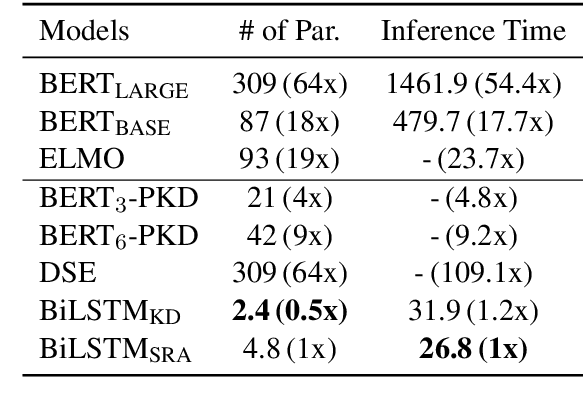
Recently, BERT has become an essential ingredient of various NLP deep models due to its effectiveness and universal-usability. However, the online deployment of BERT is often blocked by its large-scale parameters and high computational cost. There are plenty of studies showing that the knowledge distillation is efficient in transferring the knowledge from BERT into the model with a smaller size of parameters. Nevertheless, current BERT distillation approaches mainly focus on task-specified distillation, such methodologies lead to the loss of the general semantic knowledge of BERT for universal-usability. In this paper, we propose a sentence representation approximating oriented distillation framework that can distill the pre-trained BERT into a simple LSTM based model without specifying tasks. Consistent with BERT, our distilled model is able to perform transfer learning via fine-tuning to adapt to any sentence-level downstream task. Besides, our model can further cooperate with task-specific distillation procedures. The experimental results on multiple NLP tasks from the GLUE benchmark show that our approach outperforms other task-specific distillation methods or even much larger models, i.e., ELMO, with efficiency well-improved.
Guiding Variational Response Generator to Exploit Persona
Nov 06, 2019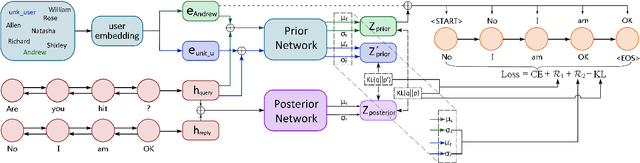
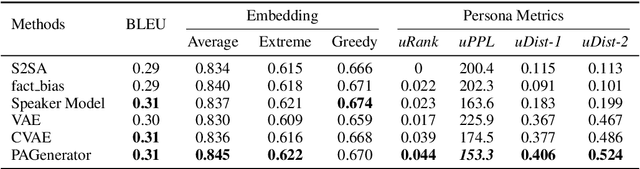
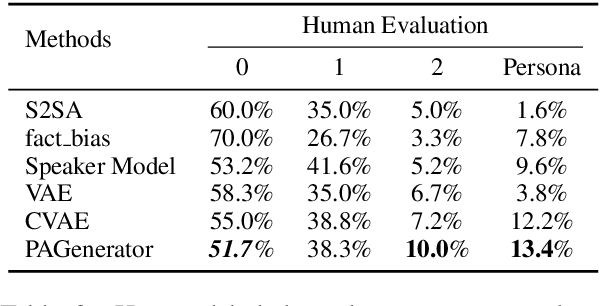

Leveraging persona information of users in Neural Response Generators (NRG) to perform personalized conversations has been considered as an attractive and important topic in the research of conversational agents over the past few years. Despite of the promising progresses achieved by recent studies in this field, persona information tends to be incorporated into neural networks in the form of user embeddings, with the expectation that the persona can be involved via the End-to-End learning. This paper proposes to adopt the personality-related characteristics of human conversations into variational response generators, by designing a specific conditional variational autoencoder based deep model with two new regularization terms employed to the loss function, so as to guide the optimization towards the direction of generating both persona-aware and relevant responses. Besides, to reasonably evaluate the performances of various persona modeling approaches, this paper further presents three direct persona-oriented metrics from different perspectives. The experimental results have shown that our proposed methodology can notably improve the performance of persona-aware response generation, and the metrics are reasonable to evaluate the results.