 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSolving Inequality Proofs with Large Language Models
Jun 09, 2025Inequality proving, crucial across diverse scientific and mathematical fields, tests advanced reasoning skills such as discovering tight bounds and strategic theorem application. This makes it a distinct, demanding frontier for large language models (LLMs), offering insights beyond general mathematical problem-solving. Progress in this area is hampered by existing datasets that are often scarce, synthetic, or rigidly formal. We address this by proposing an informal yet verifiable task formulation, recasting inequality proving into two automatically checkable subtasks: bound estimation and relation prediction. Building on this, we release IneqMath, an expert-curated dataset of Olympiad-level inequalities, including a test set and training corpus enriched with step-wise solutions and theorem annotations. We also develop a novel LLM-as-judge evaluation framework, combining a final-answer judge with four step-wise judges designed to detect common reasoning flaws. A systematic evaluation of 29 leading LLMs on IneqMath reveals a surprising reality: even top models like o1 achieve less than 10% overall accuracy under step-wise scrutiny; this is a drop of up to 65.5% from their accuracy considering only final answer equivalence. This discrepancy exposes fragile deductive chains and a critical gap for current LLMs between merely finding an answer and constructing a rigorous proof. Scaling model size and increasing test-time computation yield limited gains in overall proof correctness. Instead, our findings highlight promising research directions such as theorem-guided reasoning and self-refinement. Code and data are available at https://ineqmath.github.io/.
MathVista: Evaluating Mathematical Reasoning of Foundation Models in Visual Contexts
Oct 03, 2023Although Large Language Models (LLMs) and Large Multimodal Models (LMMs) exhibit impressive skills in various domains, their ability for mathematical reasoning within visual contexts has not been formally examined. Equipping LLMs and LMMs with this capability is vital for general-purpose AI assistants and showcases promising potential in education, data analysis, and scientific discovery. To bridge this gap, we present MathVista, a benchmark designed to amalgamate challenges from diverse mathematical and visual tasks. We first taxonomize the key task types, reasoning skills, and visual contexts from the literature to guide our selection from 28 existing math-focused and visual question answering datasets. Then, we construct three new datasets, IQTest, FunctionQA, and PaperQA, to accommodate for missing types of visual contexts. The problems featured often require deep visual understanding beyond OCR or image captioning, and compositional reasoning with rich domain-specific tools, thus posing a notable challenge to existing models. We conduct a comprehensive evaluation of 11 prominent open-source and proprietary foundation models (LLMs, LLMs augmented with tools, and LMMs), and early experiments with GPT-4V. The best-performing model, Multimodal Bard, achieves only 58% of human performance (34.8% vs 60.3%), indicating ample room for further improvement. Given this significant gap, MathVista fuels future research in the development of general-purpose AI agents capable of tackling mathematically intensive and visually rich real-world tasks. Preliminary tests show that MathVista also presents challenges to GPT-4V, underscoring the benchmark's importance. The project is available at https://mathvista.github.io/.
TheoremQA: A Theorem-driven Question Answering dataset
May 23, 2023The recent LLMs like GPT-4 and PaLM-2 have made tremendous progress in solving fundamental math problems like GSM8K by achieving over 90% accuracy. However, their capabilities to solve more challenging math problems which require domain-specific knowledge (i.e. theorem) have yet to be investigated. In this paper, we introduce TheoremQA, the first theorem-driven question-answering dataset designed to evaluate AI models' capabilities to apply theorems to solve challenging science problems. TheoremQA is curated by domain experts containing 800 high-quality questions covering 350 theorems (e.g. Taylor's theorem, Lagrange's theorem, Huffman coding, Quantum Theorem, Elasticity Theorem, etc) from Math, Physics, EE&CS, and Finance. We evaluate a wide spectrum of 16 large language and code models with different prompting strategies like Chain-of-Thoughts and Program-of-Thoughts. We found that GPT-4's capabilities to solve these problems are unparalleled, achieving an accuracy of 51% with Program-of-Thoughts Prompting. All the existing open-sourced models are below 15%, barely surpassing the random-guess baseline. Given the diversity and broad coverage of TheoremQA, we believe it can be used as a better benchmark to evaluate LLMs' capabilities to solve challenging science problems. The data and code are released in https://github.com/wenhuchen/TheoremQA.
