 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoVQA-G: Self-Improving Agentic Framework for Automated Visual Question Answering and Grounding Annotation
Apr 19, 2026Manual annotation of high-quality visual question answering with grounding (VQA-G) datasets, which pair visual questions with evidential grounding, is crucial for advancing vision-language models (VLMs), but remains unscalable. Existing automated methods are often hindered by two key issues: (1) inconsistent data fidelity due to model hallucinations; (2) brittle verification mechanisms based on simple heuristics. To address these limitations, we introduce AutoVQA-G, a self-improving agentic framework for automated VQA-G annotation. AutoVQA-G employs an iterative refinement loop where a Consistency Evaluation module uses Chain-of-Thought (CoT) reasoning for fine-grained visual verification. Based on this feedback, a memory-augmented Prompt Optimization agent analyzes critiques from failed samples to progressively refine generation prompts. Our experiments show that AutoVQA-G generates VQA-G datasets with superior visual grounding accuracy compared to leading multimodal LLMs, offering a promising approach for creating high-fidelity data to facilitate more robust VLM training and evaluation. Code: https://github.com/rohnson1999/AutoVQA-G
RC-GeoCP: Geometric Consensus for Radar-Camera Collaborative Perception
Feb 28, 2026Collaborative perception (CP) enhances scene understanding through multi-agent information sharing. While LiDAR-centric systems offer precise geometry, high costs and performance degradation in adverse weather necessitate multi-modal alternatives. Despite dense visual semantics and robust spatial measurements, the synergy between cameras and 4D radar remains underexplored in collaborative settings. This work introduces RC-GeoCP, the first framework to explore the fusion of 4D radar and images in CP. To resolve misalignment caused by depth ambiguity and spatial dispersion across agents, RC-GeoCP establishes a radar-anchored geometric consensus. Specifically, Geometric Structure Rectification (GSR) aligns visual semantics with geometry derived from radar to generate spatially grounded, geometry-consistent representations. Uncertainty-Aware Communication (UAC) formulates selective transmission as a conditional entropy reduction process to prioritize informative features based on inter-agent disagreement. Finally, the Consensus-Driven Assembler (CDA) aggregates multi-agent information via shared geometric anchors to form a globally coherent representation. We establish the first unified radar-camera CP benchmark on V2X-Radar and V2X-R, demonstrating state-of-the-art performance with significantly reduced communication overhead. Code will be released soon.
WaterVideoQA: ASV-Centric Perception and Rule-Compliant Reasoning via Multi-Modal Agents
Feb 26, 2026While autonomous navigation has achieved remarkable success in passive perception (e.g., object detection and segmentation), it remains fundamentally constrained by a void in knowledge-driven, interactive environmental cognition. In the high-stakes domain of maritime navigation, the ability to bridge the gap between raw visual perception and complex cognitive reasoning is not merely an enhancement but a critical prerequisite for Autonomous Surface Vessels to execute safe and precise maneuvers. To this end, we present WaterVideoQA, the first large-scale, comprehensive Video Question Answering benchmark specifically engineered for all-waterway environments. This benchmark encompasses 3,029 video clips across six distinct waterway categories, integrating multifaceted variables such as volatile lighting and dynamic weather to rigorously stress-test ASV capabilities across a five-tier hierarchical cognitive framework. Furthermore, we introduce NaviMind, a pioneering multi-agent neuro-symbolic system designed for open-ended maritime reasoning. By synergizing Adaptive Semantic Routing, Situation-Aware Hierarchical Reasoning, and Autonomous Self-Reflective Verification, NaviMind transitions ASVs from superficial pattern matching to regulation-compliant, interpretable decision-making. Experimental results demonstrate that our framework significantly transcends existing baselines, establishing a new paradigm for intelligent, trustworthy interaction in dynamic maritime environments.
