 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen the City Teaches the Car: Label-Free 3D Perception from Infrastructure
Mar 17, 2026Building robust 3D perception for self-driving still relies heavily on large-scale data collection and manual annotation, yet this paradigm becomes impractical as deployment expands across diverse cities and regions. Meanwhile, modern cities are increasingly instrumented with roadside units (RSUs), static sensors deployed along roads and at intersections to monitor traffic. This raises a natural question: can the city itself help train the vehicle? We propose infrastructure-taught, label-free 3D perception, a paradigm in which RSUs act as stationary, unsupervised teachers for ego vehicles. Leveraging their fixed viewpoints and repeated observations, RSUs learn local 3D detectors from unlabeled data and broadcast predictions to passing vehicles, which are aggregated as pseudo-label supervision for training a standalone ego detector. The resulting model requires no infrastructure or communication at test time. We instantiate this idea as a fully label-free three-stage pipeline and conduct a concept-and-feasibility study in a CARLA-based multi-agent environment. With CenterPoint, our pipeline achieves 82.3% AP for detecting vehicles, compared to a fully supervised ego upper bound of 94.4%. We further systematically analyze each stage, evaluate its scalability, and demonstrate complementarity with existing ego-centric label-free methods. Together, these results suggest that city infrastructure itself can potentially provide a scalable supervisory signal for autonomous vehicles, positioning infrastructure-taught learning as a promising orthogonal paradigm for reducing annotation cost in 3D perception.
Transfer Your Perspective: Controllable 3D Generation from Any Viewpoint in a Driving Scene
Feb 10, 2025



Self-driving cars relying solely on ego-centric perception face limitations in sensing, often failing to detect occluded, faraway objects. Collaborative autonomous driving (CAV) seems like a promising direction, but collecting data for development is non-trivial. It requires placing multiple sensor-equipped agents in a real-world driving scene, simultaneously! As such, existing datasets are limited in locations and agents. We introduce a novel surrogate to the rescue, which is to generate realistic perception from different viewpoints in a driving scene, conditioned on a real-world sample - the ego-car's sensory data. This surrogate has huge potential: it could potentially turn any ego-car dataset into a collaborative driving one to scale up the development of CAV. We present the very first solution, using a combination of simulated collaborative data and real ego-car data. Our method, Transfer Your Perspective (TYP), learns a conditioned diffusion model whose output samples are not only realistic but also consistent in both semantics and layouts with the given ego-car data. Empirical results demonstrate TYP's effectiveness in aiding in a CAV setting. In particular, TYP enables us to (pre-)train collaborative perception algorithms like early and late fusion with little or no real-world collaborative data, greatly facilitating downstream CAV applications.
Static Segmentation by Tracking: A Frustratingly Label-Efficient Approach to Fine-Grained Segmentation
Jan 12, 2025



We study image segmentation in the biological domain, particularly trait and part segmentation from specimen images (e.g., butterfly wing stripes or beetle body parts). This is a crucial, fine-grained task that aids in understanding the biology of organisms. The conventional approach involves hand-labeling masks, often for hundreds of images per species, and training a segmentation model to generalize these labels to other images, which can be exceedingly laborious. We present a label-efficient method named Static Segmentation by Tracking (SST). SST is built upon the insight: while specimens of the same species have inherent variations, the traits and parts we aim to segment show up consistently. This motivates us to concatenate specimen images into a ``pseudo-video'' and reframe trait and part segmentation as a tracking problem. Concretely, SST generates masks for unlabeled images by propagating annotated or predicted masks from the ``pseudo-preceding'' images. Powered by Segment Anything Model 2 (SAM~2) initially developed for video segmentation, we show that SST can achieve high-quality trait and part segmentation with merely one labeled image per species -- a breakthrough for analyzing specimen images. We further develop a cycle-consistent loss to fine-tune the model, again using one labeled image. Additionally, we highlight the broader potential of SST, including one-shot instance segmentation on images taken in the wild and trait-based image retrieval.
