 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Long-Horizon Task Mirage? Diagnosing Where and Why Agentic Systems Break
Apr 13, 2026Large language model (LLM) agents perform strongly on short- and mid-horizon tasks, but often break down on long-horizon tasks that require extended, interdependent action sequences. Despite rapid progress in agentic systems, these long-horizon failures remain poorly characterized, hindering principled diagnosis and comparison across domains. To address this gap, we introduce HORIZON, an initial cross-domain diagnostic benchmark for systematically constructing tasks and analyzing long-horizon failure behaviors in LLM-based agents. Using HORIZON, we evaluate state-of-the-art (SOTA) agents from multiple model families (GPT-5 variants and Claude models), collecting 3100+ trajectories across four representative agentic domains to study horizon-dependent degradation patterns. We further propose a trajectory-grounded LLM-as-a-Judge pipeline for scalable and reproducible failure attribution, and validate it with human annotation on trajectories, achieving strong agreement (inter-annotator κ=0.61; human-judge κ=0.84). Our findings offer an initial methodological step toward systematic, cross-domain analysis of long-horizon agent failures and offer practical guidance for building more reliable long-horizon agents. We release our project website at \href{https://xwang2775.github.io/horizon-leaderboard/}{HORIZON Leaderboard} and welcome contributions from the community.
Expert-Choice Routing Enables Adaptive Computation in Diffusion Language Models
Apr 02, 2026Diffusion language models (DLMs) enable parallel, non-autoregressive text generation, yet existing DLM mixture-of-experts (MoE) models inherit token-choice (TC) routing from autoregressive systems, leading to load imbalance and rigid computation allocation. We show that expert-choice (EC) routing is a better fit for DLMs: it provides deterministic load balancing by design, yielding higher throughput and faster convergence than TC. Building on the property that EC capacity is externally controllable, we introduce timestep-dependent expert capacity, which varies expert allocation according to the denoising step. We find that allocating more capacity to low-mask-ratio steps consistently achieves the best performance under matched FLOPs, and provide a mechanistic explanation: tokens in low-mask-ratio contexts exhibit an order-of-magnitude higher learning efficiency, so concentrating compute on these steps yields the largest marginal return. Finally, we show that existing pretrained TC DLMs can be retrofitted to EC by replacing only the router, achieving faster convergence and improved accuracy across diverse downstream tasks. Together, these results establish EC routing as a superior paradigm for DLM MoE models and demonstrate that computation in DLMs can be treated as an adaptive policy rather than a fixed architectural constant. Code is available at https://github.com/zhangshuibai/EC-DLM.
Unknown Aware AI-Generated Content Attribution
Jan 01, 2026The rapid advancement of photorealistic generative models has made it increasingly important to attribute the origin of synthetic content, moving beyond binary real or fake detection toward identifying the specific model that produced a given image. We study the problem of distinguishing outputs from a target generative model (e.g., OpenAI Dalle 3) from other sources, including real images and images generated by a wide range of alternative models. Using CLIP features and a simple linear classifier, shown to be effective in prior work, we establish a strong baseline for target generator attribution using only limited labeled data from the target model and a small number of known generators. However, this baseline struggles to generalize to harder, unseen, and newly released generators. To address this limitation, we propose a constrained optimization approach that leverages unlabeled wild data, consisting of images collected from the Internet that may include real images, outputs from unknown generators, or even samples from the target model itself. The proposed method encourages wild samples to be classified as non target while explicitly constraining performance on labeled data to remain high. Experimental results show that incorporating wild data substantially improves attribution performance on challenging unseen generators, demonstrating that unlabeled data from the wild can be effectively exploited to enhance AI generated content attribution in open world settings.