HyperDet: 3D Object Detection with Hyper 4D Radar Point Clouds
Feb 13, 20264D mmWave radar provides weather-robust, velocity-aware measurements and is more cost-effective than LiDAR. However, radar-only 3D detection still trails LiDAR-based systems because radar point clouds are sparse, irregular, and often corrupted by multipath noise, yielding weak and unstable geometry. We present HyperDet, a detector-agnostic radar-only 3D detection framework that constructs a task-aware hyper 4D radar point cloud for standard LiDAR-oriented detectors. HyperDet aggregates returns from multiple surround-view 4D radars over consecutive frames to improve coverage and density, then applies geometry-aware cross-sensor consensus validation with a lightweight self-consistency check outside overlap regions to suppress inconsistent returns. It further integrates a foreground-focused diffusion module with training-time mixed radar-LiDAR supervision to densify object structures while lifting radar attributes (e.g., Doppler, RCS); the model is distilled into a consistency model for single-step inference. On MAN TruckScenes, HyperDet consistently improves over raw radar inputs with VoxelNeXt and CenterPoint, partially narrowing the radar-LiDAR gap. These results show that input-level refinement enables radar to better leverage LiDAR-oriented detectors without architectural modifications.
AutoFly: Vision-Language-Action Model for UAV Autonomous Navigation in the Wild
Feb 10, 2026Vision-language navigation (VLN) requires intelligent agents to navigate environments by interpreting linguistic instructions alongside visual observations, serving as a cornerstone task in Embodied AI. Current VLN research for unmanned aerial vehicles (UAVs) relies on detailed, pre-specified instructions to guide the UAV along predetermined routes. However, real-world outdoor exploration typically occurs in unknown environments where detailed navigation instructions are unavailable. Instead, only coarse-grained positional or directional guidance can be provided, requiring UAVs to autonomously navigate through continuous planning and obstacle avoidance. To bridge this gap, we propose AutoFly, an end-to-end Vision-Language-Action (VLA) model for autonomous UAV navigation. AutoFly incorporates a pseudo-depth encoder that derives depth-aware features from RGB inputs to enhance spatial reasoning, coupled with a progressive two-stage training strategy that effectively aligns visual, depth, and linguistic representations with action policies. Moreover, existing VLN datasets have fundamental limitations for real-world autonomous navigation, stemming from their heavy reliance on explicit instruction-following over autonomous decision-making and insufficient real-world data. To address these issues, we construct a novel autonomous navigation dataset that shifts the paradigm from instruction-following to autonomous behavior modeling through: (1) trajectory collection emphasizing continuous obstacle avoidance, autonomous planning, and recognition workflows; (2) comprehensive real-world data integration. Experimental results demonstrate that AutoFly achieves a 3.9% higher success rate compared to state-of-the-art VLA baselines, with consistent performance across simulated and real environments.
4D-CAAL: 4D Radar-Camera Calibration and Auto-Labeling for Autonomous Driving
Jan 29, 20264D radar has emerged as a critical sensor for autonomous driving, primarily due to its enhanced capabilities in elevation measurement and higher resolution compared to traditional 3D radar. Effective integration of 4D radar with cameras requires accurate extrinsic calibration, and the development of radar-based perception algorithms demands large-scale annotated datasets. However, existing calibration methods often employ separate targets optimized for either visual or radar modalities, complicating correspondence establishment. Furthermore, manually labeling sparse radar data is labor-intensive and unreliable. To address these challenges, we propose 4D-CAAL, a unified framework for 4D radar-camera calibration and auto-labeling. Our approach introduces a novel dual-purpose calibration target design, integrating a checkerboard pattern on the front surface for camera detection and a corner reflector at the center of the back surface for radar detection. We develop a robust correspondence matching algorithm that aligns the checkerboard center with the strongest radar reflection point, enabling accurate extrinsic calibration. Subsequently, we present an auto-labeling pipeline that leverages the calibrated sensor relationship to transfer annotations from camera-based segmentations to radar point clouds through geometric projection and multi-feature optimization. Extensive experiments demonstrate that our method achieves high calibration accuracy while significantly reducing manual annotation effort, thereby accelerating the development of robust multi-modal perception systems for autonomous driving.
