 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoRP: Bootstrapped Regression Probing for Scalable and Human-Aligned LLM Evaluation
Jan 26, 2026Accurate evaluation of user satisfaction is critical for iterative development of conversational AI. However, for open-ended assistants, traditional A/B testing lacks reliable metrics: explicit feedback is sparse, while implicit metrics are ambiguous. To bridge this gap, we introduce BoRP (Bootstrapped Regression Probing), a scalable framework for high-fidelity satisfaction evaluation. Unlike generative approaches, BoRP leverages the geometric properties of LLM latent space. It employs a polarization-index-based bootstrapping mechanism to automate rubric generation and utilizes Partial Least Squares (PLS) to map hidden states to continuous scores. Experiments on industrial datasets show that BoRP (Qwen3-8B/14B) significantly outperforms generative baselines (even Qwen3-Max) in alignment with human judgments. Furthermore, BoRP reduces inference costs by orders of magnitude, enabling full-scale monitoring and highly sensitive A/B testing via CUPED.
STEP3-VL-10B Technical Report
Jan 15, 2026We present STEP3-VL-10B, a lightweight open-source foundation model designed to redefine the trade-off between compact efficiency and frontier-level multimodal intelligence. STEP3-VL-10B is realized through two strategic shifts: first, a unified, fully unfrozen pre-training strategy on 1.2T multimodal tokens that integrates a language-aligned Perception Encoder with a Qwen3-8B decoder to establish intrinsic vision-language synergy; and second, a scaled post-training pipeline featuring over 1k iterations of reinforcement learning. Crucially, we implement Parallel Coordinated Reasoning (PaCoRe) to scale test-time compute, allocating resources to scalable perceptual reasoning that explores and synthesizes diverse visual hypotheses. Consequently, despite its compact 10B footprint, STEP3-VL-10B rivals or surpasses models 10$\times$-20$\times$ larger (e.g., GLM-4.6V-106B, Qwen3-VL-235B) and top-tier proprietary flagships like Gemini 2.5 Pro and Seed-1.5-VL. Delivering best-in-class performance, it records 92.2% on MMBench and 80.11% on MMMU, while excelling in complex reasoning with 94.43% on AIME2025 and 75.95% on MathVision. We release the full model suite to provide the community with a powerful, efficient, and reproducible baseline.
PaCoRe: Learning to Scale Test-Time Compute with Parallel Coordinated Reasoning
Jan 09, 2026We introduce Parallel Coordinated Reasoning (PaCoRe), a training-and-inference framework designed to overcome a central limitation of contemporary language models: their inability to scale test-time compute (TTC) far beyond sequential reasoning under a fixed context window. PaCoRe departs from the traditional sequential paradigm by driving TTC through massive parallel exploration coordinated via a message-passing architecture in multiple rounds. Each round launches many parallel reasoning trajectories, compacts their findings into context-bounded messages, and synthesizes these messages to guide the next round and ultimately produce the final answer. Trained end-to-end with large-scale, outcome-based reinforcement learning, the model masters the synthesis abilities required by PaCoRe and scales to multi-million-token effective TTC without exceeding context limits. The approach yields strong improvements across diverse domains, and notably pushes reasoning beyond frontier systems in mathematics: an 8B model reaches 94.5% on HMMT 2025, surpassing GPT-5's 93.2% by scaling effective TTC to roughly two million tokens. We open-source model checkpoints, training data, and the full inference pipeline to accelerate follow-up work.
