 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniColor: A Unified Framework for Multi-modal Lineart Colorization
Mar 29, 2026Lineart colorization is a critical stage in professional content creation, yet achieving precise and flexible results under diverse user constraints remains a significant challenge. To address this, we propose OmniColor, a unified framework for multi-modal lineart colorization that supports arbitrary combinations of control signals. Specifically, we systematically categorize guidance signals into two types: spatially-aligned conditions and semantic-reference conditions. For spatially-aligned inputs, we employ a dual-path encoding strategy paired with a Dense Feature Alignment loss to ensure rigorous boundary preservation and precise color restoration. For semantic-reference inputs, we utilize a VLM-only encoding scheme integrated with a Temporal Redundancy Elimination mechanism to filter repetitive information and enhance inference efficiency. To resolve potential input conflicts, we introduce an Adaptive Spatial-Semantic Gating module that dynamically balances multi-modal constraints. Experimental results demonstrate that OmniColor achieves superior controllability, visual quality, and temporal stability, providing a robust and practical solution for lineart colorization. The source code and dataset will be open at https://github.com/zhangxulu1996/OmniColor.
Mol-R1: Towards Explicit Long-CoT Reasoning in Molecule Discovery
Aug 11, 2025Large language models (LLMs), especially Explicit Long Chain-of-Thought (CoT) reasoning models like DeepSeek-R1 and QWQ, have demonstrated powerful reasoning capabilities, achieving impressive performance in commonsense reasoning and mathematical inference. Despite their effectiveness, Long-CoT reasoning models are often criticized for their limited ability and low efficiency in knowledge-intensive domains such as molecule discovery. Success in this field requires a precise understanding of domain knowledge, including molecular structures and chemical principles, which is challenging due to the inherent complexity of molecular data and the scarcity of high-quality expert annotations. To bridge this gap, we introduce Mol-R1, a novel framework designed to improve explainability and reasoning performance of R1-like Explicit Long-CoT reasoning LLMs in text-based molecule generation. Our approach begins with a high-quality reasoning dataset curated through Prior Regulation via In-context Distillation (PRID), a dedicated distillation strategy to effectively generate paired reasoning traces guided by prior regulations. Building upon this, we introduce MoIA, Molecular Iterative Adaptation, a sophisticated training strategy that iteratively combines Supervised Fine-tuning (SFT) with Reinforced Policy Optimization (RPO), tailored to boost the reasoning performance of R1-like reasoning models for molecule discovery. Finally, we examine the performance of Mol-R1 in the text-based molecule reasoning generation task, showing superior performance against existing baselines.
Removal of Hallucination on Hallucination: Debate-Augmented RAG
May 24, 2025Retrieval-Augmented Generation (RAG) enhances factual accuracy by integrating external knowledge, yet it introduces a critical issue: erroneous or biased retrieval can mislead generation, compounding hallucinations, a phenomenon we term Hallucination on Hallucination. To address this, we propose Debate-Augmented RAG (DRAG), a training-free framework that integrates Multi-Agent Debate (MAD) mechanisms into both retrieval and generation stages. In retrieval, DRAG employs structured debates among proponents, opponents, and judges to refine retrieval quality and ensure factual reliability. In generation, DRAG introduces asymmetric information roles and adversarial debates, enhancing reasoning robustness and mitigating factual inconsistencies. Evaluations across multiple tasks demonstrate that DRAG improves retrieval reliability, reduces RAG-induced hallucinations, and significantly enhances overall factual accuracy. Our code is available at https://github.com/Huenao/Debate-Augmented-RAG.