How and Why LLMs Generalize: A Fine-Grained Analysis of LLM Reasoning from Cognitive Behaviors to Low-Level Patterns
Dec 30, 2025Large Language Models (LLMs) display strikingly different generalization behaviors: supervised fine-tuning (SFT) often narrows capability, whereas reinforcement-learning (RL) tuning tends to preserve it. The reasons behind this divergence remain unclear, as prior studies have largely relied on coarse accuracy metrics. We address this gap by introducing a novel benchmark that decomposes reasoning into atomic core skills such as calculation, fact retrieval, simulation, enumeration, and diagnostic, providing a concrete framework for addressing the fundamental question of what constitutes reasoning in LLMs. By isolating and measuring these core skills, the benchmark offers a more granular view of how specific cognitive abilities emerge, transfer, and sometimes collapse during post-training. Combined with analyses of low-level statistical patterns such as distributional divergence and parameter statistics, it enables a fine-grained study of how generalization evolves under SFT and RL across mathematical, scientific reasoning, and non-reasoning tasks. Our meta-probing framework tracks model behavior at different training stages and reveals that RL-tuned models maintain more stable behavioral profiles and resist collapse in reasoning skills, whereas SFT models exhibit sharper drift and overfit to surface patterns. This work provides new insights into the nature of reasoning in LLMs and points toward principles for designing training strategies that foster broad, robust generalization.
Mitigating Recommendation Biases via Group-Alignment and Global-Uniformity in Representation Learning
Nov 17, 2025Collaborative Filtering~(CF) plays a crucial role in modern recommender systems, leveraging historical user-item interactions to provide personalized suggestions. However, CF-based methods often encounter biases due to imbalances in training data. This phenomenon makes CF-based methods tend to prioritize recommending popular items and performing unsatisfactorily on inactive users. Existing works address this issue by rebalancing training samples, reranking recommendation results, or making the modeling process robust to the bias. Despite their effectiveness, these approaches can compromise accuracy or be sensitive to weighting strategies, making them challenging to train. In this paper, we deeply analyze the causes and effects of the biases and propose a framework to alleviate biases in recommendation from the perspective of representation distribution, namely Group-Alignment and Global-Uniformity Enhanced Representation Learning for Debiasing Recommendation (AURL). Specifically, we identify two significant problems in the representation distribution of users and items, namely group-discrepancy and global-collapse. These two problems directly lead to biases in the recommendation results. To this end, we propose two simple but effective regularizers in the representation space, respectively named group-alignment and global-uniformity. The goal of group-alignment is to bring the representation distribution of long-tail entities closer to that of popular entities, while global-uniformity aims to preserve the information of entities as much as possible by evenly distributing representations. Our method directly optimizes both the group-alignment and global-uniformity regularization terms to mitigate recommendation biases. Extensive experiments on three real datasets and various recommendation backbones verify the superiority of our proposed framework.
Understanding Embedding Scaling in Collaborative Filtering
Sep 19, 2025



Scaling recommendation models into large recommendation models has become one of the most widely discussed topics. Recent efforts focus on components beyond the scaling embedding dimension, as it is believed that scaling embedding may lead to performance degradation. Although there have been some initial observations on embedding, the root cause of their non-scalability remains unclear. Moreover, whether performance degradation occurs across different types of models and datasets is still an unexplored area. Regarding the effect of embedding dimensions on performance, we conduct large-scale experiments across 10 datasets with varying sparsity levels and scales, using 4 representative classical architectures. We surprisingly observe two novel phenomenon: double-peak and logarithmic. For the former, as the embedding dimension increases, performance first improves, then declines, rises again, and eventually drops. For the latter, it exhibits a perfect logarithmic curve. Our contributions are threefold. First, we discover two novel phenomena when scaling collaborative filtering models. Second, we gain an understanding of the underlying causes of the double-peak phenomenon. Lastly, we theoretically analyze the noise robustness of collaborative filtering models, with results matching empirical observations.
Data-Efficient Symbolic Regression via Foundation Model Distillation
Aug 27, 2025Discovering interpretable mathematical equations from observed data (a.k.a. equation discovery or symbolic regression) is a cornerstone of scientific discovery, enabling transparent modeling of physical, biological, and economic systems. While foundation models pre-trained on large-scale equation datasets offer a promising starting point, they often suffer from negative transfer and poor generalization when applied to small, domain-specific datasets. In this paper, we introduce EQUATE (Equation Generation via QUality-Aligned Transfer Embeddings), a data-efficient fine-tuning framework that adapts foundation models for symbolic equation discovery in low-data regimes via distillation. EQUATE combines symbolic-numeric alignment with evaluator-guided embedding optimization, enabling a principled embedding-search-generation paradigm. Our approach reformulates discrete equation search as a continuous optimization task in a shared embedding space, guided by data-equation fitness and simplicity. Experiments across three standard public benchmarks (Feynman, Strogatz, and black-box datasets) demonstrate that EQUATE consistently outperforms state-of-the-art baselines in both accuracy and robustness, while preserving low complexity and fast inference. These results highlight EQUATE as a practical and generalizable solution for data-efficient symbolic regression in foundation model distillation settings.