DepFlow: Disentangled Speech Generation to Mitigate Semantic Bias in Depression Detection
Jan 01, 2026Speech is a scalable and non-invasive biomarker for early mental health screening. However, widely used depression datasets like DAIC-WOZ exhibit strong coupling between linguistic sentiment and diagnostic labels, encouraging models to learn semantic shortcuts. As a result, model robustness may be compromised in real-world scenarios, such as Camouflaged Depression, where individuals maintain socially positive or neutral language despite underlying depressive states. To mitigate this semantic bias, we propose DepFlow, a three-stage depression-conditioned text-to-speech framework. First, a Depression Acoustic Encoder learns speaker- and content-invariant depression embeddings through adversarial training, achieving effective disentanglement while preserving depression discriminability (ROC-AUC: 0.693). Second, a flow-matching TTS model with FiLM modulation injects these embeddings into synthesis, enabling control over depressive severity while preserving content and speaker identity. Third, a prototype-based severity mapping mechanism provides smooth and interpretable manipulation across the depression continuum. Using DepFlow, we construct a Camouflage Depression-oriented Augmentation (CDoA) dataset that pairs depressed acoustic patterns with positive/neutral content from a sentiment-stratified text bank, creating acoustic-semantic mismatches underrepresented in natural data. Evaluated across three depression detection architectures, CDoA improves macro-F1 by 9%, 12%, and 5%, respectively, consistently outperforming conventional augmentation strategies in depression Detection. Beyond enhancing robustness, DepFlow provides a controllable synthesis platform for conversational systems and simulation-based evaluation, where real clinical data remains limited by ethical and coverage constraints.
Step-DeepResearch Technical Report
Dec 24, 2025As LLMs shift toward autonomous agents, Deep Research has emerged as a pivotal metric. However, existing academic benchmarks like BrowseComp often fail to meet real-world demands for open-ended research, which requires robust skills in intent recognition, long-horizon decision-making, and cross-source verification. To address this, we introduce Step-DeepResearch, a cost-effective, end-to-end agent. We propose a Data Synthesis Strategy Based on Atomic Capabilities to reinforce planning and report writing, combined with a progressive training path from agentic mid-training to SFT and RL. Enhanced by a Checklist-style Judger, this approach significantly improves robustness. Furthermore, to bridge the evaluation gap in the Chinese domain, we establish ADR-Bench for realistic deep research scenarios. Experimental results show that Step-DeepResearch (32B) scores 61.4% on Scale AI Research Rubrics. On ADR-Bench, it significantly outperforms comparable models and rivals SOTA closed-source models like OpenAI and Gemini DeepResearch. These findings prove that refined training enables medium-sized models to achieve expert-level capabilities at industry-leading cost-efficiency.
Step-GUI Technical Report
Dec 19, 2025



Recent advances in multimodal large language models unlock unprecedented opportunities for GUI automation. However, a fundamental challenge remains: how to efficiently acquire high-quality training data while maintaining annotation reliability? We introduce a self-evolving training pipeline powered by the Calibrated Step Reward System, which converts model-generated trajectories into reliable training signals through trajectory-level calibration, achieving >90% annotation accuracy with 10-100x lower cost. Leveraging this pipeline, we introduce Step-GUI, a family of models (4B/8B) that achieves state-of-the-art GUI performance (8B: 80.2% AndroidWorld, 48.5% OSWorld, 62.6% ScreenShot-Pro) while maintaining robust general capabilities. As GUI agent capabilities improve, practical deployment demands standardized interfaces across heterogeneous devices while protecting user privacy. To this end, we propose GUI-MCP, the first Model Context Protocol for GUI automation with hierarchical architecture that combines low-level atomic operations and high-level task delegation to local specialist models, enabling high-privacy execution where sensitive data stays on-device. Finally, to assess whether agents can handle authentic everyday usage, we introduce AndroidDaily, a benchmark grounded in real-world mobile usage patterns with 3146 static actions and 235 end-to-end tasks across high-frequency daily scenarios (8B: static 89.91%, end-to-end 52.50%). Our work advances the development of practical GUI agents and demonstrates strong potential for real-world deployment in everyday digital interactions.
