 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Preliminary Exploration Towards General Image Restoration
Aug 27, 2024



Despite the tremendous success of deep models in various individual image restoration tasks, there are at least two major technical challenges preventing these works from being applied to real-world usages: (1) the lack of generalization ability and (2) the complex and unknown degradations in real-world scenarios. Existing deep models, tailored for specific individual image restoration tasks, often fall short in effectively addressing these challenges. In this paper, we present a new problem called general image restoration (GIR) which aims to address these challenges within a unified model. GIR covers most individual image restoration tasks (\eg, image denoising, deblurring, deraining and super-resolution) and their combinations for general purposes. This paper proceeds to delineate the essential aspects of GIR, including problem definition and the overarching significance of generalization performance. Moreover, the establishment of new datasets and a thorough evaluation framework for GIR models is discussed. We conduct a comprehensive evaluation of existing approaches for tackling the GIR challenge, illuminating their strengths and pragmatic challenges. By analyzing these approaches, we not only underscore the effectiveness of GIR but also highlight the difficulties in its practical implementation. At last, we also try to understand and interpret these models' behaviors to inspire the future direction. Our work can open up new valuable research directions and contribute to the research of general vision.
DemMamba: Alignment-free Raw Video Demoireing with Frequency-assisted Spatio-Temporal Mamba
Aug 20, 2024



Moire patterns arise when two similar repetitive patterns interfere, a phenomenon frequently observed during the capture of images or videos on screens. The color, shape, and location of moire patterns may differ across video frames, posing a challenge in learning information from adjacent frames and preserving temporal consistency. Previous video demoireing methods heavily rely on well-designed alignment modules, resulting in substantial computational burdens. Recently, Mamba, an improved version of the State Space Model (SSM), has demonstrated significant potential for modeling long-range dependencies with linear complexity, enabling efficient temporal modeling in video demoireing without requiring a specific alignment module. In this paper, we propose a novel alignment-free Raw video demoireing network with frequency-assisted spatio-temporal Mamba (DemMamba). The Spatial Mamba Block (SMB) and Temporal Mamba Block (TMB) are sequentially arranged to facilitate effective intra- and inter-relationship modeling in Raw videos with moire patterns. Within SMB, an Adaptive Frequency Block (AFB) is introduced to aid demoireing in the frequency domain. For TMB, a Channel Attention Block (CAB) is embedded to further enhance temporal information interactions by exploiting the inter-channel relationships among features. Extensive experiments demonstrate that our proposed DemMamba surpasses state-of-the-art approaches by 1.3 dB and delivers a superior visual experience.
Learning A Low-Level Vision Generalist via Visual Task Prompt
Aug 16, 2024Building a unified model for general low-level vision tasks holds significant research and practical value. Current methods encounter several critical issues. Multi-task restoration approaches can address multiple degradation-to-clean restoration tasks, while their applicability to tasks with different target domains (e.g., image stylization) is limited. Methods like PromptGIP can handle multiple input-target domains but rely on the Masked Autoencoder (MAE) paradigm. Consequently, they are tied to the ViT architecture, resulting in suboptimal image reconstruction quality. In addition, these methods are sensitive to prompt image content and often struggle with low-frequency information processing. In this paper, we propose a Visual task Prompt-based Image Processing (VPIP) framework to overcome these challenges. VPIP employs visual task prompts to manage tasks with different input-target domains and allows flexible selection of backbone network suitable for general tasks. Besides, a new prompt cross-attention is introduced to facilitate interaction between the input and prompt information. Based on the VPIP framework, we train a low-level vision generalist model, namely GenLV, on 30 diverse tasks. Experimental results show that GenLV can successfully address a variety of low-level tasks, significantly outperforming existing methods both quantitatively and qualitatively. Codes are available at https://github.com/chxy95/GenLV.
An Extended Kalman Filter Integrated Latent Feature Model on Dynamic Weighted Directed Graphs
Jul 31, 2024A dynamic weighted directed graph (DWDG) is commonly encountered in various application scenarios. It involves extensive dynamic interactions among numerous nodes. Most existing approaches explore the intricate temporal patterns hidden in a DWDG from the purely data-driven perspective, which suffers from accuracy loss when a DWDG exhibits strong fluctuations over time. To address this issue, this study proposes a novel Extended-Kalman-Filter-Incorporated Latent Feature (EKLF) model to represent a DWDG from the model-driven perspective. Its main idea is divided into the following two-fold ideas: a) adopting a control model, i.e., the Extended Kalman Filter (EKF), to track the complex temporal patterns precisely with its nonlinear state-transition and observation functions; and b) introducing an alternating least squares (ALS) algorithm to train the latent features (LFs) alternatively for precisely representing a DWDG. Empirical studies on DWDG datasets demonstrate that the proposed EKLF model outperforms state-of-the-art models in prediction accuracy and computational efficiency for missing edge weights of a DWDG. It unveils the potential for precisely representing a DWDG by incorporating a control model.
Imperative Learning: A Self-supervised Neural-Symbolic Learning Framework for Robot Autonomy
Jun 23, 2024