Supply Chain Optimization via Generative Simulation and Iterative Decision Policies
Jul 10, 2025High responsiveness and economic efficiency are critical objectives in supply chain transportation, both of which are influenced by strategic decisions on shipping mode. An integrated framework combining an efficient simulator with an intelligent decision-making algorithm can provide an observable, low-risk environment for transportation strategy design. An ideal simulation-decision framework must (1) generalize effectively across various settings, (2) reflect fine-grained transportation dynamics, (3) integrate historical experience with predictive insights, and (4) maintain tight integration between simulation feedback and policy refinement. We propose Sim-to-Dec framework to satisfy these requirements. Specifically, Sim-to-Dec consists of a generative simulation module, which leverages autoregressive modeling to simulate continuous state changes, reducing dependence on handcrafted domain-specific rules and enhancing robustness against data fluctuations; and a history-future dual-aware decision model, refined iteratively through end-to-end optimization with simulator interactions. Extensive experiments conducted on three real-world datasets demonstrate that Sim-to-Dec significantly improves timely delivery rates and profit.
Efficient Post-Training Refinement of Latent Reasoning in Large Language Models
Jun 10, 2025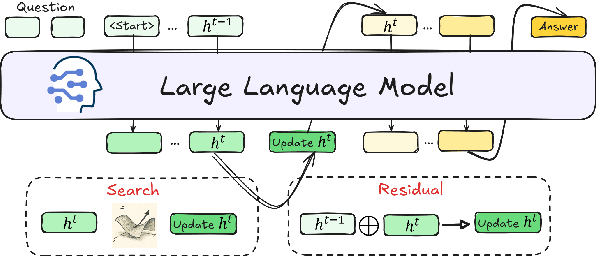
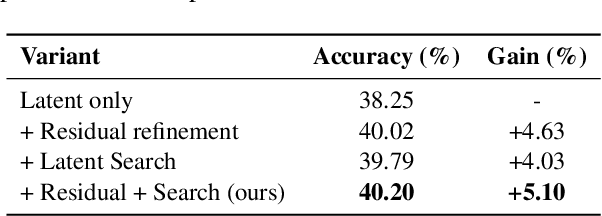
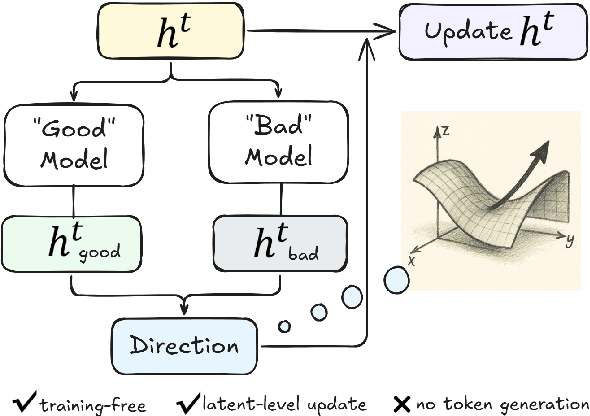
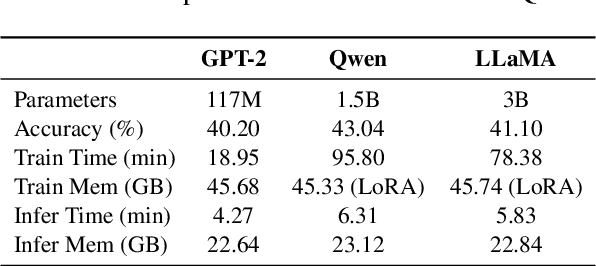
Reasoning is a key component of language understanding in Large Language Models. While Chain-of-Thought prompting enhances performance via explicit intermediate steps, it suffers from sufficient token overhead and a fixed reasoning trajectory, preventing step-wise refinement. Recent advances in latent reasoning address these limitations by refining internal reasoning processes directly in the model's latent space, without producing explicit outputs. However, a key challenge remains: how to effectively update reasoning embeddings during post-training to guide the model toward more accurate solutions. To overcome this challenge, we propose a lightweight post-training framework that refines latent reasoning trajectories using two novel strategies: 1) Contrastive reasoning feedback, which compares reasoning embeddings against strong and weak baselines to infer effective update directions via embedding enhancement; 2) Residual embedding refinement, which stabilizes updates by progressively integrating current and historical gradients, enabling fast yet controlled convergence. Extensive experiments and case studies are conducted on five reasoning benchmarks to demonstrate the effectiveness of the proposed framework. Notably, a 5\% accuracy gain on MathQA without additional training.