Wavelet-based Multi-View Fusion of 4D Radar Tensor and Camera for Robust 3D Object Detection
Dec 28, 20254D millimeter-wave (mmWave) radar has been widely adopted in autonomous driving and robot perception due to its low cost and all-weather robustness. However, its inherent sparsity and limited semantic richness significantly constrain perception capability. Recently, fusing camera data with 4D radar has emerged as a promising cost effective solution, by exploiting the complementary strengths of the two modalities. Nevertheless, point-cloud-based radar often suffer from information loss introduced by multi-stage signal processing, while directly utilizing raw 4D radar data incurs prohibitive computational costs. To address these challenges, we propose WRCFormer, a novel 3D object detection framework that fuses raw radar cubes with camera inputs via multi-view representations of the decoupled radar cube. Specifically, we design a Wavelet Attention Module as the basic module of wavelet-based Feature Pyramid Network (FPN) to enhance the representation of sparse radar signals and image data. We further introduce a two-stage query-based, modality-agnostic fusion mechanism termed Geometry-guided Progressive Fusion to efficiently integrate multi-view features from both modalities. Extensive experiments demonstrate that WRCFormer achieves state-of-the-art performance on the K-Radar benchmarks, surpassing the best model by approximately 2.4% in all scenarios and 1.6% in the sleet scenario, highlighting its robustness under adverse weather conditions.
MMDrive: Interactive Scene Understanding Beyond Vision with Multi-representational Fusion
Dec 16, 2025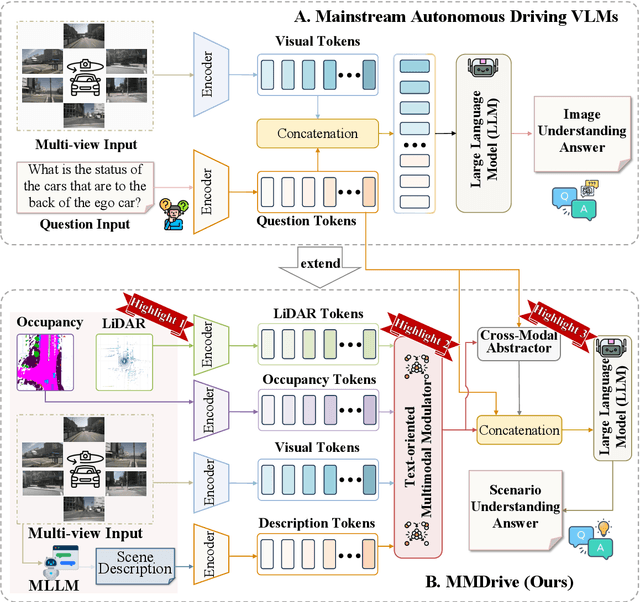
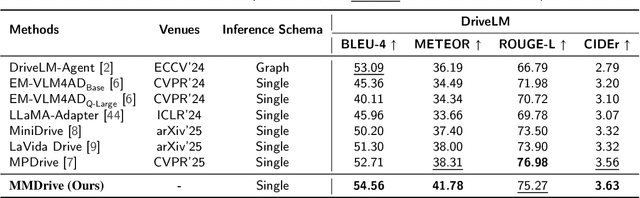


Vision-language models enable the understanding and reasoning of complex traffic scenarios through multi-source information fusion, establishing it as a core technology for autonomous driving. However, existing vision-language models are constrained by the image understanding paradigm in 2D plane, which restricts their capability to perceive 3D spatial information and perform deep semantic fusion, resulting in suboptimal performance in complex autonomous driving environments. This study proposes MMDrive, an multimodal vision-language model framework that extends traditional image understanding to a generalized 3D scene understanding framework. MMDrive incorporates three complementary modalities, including occupancy maps, LiDAR point clouds, and textual scene descriptions. To this end, it introduces two novel components for adaptive cross-modal fusion and key information extraction. Specifically, the Text-oriented Multimodal Modulator dynamically weights the contributions of each modality based on the semantic cues in the question, guiding context-aware feature integration. The Cross-Modal Abstractor employs learnable abstract tokens to generate compact, cross-modal summaries that highlight key regions and essential semantics. Comprehensive evaluations on the DriveLM and NuScenes-QA benchmarks demonstrate that MMDrive achieves significant performance gains over existing vision-language models for autonomous driving, with a BLEU-4 score of 54.56 and METEOR of 41.78 on DriveLM, and an accuracy score of 62.7% on NuScenes-QA. MMDrive effectively breaks the traditional image-only understanding barrier, enabling robust multimodal reasoning in complex driving environments and providing a new foundation for interpretable autonomous driving scene understanding.