Learn to Explain: Multimodal Reasoning via Thought Chains for Science Question Answering
Sep 20, 2022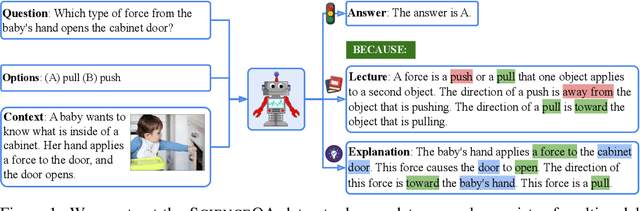
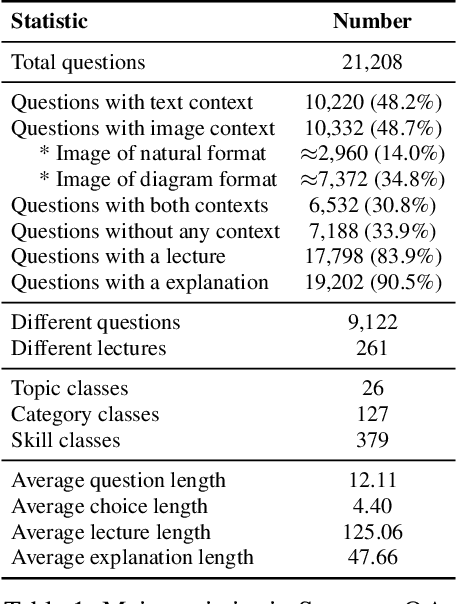
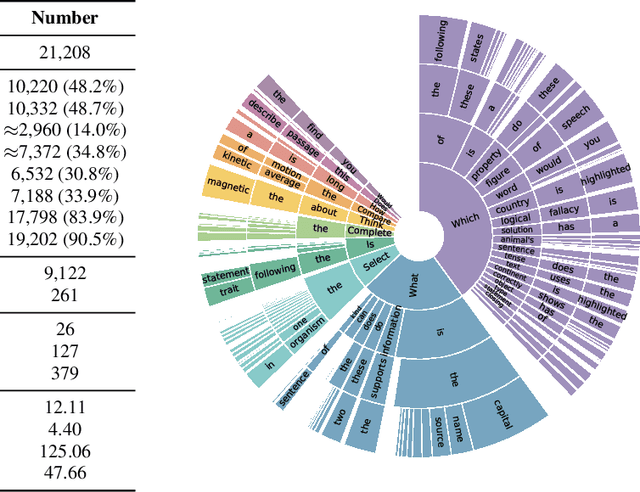
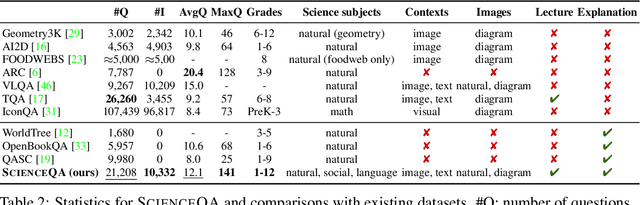
When answering a question, humans utilize the information available across different modalities to synthesize a consistent and complete chain of thought (CoT). This process is normally a black box in the case of deep learning models like large-scale language models. Recently, science question benchmarks have been used to diagnose the multi-hop reasoning ability and interpretability of an AI system. However, existing datasets fail to provide annotations for the answers, or are restricted to the textual-only modality, small scales, and limited domain diversity. To this end, we present Science Question Answering (SQA), a new benchmark that consists of ~21k multimodal multiple choice questions with a diverse set of science topics and annotations of their answers with corresponding lectures and explanations. We further design language models to learn to generate lectures and explanations as the chain of thought (CoT) to mimic the multi-hop reasoning process when answering SQA questions. SQA demonstrates the utility of CoT in language models, as CoT improves the question answering performance by 1.20% in few-shot GPT-3 and 3.99% in fine-tuned UnifiedQA. We also explore the upper bound for models to leverage explanations by feeding those in the input; we observe that it improves the few-shot performance of GPT-3 by 18.96%. Our analysis further shows that language models, similar to humans, benefit from explanations to learn from fewer data and achieve the same performance with just 40% of the data.
IconQA: A New Benchmark for Abstract Diagram Understanding and Visual Language Reasoning
Nov 07, 2021
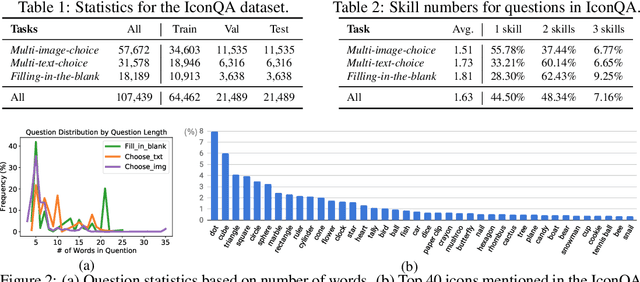

Current visual question answering (VQA) tasks mainly consider answering human-annotated questions for natural images. However, aside from natural images, abstract diagrams with semantic richness are still understudied in visual understanding and reasoning research. In this work, we introduce a new challenge of Icon Question Answering (IconQA) with the goal of answering a question in an icon image context. We release IconQA, a large-scale dataset that consists of 107,439 questions and three sub-tasks: multi-image-choice, multi-text-choice, and filling-in-the-blank. The IconQA dataset is inspired by real-world diagram word problems that highlight the importance of abstract diagram understanding and comprehensive cognitive reasoning. Thus, IconQA requires not only perception skills like object recognition and text understanding, but also diverse cognitive reasoning skills, such as geometric reasoning, commonsense reasoning, and arithmetic reasoning. To facilitate potential IconQA models to learn semantic representations for icon images, we further release an icon dataset Icon645 which contains 645,687 colored icons on 377 classes. We conduct extensive user studies and blind experiments and reproduce a wide range of advanced VQA methods to benchmark the IconQA task. Also, we develop a strong IconQA baseline Patch-TRM that applies a pyramid cross-modal Transformer with input diagram embeddings pre-trained on the icon dataset. IconQA and Icon645 are available at https://iconqa.github.io.