MolGround: A Benchmark for Molecular Grounding
Apr 01, 2025Current molecular understanding approaches predominantly focus on the descriptive aspect of human perception, providing broad, topic-level insights. However, the referential aspect -- linking molecular concepts to specific structural components -- remains largely unexplored. To address this gap, we propose a molecular grounding benchmark designed to evaluate a model's referential abilities. We align molecular grounding with established conventions in NLP, cheminformatics, and molecular science, showcasing the potential of NLP techniques to advance molecular understanding within the AI for Science movement. Furthermore, we constructed the largest molecular understanding benchmark to date, comprising 79k QA pairs, and developed a multi-agent grounding prototype as proof of concept. This system outperforms existing models, including GPT-4o, and its grounding outputs have been integrated to enhance traditional tasks such as molecular captioning and ATC (Anatomical, Therapeutic, Chemical) classification.
Prior Knowledge Integration via LLM Encoding and Pseudo Event Regulation for Video Moment Retrieval
Jul 23, 2024



In this paper, we investigate the feasibility of leveraging large language models (LLMs) for integrating general knowledge and incorporating pseudo-events as priors for temporal content distribution in video moment retrieval (VMR) models. The motivation behind this study arises from the limitations of using LLMs as decoders for generating discrete textual descriptions, which hinders their direct application to continuous outputs like salience scores and inter-frame embeddings that capture inter-frame relations. To overcome these limitations, we propose utilizing LLM encoders instead of decoders. Through a feasibility study, we demonstrate that LLM encoders effectively refine inter-concept relations in multimodal embeddings, even without being trained on textual embeddings. We also show that the refinement capability of LLM encoders can be transferred to other embeddings, such as BLIP and T5, as long as these embeddings exhibit similar inter-concept similarity patterns to CLIP embeddings. We present a general framework for integrating LLM encoders into existing VMR architectures, specifically within the fusion module. Through experimental validation, we demonstrate the effectiveness of our proposed methods by achieving state-of-the-art performance in VMR. The source code can be accessed at https://github.com/fletcherjiang/LLMEPET.
SE Territory: Monaural Speech Enhancement Meets the Fixed Virtual Perceptual Space Mapping
Nov 03, 2023



Monaural speech enhancement has achieved remarkable progress recently. However, its performance has been constrained by the limited spatial cues available at a single microphone. To overcome this limitation, we introduce a strategy to map monaural speech into a fixed simulation space for better differentiation between target speech and noise. Concretely, we propose SE-TerrNet, a novel monaural speech enhancement model featuring a virtual binaural speech mapping network via a two-stage multi-task learning framework. In the first stage, monaural noisy input is projected into a virtual space using supervised speech mapping blocks, creating binaural representations. These blocks synthesize binaural noisy speech from monaural input via an ideal binaural room impulse response. The synthesized output assigns speech and noise sources to fixed directions within the perceptual space. In the second stage, the obtained binaural features from the first stage are aggregated. This aggregation aims to decrease pattern discrepancies between the mapped binaural and original monaural features, achieved by implementing an intermediate fusion module. Furthermore, this stage incorporates the utilization of cross-attention to capture the injected virtual spatial information to improve the extraction of the target speech. Empirical studies highlight the effectiveness of virtual spatial cues in enhancing monaural speech enhancement. As a result, the proposed SE-TerrNet significantly surpasses the recent monaural speech enhancement methods in terms of both speech quality and intelligibility.
UniDiff: Advancing Vision-Language Models with Generative and Discriminative Learning
Jun 01, 2023Recent advances in vision-language pre-training have enabled machines to perform better in multimodal object discrimination (e.g., image-text semantic alignment) and image synthesis (e.g., text-to-image generation). On the other hand, fine-tuning pre-trained models with discriminative or generative capabilities such as CLIP and Stable Diffusion on domain-specific datasets has shown to be effective in various tasks by adapting to specific domains. However, few studies have explored the possibility of learning both discriminative and generative capabilities and leveraging their synergistic effects to create a powerful and personalized multimodal model during fine-tuning. This paper presents UniDiff, a unified multi-modal model that integrates image-text contrastive learning (ITC), text-conditioned image synthesis learning (IS), and reciprocal semantic consistency modeling (RSC). UniDiff effectively learns aligned semantics and mitigates the issue of semantic collapse during fine-tuning on small datasets by leveraging RSC on visual features from CLIP and diffusion models, without altering the pre-trained model's basic architecture. UniDiff demonstrates versatility in both multi-modal understanding and generative tasks. Experimental results on three datasets (Fashion-man, Fashion-woman, and E-commercial Product) showcase substantial enhancements in vision-language retrieval and text-to-image generation, illustrating the advantages of combining discriminative and generative fine-tuning. The proposed UniDiff model establishes a robust pipeline for personalized modeling and serves as a benchmark for future comparisons in the field.