Data-driven methods such as reinforcement and imitation learning have achieved remarkable success in robot autonomy. However, their data-centric nature still hinders them from generalizing well to ever-changing environments. Moreover, collecting large datasets for robotic tasks is often impractical and expensive. To overcome these challenges, we introduce a new self-supervised neural-symbolic (NeSy) computational framework, imperative learning (IL), for robot autonomy, leveraging the generalization abilities of symbolic reasoning. The framework of IL consists of three primary components: a neural module, a reasoning engine, and a memory system. We formulate IL as a special bilevel optimization (BLO), which enables reciprocal learning over the three modules. This overcomes the label-intensive obstacles associated with data-driven approaches and takes advantage of symbolic reasoning concerning logical reasoning, physical principles, geometric analysis, etc. We discuss several optimization techniques for IL and verify their effectiveness in five distinct robot autonomy tasks including path planning, rule induction, optimal control, visual odometry, and multi-robot routing. Through various experiments, we show that IL can significantly enhance robot autonomy capabilities and we anticipate that it will catalyze further research across diverse domains.
Non-destructive Degradation Pattern Decoupling for Ultra-early Battery Prototype Verification Using Physics-informed Machine Learning
Jun 01, 2024



Manufacturing complexities and uncertainties have impeded the transition from material prototypes to commercial batteries, making prototype verification critical to quality assessment. A fundamental challenge involves deciphering intertwined chemical processes to characterize degradation patterns and their quantitative relationship with battery performance. Here we show that a physics-informed machine learning approach can quantify and visualize temporally resolved losses concerning thermodynamics and kinetics only using electric signals. Our method enables non-destructive degradation pattern characterization, expediting temperature-adaptable predictions of entire lifetime trajectories, rather than end-of-life points. The verification speed is 25 times faster yet maintaining 95.1% accuracy across temperatures. Such advances facilitate more sustainable management of defective prototypes before massive production, establishing a 19.76 billion USD scrap material recycling market by 2060 in China. By incorporating stepwise charge acceptance as a measure of the initial manufacturing variability of normally identical batteries, we can immediately identify long-term degradation variations. We attribute the predictive power to interpreting machine learning insights using material-agnostic featurization taxonomy for degradation pattern decoupling. Our findings offer new possibilities for dynamic system analysis, such as battery prototype degradation, demonstrating that complex pattern evolutions can be accurately predicted in a non-destructive and data-driven fashion by integrating physics-informed machine learning.
DiffuBox: Refining 3D Object Detection with Point Diffusion
May 25, 2024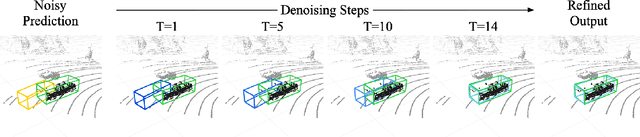
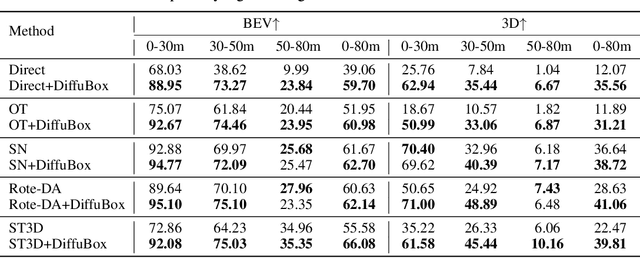
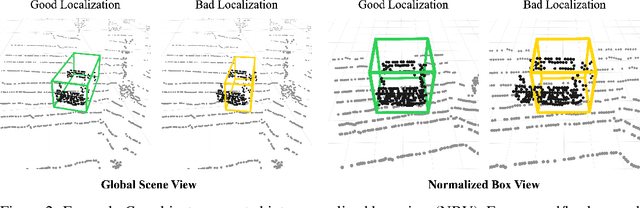
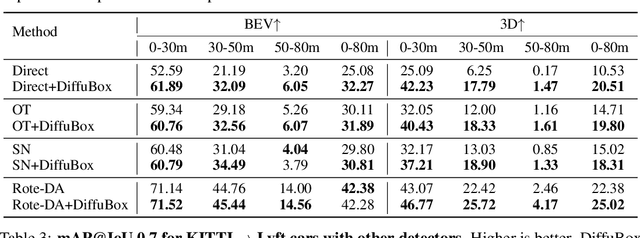
Ensuring robust 3D object detection and localization is crucial for many applications in robotics and autonomous driving. Recent models, however, face difficulties in maintaining high performance when applied to domains with differing sensor setups or geographic locations, often resulting in poor localization accuracy due to domain shift. To overcome this challenge, we introduce a novel diffusion-based box refinement approach. This method employs a domain-agnostic diffusion model, conditioned on the LiDAR points surrounding a coarse bounding box, to simultaneously refine the box's location, size, and orientation. We evaluate this approach under various domain adaptation settings, and our results reveal significant improvements across different datasets, object classes and detectors.
Block-Map-Based Localization in Large-Scale Environment
Apr 28, 2024Accurate localization is an essential technology for the flexible navigation of robots in large-scale environments. Both SLAM-based and map-based localization will increase the computing load due to the increase in map size, which will affect downstream tasks such as robot navigation and services. To this end, we propose a localization system based on Block Maps (BMs) to reduce the computational load caused by maintaining large-scale maps. Firstly, we introduce a method for generating block maps and the corresponding switching strategies, ensuring that the robot can estimate the state in large-scale environments by loading local map information. Secondly, global localization according to Branch-and-Bound Search (BBS) in the 3D map is introduced to provide the initial pose. Finally, a graph-based optimization method is adopted with a dynamic sliding window that determines what factors are being marginalized whether a robot is exposed to a BM or switching to another one, which maintains the accuracy and efficiency of pose tracking. Comparison experiments are performed on publicly available large-scale datasets. Results show that the proposed method can track the robot pose even though the map scale reaches more than 6 kilometers, while efficient and accurate localization is still guaranteed on NCLT and M2DGR.
Bracketing Image Restoration and Enhancement with High-Low Frequency Decomposition
Apr 24, 2024



