 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow can Diffusion Models Evolve into Continual Generators?
May 17, 2025While diffusion models have achieved remarkable success in static data generation, their deployment in streaming or continual learning (CL) scenarios faces a major challenge: catastrophic forgetting (CF), where newly acquired generative capabilities overwrite previously learned ones. To systematically address this, we introduce a formal Continual Diffusion Generation (CDG) paradigm that characterizes and redefines CL in the context of generative diffusion models. Prior efforts often adapt heuristic strategies from continual classification tasks but lack alignment with the underlying diffusion process. In this work, we develop the first theoretical framework for CDG by analyzing cross-task dynamics in diffusion-based generative modeling. Our analysis reveals that the retention and stability of generative knowledge across tasks are governed by three key consistency criteria: inter-task knowledge consistency (IKC), unconditional knowledge consistency (UKC), and label knowledge consistency (LKC). Building on these insights, we propose Continual Consistency Diffusion (CCD), a principled framework that integrates these consistency objectives into training via hierarchical loss terms $\mathcal{L}_{IKC}$, $\mathcal{L}_{UKC}$, and $\mathcal{L}_{LKC}$. This promotes effective knowledge retention while enabling the assimilation of new generative capabilities. Extensive experiments on four benchmark datasets demonstrate that CCD achieves state-of-the-art performance under continual settings, with substantial gains in Mean Fidelity (MF) and Incremental Mean Fidelity (IMF), particularly in tasks with rich cross-task knowledge overlap.
Lumina-OmniLV: A Unified Multimodal Framework for General Low-Level Vision
Apr 08, 2025We present Lunima-OmniLV (abbreviated as OmniLV), a universal multimodal multi-task framework for low-level vision that addresses over 100 sub-tasks across four major categories: image restoration, image enhancement, weak-semantic dense prediction, and stylization. OmniLV leverages both textual and visual prompts to offer flexible and user-friendly interactions. Built on Diffusion Transformer (DiT)-based generative priors, our framework supports arbitrary resolutions -- achieving optimal performance at 1K resolution -- while preserving fine-grained details and high fidelity. Through extensive experiments, we demonstrate that separately encoding text and visual instructions, combined with co-training using shallow feature control, is essential to mitigate task ambiguity and enhance multi-task generalization. Our findings also reveal that integrating high-level generative tasks into low-level vision models can compromise detail-sensitive restoration. These insights pave the way for more robust and generalizable low-level vision systems.
CornerPoint3D: Look at the Nearest Corner Instead of the Center
Apr 03, 2025



3D object detection aims to predict object centers, dimensions, and rotations from LiDAR point clouds. Despite its simplicity, LiDAR captures only the near side of objects, making center-based detectors prone to poor localization accuracy in cross-domain tasks with varying point distributions. Meanwhile, existing evaluation metrics designed for single-domain assessment also suffer from overfitting due to dataset-specific size variations. A key question arises: Do we really need models to maintain excellent performance in the entire 3D bounding boxes after being applied across domains? Actually, one of our main focuses is on preventing collisions between vehicles and other obstacles, especially in cross-domain scenarios where correctly predicting the sizes is much more difficult. To address these issues, we rethink cross-domain 3D object detection from a practical perspective. We propose two new metrics that evaluate a model's ability to detect objects' closer-surfaces to the LiDAR sensor. Additionally, we introduce EdgeHead, a refinement head that guides models to focus more on learnable closer surfaces, significantly improving cross-domain performance under both our new and traditional BEV/3D metrics. Furthermore, we argue that predicting the nearest corner rather than the object center enhances robustness. We propose a novel 3D object detector, coined as CornerPoint3D, which is built upon CenterPoint and uses heatmaps to supervise the learning and detection of the nearest corner of each object. Our proposed methods realize a balanced trade-off between the detection quality of entire bounding boxes and the locating accuracy of closer surfaces to the LiDAR sensor, outperforming the traditional center-based detector CenterPoint in multiple cross-domain tasks and providing a more practically reasonable and robust cross-domain 3D object detection solution.
Exploiting Task Relationships for Continual Learning Using Transferability-Aware Task Embeddings
Feb 17, 2025