Entity-Graph Enhanced Cross-Modal Pretraining for Instance-level Product Retrieval
Jun 17, 2022

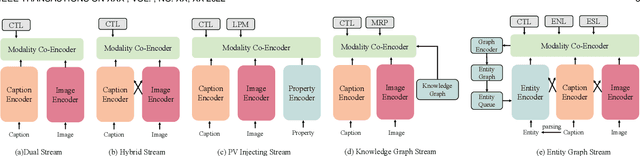

Our goal in this research is to study a more realistic environment in which we can conduct weakly-supervised multi-modal instance-level product retrieval for fine-grained product categories. We first contribute the Product1M datasets, and define two real practical instance-level retrieval tasks to enable the evaluations on the price comparison and personalized recommendations. For both instance-level tasks, how to accurately pinpoint the product target mentioned in the visual-linguistic data and effectively decrease the influence of irrelevant contents is quite challenging. To address this, we exploit to train a more effective cross-modal pertaining model which is adaptively capable of incorporating key concept information from the multi-modal data, by using an entity graph whose node and edge respectively denote the entity and the similarity relation between entities. Specifically, a novel Entity-Graph Enhanced Cross-Modal Pretraining (EGE-CMP) model is proposed for instance-level commodity retrieval, that explicitly injects entity knowledge in both node-based and subgraph-based ways into the multi-modal networks via a self-supervised hybrid-stream transformer, which could reduce the confusion between different object contents, thereby effectively guiding the network to focus on entities with real semantic. Experimental results well verify the efficacy and generalizability of our EGE-CMP, outperforming several SOTA cross-modal baselines like CLIP, UNITER and CAPTURE.
Indicative Image Retrieval: Turning Blackbox Learning into Grey
Jan 28, 2022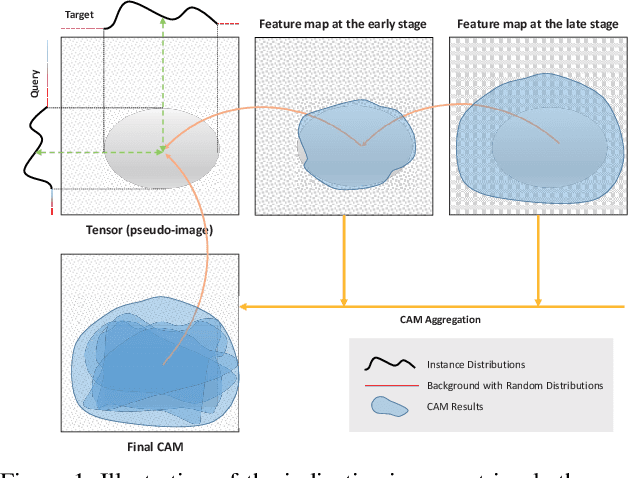



Deep learning became the game changer for image retrieval soon after it was introduced. It promotes the feature extraction (by representation learning) as the core of image retrieval, with the relevance/matching evaluation being degenerated into simple similarity metrics. In many applications, we need the matching evidence to be indicated rather than just have the ranked list (e.g., the locations of the target proteins/cells/lesions in medical images). It is like the matched words need to be highlighted in search engines. However, this is not easy to implement without explicit relevance/matching modeling. The deep representation learning models are not feasible because of their blackbox nature. In this paper, we revisit the importance of relevance/matching modeling in deep learning era with an indicative retrieval setting. The study shows that it is possible to skip the representation learning and model the matching evidence directly. By removing the dependency on the pre-trained models, it has avoided a lot of related issues (e.g., the domain gap between classification and retrieval, the detail-diffusion caused by convolution, and so on). More importantly, the study demonstrates that the matching can be explicitly modeled and backtracked later for generating the matching evidence indications. It can improve the explainability of deep inference. Our method obtains a best performance in literature on both Oxford-5k and Paris-6k, and sets a new record of 97.77% on Oxford-5k (97.81% on Paris-6k) without extracting any deep features.