Learning 3D Perception from Others' Predictions
Oct 03, 2024



Accurate 3D object detection in real-world environments requires a huge amount of annotated data with high quality. Acquiring such data is tedious and expensive, and often needs repeated effort when a new sensor is adopted or when the detector is deployed in a new environment. We investigate a new scenario to construct 3D object detectors: learning from the predictions of a nearby unit that is equipped with an accurate detector. For example, when a self-driving car enters a new area, it may learn from other traffic participants whose detectors have been optimized for that area. This setting is label-efficient, sensor-agnostic, and communication-efficient: nearby units only need to share the predictions with the ego agent (e.g., car). Naively using the received predictions as ground-truths to train the detector for the ego car, however, leads to inferior performance. We systematically study the problem and identify viewpoint mismatches and mislocalization (due to synchronization and GPS errors) as the main causes, which unavoidably result in false positives, false negatives, and inaccurate pseudo labels. We propose a distance-based curriculum, first learning from closer units with similar viewpoints and subsequently improving the quality of other units' predictions via self-training. We further demonstrate that an effective pseudo label refinement module can be trained with a handful of annotated data, largely reducing the data quantity necessary to train an object detector. We validate our approach on the recently released real-world collaborative driving dataset, using reference cars' predictions as pseudo labels for the ego car. Extensive experiments including several scenarios (e.g., different sensors, detectors, and domains) demonstrate the effectiveness of our approach toward label-efficient learning of 3D perception from other units' predictions.
Pre-Training LiDAR-Based 3D Object Detectors Through Colorization
Oct 23, 2023Accurate 3D object detection and understanding for self-driving cars heavily relies on LiDAR point clouds, necessitating large amounts of labeled data to train. In this work, we introduce an innovative pre-training approach, Grounded Point Colorization (GPC), to bridge the gap between data and labels by teaching the model to colorize LiDAR point clouds, equipping it with valuable semantic cues. To tackle challenges arising from color variations and selection bias, we incorporate color as "context" by providing ground-truth colors as hints during colorization. Experimental results on the KITTI and Waymo datasets demonstrate GPC's remarkable effectiveness. Even with limited labeled data, GPC significantly improves fine-tuning performance; notably, on just 20% of the KITTI dataset, GPC outperforms training from scratch with the entire dataset. In sum, we introduce a fresh perspective on pre-training for 3D object detection, aligning the objective with the model's intended role and ultimately advancing the accuracy and efficiency of 3D object detection for autonomous vehicles.
Towards Open-World Segmentation of Parts
May 26, 2023Segmenting object parts such as cup handles and animal bodies is important in many real-world applications but requires more annotation effort. The largest dataset nowadays contains merely two hundred object categories, implying the difficulty to scale up part segmentation to an unconstrained setting. To address this, we propose to explore a seemingly simplified but empirically useful and scalable task, class-agnostic part segmentation. In this problem, we disregard the part class labels in training and instead treat all of them as a single part class. We argue and demonstrate that models trained without part