In real-world scenarios, due to a series of image degradations, obtaining high-quality, clear content photos is challenging. While significant progress has been made in synthesizing high-quality images, previous methods for image restoration and enhancement often overlooked the characteristics of different degradations. They applied the same structure to address various types of degradation, resulting in less-than-ideal restoration outcomes. Inspired by the notion that high/low frequency information is applicable to different degradations, we introduce HLNet, a Bracketing Image Restoration and Enhancement method based on high-low frequency decomposition. Specifically, we employ two modules for feature extraction: shared weight modules and non-shared weight modules. In the shared weight modules, we use SCConv to extract common features from different degradations. In the non-shared weight modules, we introduce the High-Low Frequency Decomposition Block (HLFDB), which employs different methods to handle high-low frequency information, enabling the model to address different degradations more effectively. Compared to other networks, our method takes into account the characteristics of different degradations, thus achieving higher-quality image restoration.
iA$^*$: Imperative Learning-based A$^*$ Search for Pathfinding
Mar 23, 2024The pathfinding problem, which aims to identify a collision-free path between two points, is crucial for many applications, such as robot navigation and autonomous driving. Classic methods, such as A$^*$ search, perform well on small-scale maps but face difficulties scaling up. Conversely, data-driven approaches can improve pathfinding efficiency but require extensive data labeling and lack theoretical guarantees, making it challenging for practical applications. To combine the strengths of the two methods, we utilize the imperative learning (IL) strategy and propose a novel self-supervised pathfinding framework, termed imperative learning-based A$^*$ (iA$^*$). Specifically, iA$^*$ is a bilevel optimization process where the lower-level optimization is dedicated to finding the optimal path by a differentiable A$^*$ search module, and the upper-level optimization narrows down the search space to improve efficiency via setting suitable initial values from a data-driven model. Besides, the model within the upper-level optimization is a fully convolutional network, trained by the calculated loss in the lower-level optimization. Thus, the framework avoids extensive data labeling and can be applied in diverse environments. Our comprehensive experiments demonstrate that iA$^*$ surpasses both classical and data-driven methods in pathfinding efficiency and shows superior robustness among different tasks, validated with public datasets and simulation environments.