Da Yu: Towards USV-Based Image Captioning for Waterway Surveillance and Scene Understanding
Jun 24, 2025Automated waterway environment perception is crucial for enabling unmanned surface vessels (USVs) to understand their surroundings and make informed decisions. Most existing waterway perception models primarily focus on instance-level object perception paradigms (e.g., detection, segmentation). However, due to the complexity of waterway environments, current perception datasets and models fail to achieve global semantic understanding of waterways, limiting large-scale monitoring and structured log generation. With the advancement of vision-language models (VLMs), we leverage image captioning to introduce WaterCaption, the first captioning dataset specifically designed for waterway environments. WaterCaption focuses on fine-grained, multi-region long-text descriptions, providing a new research direction for visual geo-understanding and spatial scene cognition. Exactly, it includes 20.2k image-text pair data with 1.8 million vocabulary size. Additionally, we propose Da Yu, an edge-deployable multi-modal large language model for USVs, where we propose a novel vision-to-language projector called Nano Transformer Adaptor (NTA). NTA effectively balances computational efficiency with the capacity for both global and fine-grained local modeling of visual features, thereby significantly enhancing the model's ability to generate long-form textual outputs. Da Yu achieves an optimal balance between performance and efficiency, surpassing state-of-the-art models on WaterCaption and several other captioning benchmarks.
CornerPoint3D: Look at the Nearest Corner Instead of the Center
Apr 03, 2025



3D object detection aims to predict object centers, dimensions, and rotations from LiDAR point clouds. Despite its simplicity, LiDAR captures only the near side of objects, making center-based detectors prone to poor localization accuracy in cross-domain tasks with varying point distributions. Meanwhile, existing evaluation metrics designed for single-domain assessment also suffer from overfitting due to dataset-specific size variations. A key question arises: Do we really need models to maintain excellent performance in the entire 3D bounding boxes after being applied across domains? Actually, one of our main focuses is on preventing collisions between vehicles and other obstacles, especially in cross-domain scenarios where correctly predicting the sizes is much more difficult. To address these issues, we rethink cross-domain 3D object detection from a practical perspective. We propose two new metrics that evaluate a model's ability to detect objects' closer-surfaces to the LiDAR sensor. Additionally, we introduce EdgeHead, a refinement head that guides models to focus more on learnable closer surfaces, significantly improving cross-domain performance under both our new and traditional BEV/3D metrics. Furthermore, we argue that predicting the nearest corner rather than the object center enhances robustness. We propose a novel 3D object detector, coined as CornerPoint3D, which is built upon CenterPoint and uses heatmaps to supervise the learning and detection of the nearest corner of each object. Our proposed methods realize a balanced trade-off between the detection quality of entire bounding boxes and the locating accuracy of closer surfaces to the LiDAR sensor, outperforming the traditional center-based detector CenterPoint in multiple cross-domain tasks and providing a more practically reasonable and robust cross-domain 3D object detection solution.