classes can better localize parts and segment them on objects unseen in training. We then present two further improvements. First, we propose to make the model object-aware, leveraging the fact that parts are "compositions", whose extents are bounded by the corresponding objects and whose appearances are by nature not independent but bundled. Second, we introduce a novel approach to improve part segmentation on unseen objects, inspired by an interesting finding -- for unseen objects, the pixel-wise features extracted by the model often reveal high-quality part segments. To this end, we propose a novel self-supervised procedure that iterates between pixel clustering and supervised contrastive learning that pulls pixels closer or pushes them away. Via extensive experiments on PartImageNet and Pascal-Part, we show notable and consistent gains by our approach, essentially a critical step towards open-world part segmentation.
Learning with Free Object Segments for Long-Tailed Instance Segmentation
Mar 29, 2022
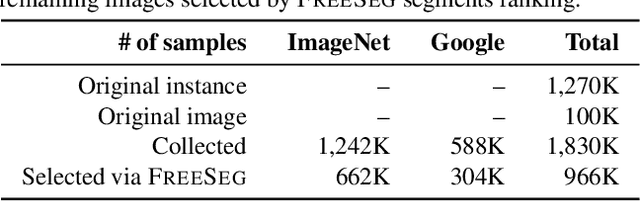
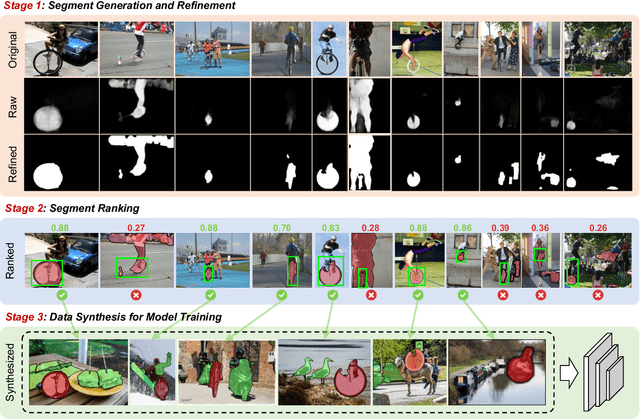
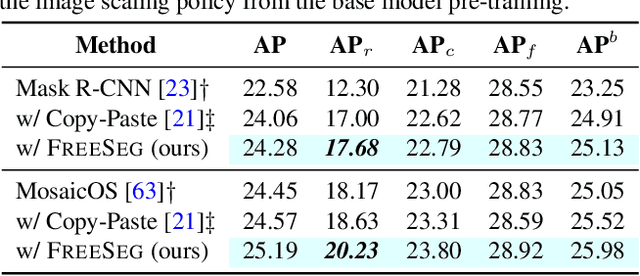
One fundamental challenge in building an instance segmentation model for a large number of classes in complex scenes is the lack of training examples, especially for rare objects. In this paper, we explore the possibility to increase the training examples without laborious data collection and annotation. We find that an abundance of instance segments can potentially be obtained freely from object-centric images, according to two insights: (i) an object-centric image usually contains one salient object in a simple background; (ii) objects from the same class often share similar appearances or similar contrasts to the background. Motivated by these insights, we propose a simple and scalable framework FreeSeg for extracting and leveraging these "free" object foreground segments to facilitate model training in long-tailed instance segmentation. Concretely, we investigate the similarity among object-centric images of the same class to propose candidate segments of foreground instances, followed by a novel ranking of segment quality. The resulting high-quality object segments can then be used to augment the existing long-tailed datasets, e.g., by copying and pasting the segments onto the original training images. Extensive experiments show that FreeSeg yields substantial improvements on top of strong baselines and achieves state-of-the-art accuracy for segmenting rare object categories.
One Step at a Time: Long-Horizon Vision-and-Language Navigation with Milestones
Feb 14, 2022

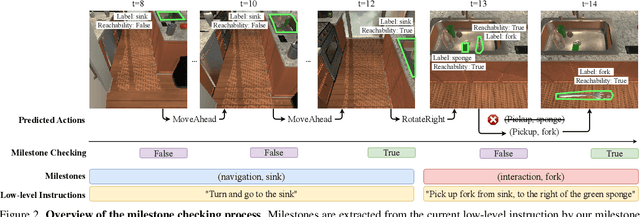
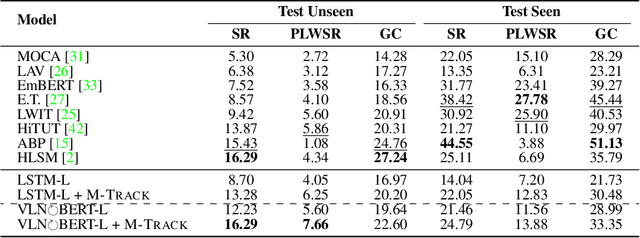
We study the problem of developing autonomous agents that can follow human instructions to infer and perform a sequence of actions to complete the underlying task. Significant progress has been made in recent years, especially for tasks with short horizons. However, when it comes to long-horizon tasks with extended sequences of actions, an agent can easily ignore some instructions or get stuck in the middle of the long instructions and eventually fail the task. To address this challenge, we propose a model-agnostic milestone-based task tracker (M-TRACK) to guide the agent and monitor its progress. Specifically, we propose a milestone builder that tags the instructions with navigation and interaction milestones which the agent needs to complete step by step, and a milestone checker that systemically checks the agent's progress in its current milestone and determines when to proceed to the next. On the challenging ALFRED dataset, our M-TRACK leads to a notable 45% and 70% relative improvement in unseen success rate over two competitive base models.