SpatialActor: Exploring Disentangled Spatial Representations for Robust Robotic Manipulation
Nov 12, 2025Robotic manipulation requires precise spatial understanding to interact with objects in the real world. Point-based methods suffer from sparse sampling, leading to the loss of fine-grained semantics. Image-based methods typically feed RGB and depth into 2D backbones pre-trained on 3D auxiliary tasks, but their entangled semantics and geometry are sensitive to inherent depth noise in real-world that disrupts semantic understanding. Moreover, these methods focus on high-level geometry while overlooking low-level spatial cues essential for precise interaction. We propose SpatialActor, a disentangled framework for robust robotic manipulation that explicitly decouples semantics and geometry. The Semantic-guided Geometric Module adaptively fuses two complementary geometry from noisy depth and semantic-guided expert priors. Also, a Spatial Transformer leverages low-level spatial cues for accurate 2D-3D mapping and enables interaction among spatial features. We evaluate SpatialActor on multiple simulation and real-world scenarios across 50+ tasks. It achieves state-of-the-art performance with 87.4% on RLBench and improves by 13.9% to 19.4% under varying noisy conditions, showing strong robustness. Moreover, it significantly enhances few-shot generalization to new tasks and maintains robustness under various spatial perturbations. Project Page: https://shihao1895.github.io/SpatialActor
Step-Audio-EditX Technical Report
Nov 05, 2025


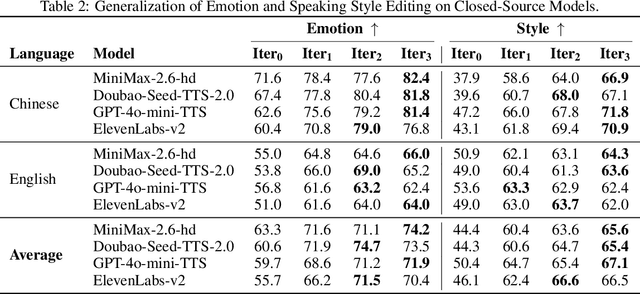
We present Step-Audio-EditX, the first open-source LLM-based audio model excelling at expressive and iterative audio editing encompassing emotion, speaking style, and paralinguistics alongside robust zero-shot text-to-speech (TTS) capabilities.Our core innovation lies in leveraging only large-margin synthetic data, which circumvents the need for embedding-based priors or auxiliary modules. This large-margin learning approach enables both iterative control and high expressivity across voices, and represents a fundamental pivot from the conventional focus on representation-level disentanglement. Evaluation results demonstrate that Step-Audio-EditX surpasses both MiniMax-2.6-hd and Doubao-Seed-TTS-2.0 in emotion editing and other fine-grained control tasks.
Mind-Paced Speaking: A Dual-Brain Approach to Real-Time Reasoning in Spoken Language Models
Oct 10, 2025Real-time Spoken Language Models (SLMs) struggle to leverage Chain-of-Thought (CoT) reasoning due to the prohibitive latency of generating the entire thought process sequentially. Enabling SLMs to think while speaking, similar to humans, is attracting increasing attention. We present, for the first time, Mind-Paced Speaking (MPS), a brain-inspired framework that enables high-fidelity, real-time reasoning. Similar to how humans utilize distinct brain regions for thinking and responding, we propose a novel dual-brain approach, employing a "Formulation Brain" for high-level reasoning to pace and guide a separate "Articulation Brain" for fluent speech generation. This division of labor eliminates mode-switching, preserving the integrity of the reasoning process. Experiments show that MPS significantly outperforms existing think-while-speaking methods and achieves reasoning performance comparable to models that pre-compute the full CoT before speaking, while drastically reducing latency. Under a zero-latency configuration, the proposed method achieves an accuracy of 92.8% on the mathematical reasoning task Spoken-MQA and attains a score of 82.5 on the speech conversation task URO-Bench. Our work effectively bridges the gap between high-quality reasoning and real-time interaction.