LLM-ML Teaming: Integrated Symbolic Decoding and Gradient Search for Valid and Stable Generative Feature Transformation
Jun 10, 2025
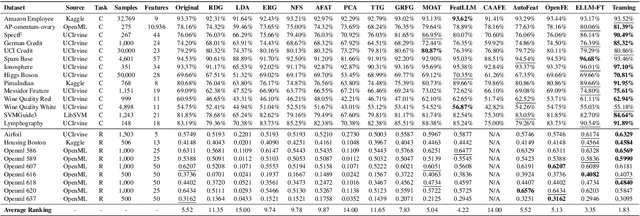
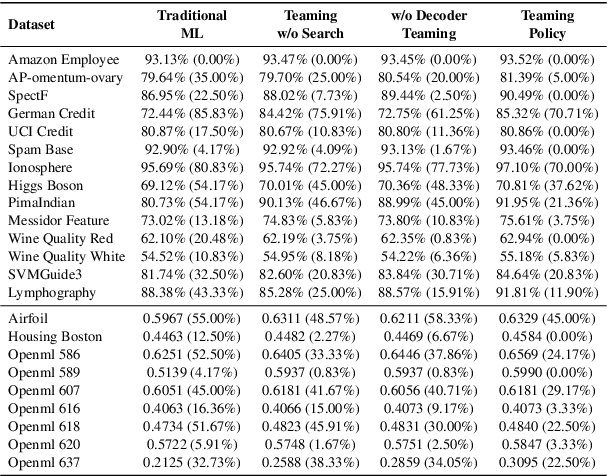
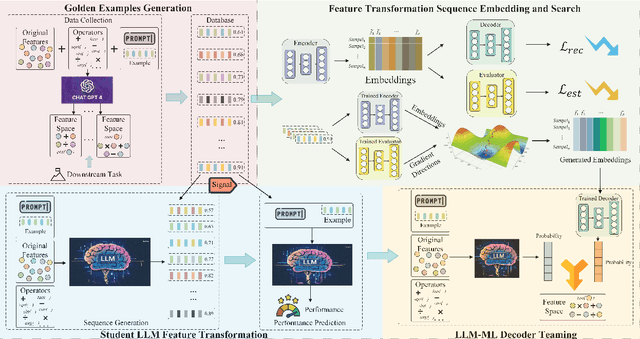
Feature transformation enhances data representation by deriving new features from the original data. Generative AI offers potential for this task, but faces challenges in stable generation (consistent outputs) and valid generation (error-free sequences). Existing methods--traditional MLs' low validity and LLMs' instability--fail to resolve both. We find that LLMs ensure valid syntax, while ML's gradient-steered search stabilizes performance. To bridge this gap, we propose a teaming framework combining LLMs' symbolic generation with ML's gradient optimization. This framework includes four steps: (1) golden examples generation, aiming to prepare high-quality samples with the ground knowledge of the teacher LLM; (2) feature transformation sequence embedding and search, intending to uncover potentially superior embeddings within the latent space; (3) student LLM feature transformation, aiming to distill knowledge from the teacher LLM; (4) LLM-ML decoder teaming, dedicating to combine ML and the student LLM probabilities for valid and stable generation. The experiments on various datasets show that the teaming policy can achieve 5\% improvement in downstream performance while reducing nearly half of the error cases. The results also demonstrate the efficiency and robustness of the teaming policy. Additionally, we also have exciting findings on LLMs' capacity to understand the original data.