Continual learning (CL) has been an essential topic in the contemporary application of deep neural networks, where catastrophic forgetting (CF) can impede a model's ability to acquire knowledge progressively. Existing CL strategies primarily address CF by regularizing model updates or separating task-specific and shared components. However, these methods focus on task model elements while overlooking the potential of leveraging inter-task relationships for learning enhancement. To address this, we propose a transferability-aware task embedding named H-embedding and train a hypernet under its guidance to learn task-conditioned model weights for CL tasks. Particularly, H-embedding is introduced based on an information theoretical transferability measure and is designed to be online and easy to compute. The framework is also characterized by notable practicality, which only requires storing a low-dimensional task embedding for each task, and can be efficiently trained in an end-to-end way. Extensive evaluations and experimental analyses on datasets including Permuted MNIST, Cifar10/100, and ImageNet-R demonstrate that our framework performs prominently compared to various baseline methods, displaying great potential in exploiting intrinsic task relationships.
RALLRec: Improving Retrieval Augmented Large Language Model Recommendation with Representation Learning
Feb 10, 2025Large Language Models (LLMs) have been integrated into recommendation systems to enhance user behavior comprehension. The Retrieval Augmented Generation (RAG) technique is further incorporated into these systems to retrieve more relevant items and improve system performance. However, existing RAG methods rely primarily on textual semantics and often fail to incorporate the most relevant items, limiting the effectiveness of the systems. In this paper, we propose Representation learning for retrieval-Augmented Large Language model Recommendation (RALLRec). Specifically, we enhance textual semantics by prompting LLMs to generate more detailed item descriptions, followed by joint representation learning of textual and collaborative semantics, which are extracted by the LLM and recommendation models, respectively. Considering the potential time-varying characteristics of user interest, a simple yet effective reranking method is further introduced to capture the dynamics of user preference. We conducted extensive experiments on three real-world datasets, and the evaluation results validated the effectiveness of our method. Code is made public at https://github.com/JianXu95/RALLRec.
DiffVSR: Enhancing Real-World Video Super-Resolution with Diffusion Models for Advanced Visual Quality and Temporal Consistency
Jan 17, 2025
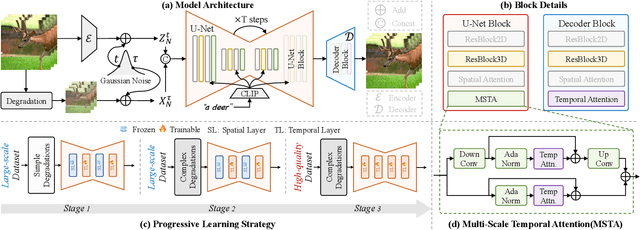
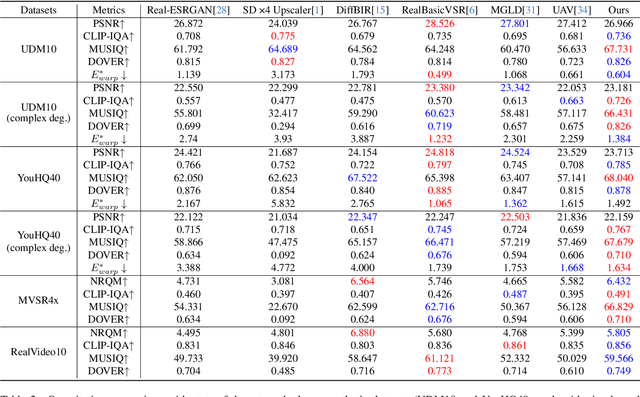
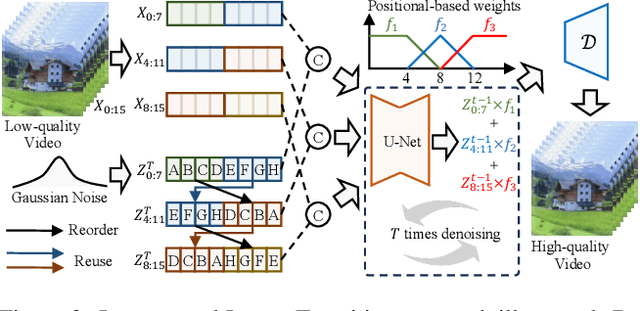
Diffusion models have demonstrated exceptional capabilities in image generation and restoration, yet their application to video super-resolution faces significant challenges in maintaining both high fidelity and temporal consistency. We present DiffVSR, a diffusion-based framework for real-world video super-resolution that effectively addresses these challenges through key innovations. For intra-sequence coherence, we develop a multi-scale temporal attention module and temporal-enhanced VAE decoder that capture fine-grained motion details. To ensure inter-sequence stability, we introduce a noise rescheduling mechanism with an interweaved latent transition approach, which enhances temporal consistency without additional training overhead. We propose a progressive learning strategy that transitions from simple to complex degradations, enabling robust optimization despite limited high-quality video data. Extensive experiments demonstrate that DiffVSR delivers superior results in both visual quality and temporal consistency, setting a new performance standard in real-world video super-resolution.
Controllable Distortion-Perception Tradeoff Through Latent Diffusion for Neural Image Compression
Dec 16, 2024