Deep learning-based person re-identification methods: A survey and outlook of recent works
Oct 16, 2021
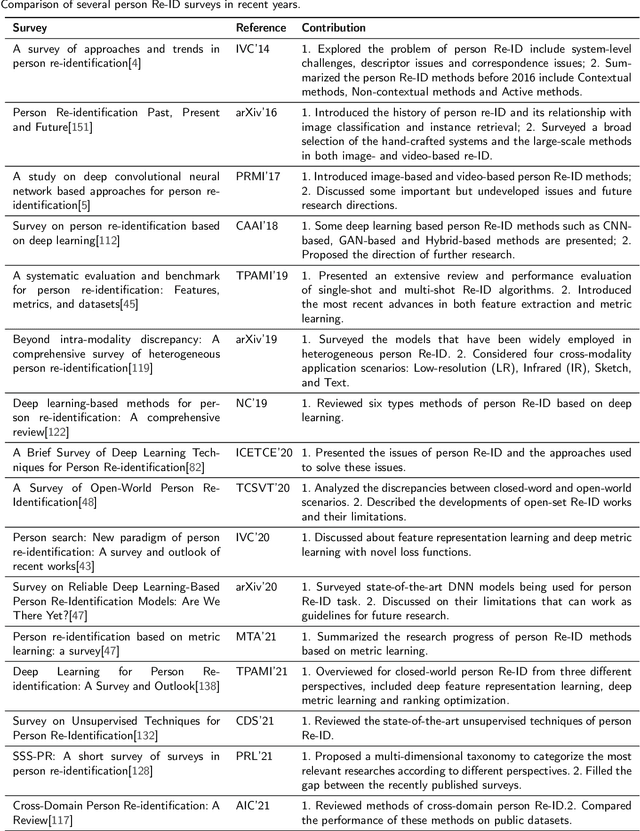
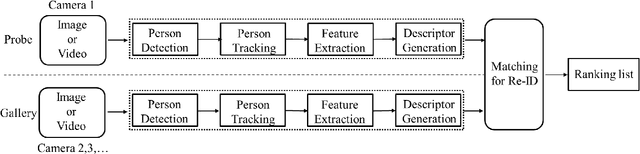

In recent years, with the increasing demand for public safety and the rapid development of intelligent surveillance networks, person re-identification (Re-ID) has become one of the hot research topics in the field of computer vision. The main research goal of person Re-ID is to retrieve persons with the same identity from different cameras. However, traditional person Re-ID methods require manual marking of person targets, which consumes a lot of labor cost. With the widespread application of deep neural networks in the field of computer vision, a large number of deep learning-based person Re-ID methods have emerged. Therefore, this paper is to facilitate researchers to better understand the latest research results and the future trends in the field. Firstly, we summarize the main study of several recently published person re-identification surveys and try to fill the gaps between them. Secondly, We propose a multi-dimensional taxonomy to categorize the most current deep learning-based person Re-ID methods according to different characteristics, including methods for deep metric learning, local feature learning, generate adversarial networks, sequence feature learning and graph convolutional networks. Furthermore, we subdivide the above five categories according to their technique types, discussing and comparing the experimental performance of part subcategories. Finally, we conclude this paper and discuss future research directions for person Re-ID.