On Model Calibration for Long-Tailed Object Detection and Instance Segmentation
Jul 05, 2021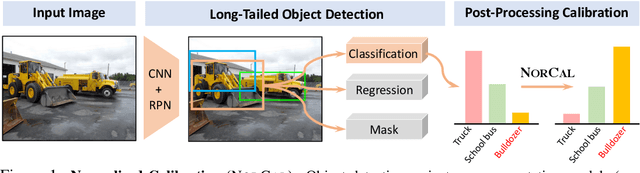
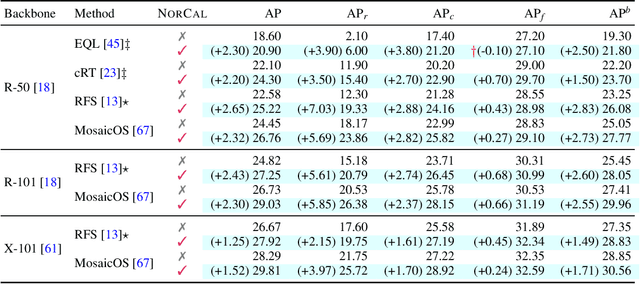
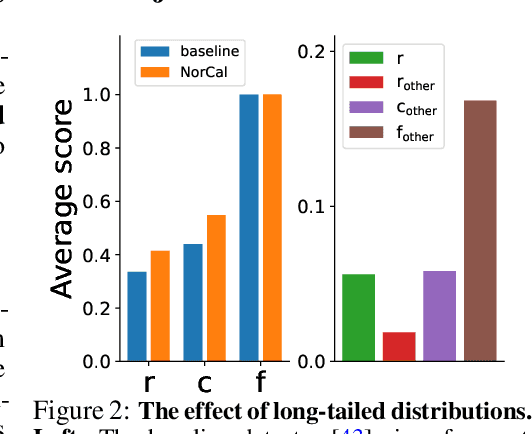

Vanilla models for object detection and instance segmentation suffer from the heavy bias toward detecting frequent objects in the long-tailed setting. Existing methods address this issue mostly during training, e.g., by re-sampling or re-weighting. In this paper, we investigate a largely overlooked approach -- post-processing calibration of confidence scores. We propose NorCal, Normalized Calibration for long-tailed object detection and instance segmentation, a simple and straightforward recipe that reweighs the predicted scores of each class by its training sample size. We show that separately handling the background class and normalizing the scores over classes for each proposal are keys to achieving superior performance. On the LVIS dataset, NorCal can effectively improve nearly all the baseline models not only on rare classes but also on common and frequent classes. Finally, we conduct extensive analysis and ablation studies to offer insights into various modeling choices and mechanisms of our approach.
A Simple and Effective Use of Object-Centric Images for Long-Tailed Object Detection
Feb 17, 2021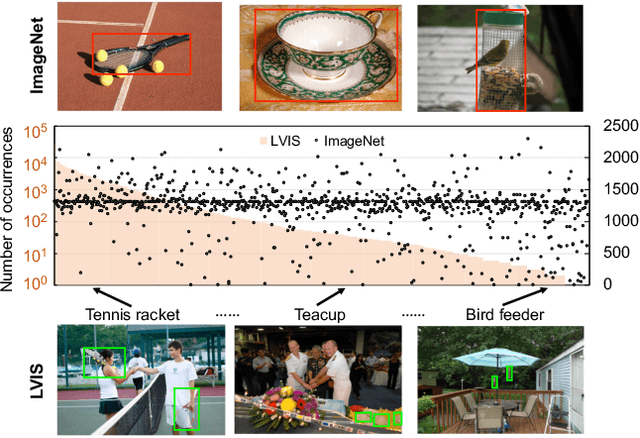
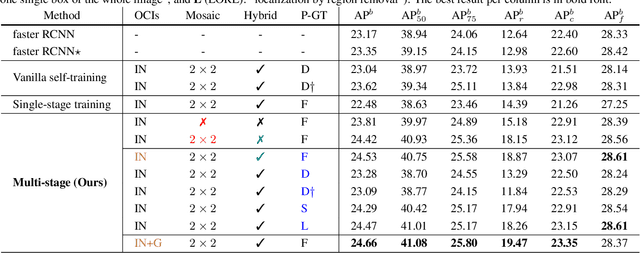

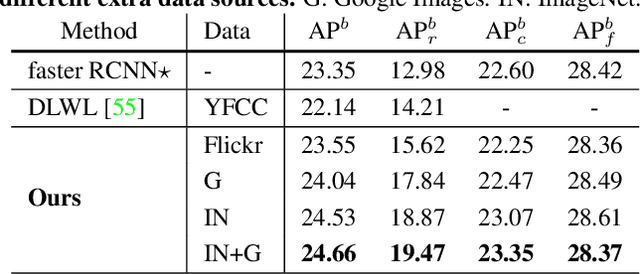
Object frequencies in daily scenes follow a long-tailed distribution. Many objects do not appear frequently enough in scene-centric images (e.g., sightseeing, street views) for us to train accurate object detectors. In contrast, these objects are captured at a higher frequency in object-centric images, which are intended to picture the objects of interest. Motivated by this phenomenon, we propose to take advantage of the object-centric images to improve object detection in scene-centric images. We present a simple yet surprisingly effective framework to do so. On the one hand, our approach turns an object-centric image into a useful training example for object detection in scene-centric images by mitigating the domain gap between the two image sources in both the input and label space. On the other hand, our approach employs a multi-stage procedure to train the object detector, such that the detector learns the diverse object appearances from object-centric images while being tied to the application domain of scene-centric images. On the LVIS dataset, our approach can improve the object detection (and instance segmentation) accuracy of rare objects by 50% (and 33%) relatively, without sacrificing the performance of other classes.