Neural image compression often faces a challenging trade-off among rate, distortion and perception. While most existing methods typically focus on either achieving high pixel-level fidelity or optimizing for perceptual metrics, we propose a novel approach that simultaneously addresses both aspects for a fixed neural image codec. Specifically, we introduce a plug-and-play module at the decoder side that leverages a latent diffusion process to transform the decoded features, enhancing either low distortion or high perceptual quality without altering the original image compression codec. Our approach facilitates fusion of original and transformed features without additional training, enabling users to flexibly adjust the balance between distortion and perception during inference. Extensive experimental results demonstrate that our method significantly enhances the pretrained codecs with a wide, adjustable distortion-perception range while maintaining their original compression capabilities. For instance, we can achieve more than 150% improvement in LPIPS-BDRate without sacrificing more than 1 dB in PSNR.
WeatherGFM: Learning A Weather Generalist Foundation Model via In-context Learning
Nov 08, 2024



The Earth's weather system encompasses intricate weather data modalities and diverse weather understanding tasks, which hold significant value to human life. Existing data-driven models focus on single weather understanding tasks (e.g., weather forecasting). Although these models have achieved promising results, they fail to tackle various complex tasks within a single and unified model. Moreover, the paradigm that relies on limited real observations for a single scenario hinders the model's performance upper bound. In response to these limitations, we draw inspiration from the in-context learning paradigm employed in state-of-the-art visual foundation models and large language models. In this paper, we introduce the first generalist weather foundation model (WeatherGFM), designed to address a wide spectrum of weather understanding tasks in a unified manner. More specifically, we initially unify the representation and definition of the diverse weather understanding tasks. Subsequently, we devised weather prompt formats to manage different weather data modalities, namely single, multiple, and temporal modalities. Finally, we adopt a visual prompting question-answering paradigm for the training of unified weather understanding tasks. Extensive experiments indicate that our WeatherGFM can effectively handle up to ten weather understanding tasks, including weather forecasting, super-resolution, weather image translation, and post-processing. Our method also showcases generalization ability on unseen tasks.
Learning 3D Perception from Others' Predictions
Oct 03, 2024



Accurate 3D object detection in real-world environments requires a huge amount of annotated data with high quality. Acquiring such data is tedious and expensive, and often needs repeated effort when a new sensor is adopted or when the detector is deployed in a new environment. We investigate a new scenario to construct 3D object detectors: learning from the predictions of a nearby unit that is equipped with an accurate detector. For example, when a self-driving car enters a new area, it may learn from other traffic participants whose detectors have been optimized for that area. This setting is label-efficient, sensor-agnostic, and communication-efficient: nearby units only need to share the predictions with the ego agent (e.g., car). Naively using the received predictions as ground-truths to train the detector for the ego car, however, leads to inferior performance. We systematically study the problem and identify viewpoint mismatches and mislocalization (due to synchronization and GPS errors) as the main causes, which unavoidably result in false positives, false negatives, and inaccurate pseudo labels. We propose a distance-based curriculum, first learning from closer units with similar viewpoints and subsequently improving the quality of other units' predictions via self-training. We further demonstrate that an effective pseudo label refinement module can be trained with a handful of annotated data, largely reducing the data quantity necessary to train an object detector. We validate our approach on the recently released real-world collaborative driving dataset, using reference cars' predictions as pseudo labels for the ego car. Extensive experiments including several scenarios (e.g., different sensors, detectors, and domains) demonstrate the effectiveness of our approach toward label-efficient learning of 3D perception from other units' predictions.
GlobalMapNet: An Online Framework for Vectorized Global HD Map Construction
Sep 17, 2024



High-definition (HD) maps are essential for autonomous driving systems. Traditionally, an expensive and labor-intensive pipeline is implemented to construct HD maps, which is limited in scalability. In recent years, crowdsourcing and online mapping have emerged as two alternative methods, but they have limitations respectively. In this paper, we provide a novel methodology, namely global map construction, to perform direct generation of vectorized global maps, combining the benefits of crowdsourcing and online mapping. We introduce GlobalMapNet, the first online framework for vectorized global HD map construction, which updates and utilizes a global map on the ego vehicle. To generate the global map from scratch, we propose GlobalMapBuilder to match and merge local maps continuously. We design a new algorithm, Map NMS, to remove duplicate map elements and produce a clean map. We also propose GlobalMapFusion to aggregate historical map information, improving consistency of prediction. We examine GlobalMapNet on two widely recognized datasets, Argoverse2 and nuScenes, showing that our framework is capable of generating globally consistent results.