An Energy-Efficient Edge Coprocessor for Neural Rendering with Explicit Data Reuse Strategies
Oct 09, 2025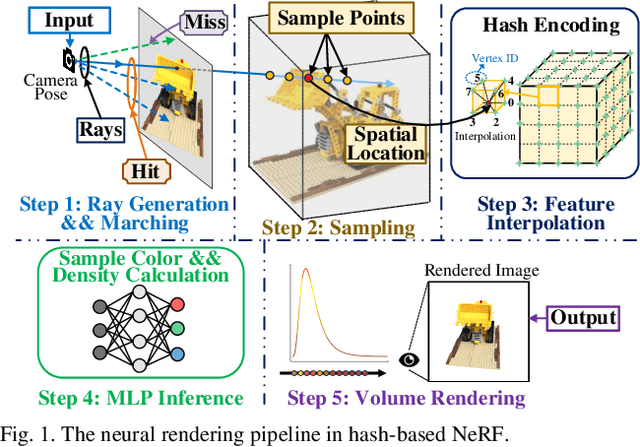
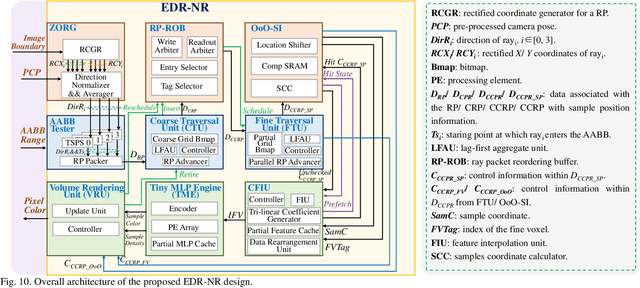
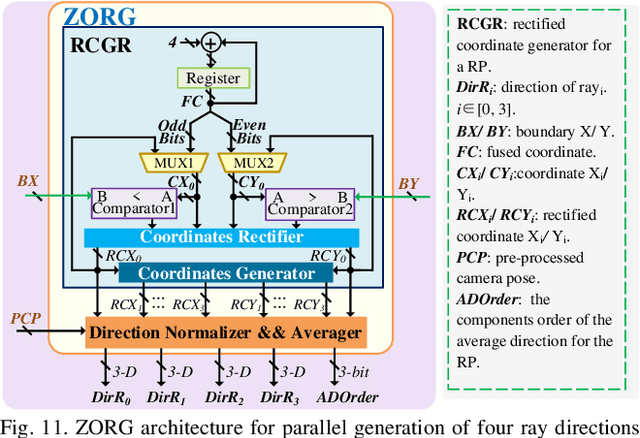
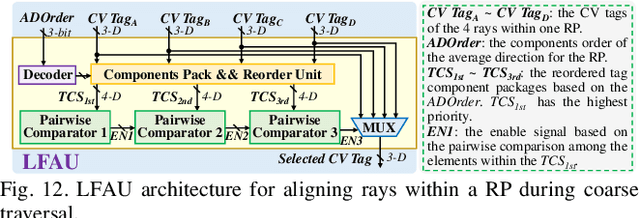
Neural radiance fields (NeRF) have transformed 3D reconstruction and rendering, facilitating photorealistic image synthesis from sparse viewpoints. This work introduces an explicit data reuse neural rendering (EDR-NR) architecture, which reduces frequent external memory accesses (EMAs) and cache misses by exploiting the spatial locality from three phases, including rays, ray packets (RPs), and samples. The EDR-NR architecture features a four-stage scheduler that clusters rays on the basis of Z-order, prioritize lagging rays when ray divergence happens, reorders RPs based on spatial proximity, and issues samples out-of-orderly (OoO) according to the availability of on-chip feature data. In addition, a four-tier hierarchical RP marching (HRM) technique is integrated with an axis-aligned bounding box (AABB) to facilitate spatial skipping (SS), reducing redundant computations and improving throughput. Moreover, a balanced allocation strategy for feature storage is proposed to mitigate SRAM bank conflicts. Fabricated using a 40 nm process with a die area of 10.5 mmX, the EDR-NR chip demonstrates a 2.41X enhancement in normalized energy efficiency, a 1.21X improvement in normalized area efficiency, a 1.20X increase in normalized throughput, and a 53.42% reduction in on-chip SRAM consumption compared to state-of-the-art accelerators.