 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaussianEM: Model compositional and conformational heterogeneity using 3D Gaussians
Dec 25, 2025Understanding protein flexibility and its dynamic interactions with other molecules is essential for protein function study. Cryogenic electron microscopy (cryo-EM) provides an opportunity to directly observe macromolecular dynamics. However, analyzing datasets that contain both continuous motions and discrete states remains highly challenging. Here we present GaussianEM, a Gaussian pseudo-atomic framework that simultaneously models compositional and conformational heterogeneity from experimental cryo-EM images. GaussianEM employs a two-encoder-one-decoder architecture to map an image to its individual Gaussian components, and represent structural variability through changes in Gaussian parameters. This approach provides an intuitive and interpretable description of conformational changes, preserves local structural consistency along the transition trajectories, and naturally bridges the gap between density-based models and corresponding atomic models. We demonstrate the effectiveness of GaussianEM on both simulated and experimental datasets.
ReaSeq: Unleashing World Knowledge via Reasoning for Sequential Modeling
Dec 24, 2025Industrial recommender systems face two fundamental limitations under the log-driven paradigm: (1) knowledge poverty in ID-based item representations that causes brittle interest modeling under data sparsity, and (2) systemic blindness to beyond-log user interests that constrains model performance within platform boundaries. These limitations stem from an over-reliance on shallow interaction statistics and close-looped feedback while neglecting the rich world knowledge about product semantics and cross-domain behavioral patterns that Large Language Models have learned from vast corpora. To address these challenges, we introduce ReaSeq, a reasoning-enhanced framework that leverages world knowledge in Large Language Models to address both limitations through explicit and implicit reasoning. Specifically, ReaSeq employs explicit Chain-of-Thought reasoning via multi-agent collaboration to distill structured product knowledge into semantically enriched item representations, and latent reasoning via Diffusion Large Language Models to infer plausible beyond-log behaviors. Deployed on Taobao's ranking system serving hundreds of millions of users, ReaSeq achieves substantial gains: >6.0% in IPV and CTR, >2.9% in Orders, and >2.5% in GMV, validating the effectiveness of world-knowledge-enhanced reasoning over purely log-driven approaches.
NL2Repo-Bench: Towards Long-Horizon Repository Generation Evaluation of Coding Agents
Dec 14, 2025Recent advances in coding agents suggest rapid progress toward autonomous software development, yet existing benchmarks fail to rigorously evaluate the long-horizon capabilities required to build complete software systems. Most prior evaluations focus on localized code generation, scaffolded completion, or short-term repair tasks, leaving open the question of whether agents can sustain coherent reasoning, planning, and execution over the extended horizons demanded by real-world repository construction. To address this gap, we present NL2Repo Bench, a benchmark explicitly designed to evaluate the long-horizon repository generation ability of coding agents. Given only a single natural-language requirements document and an empty workspace, agents must autonomously design the architecture, manage dependencies, implement multi-module logic, and produce a fully installable Python library. Our experiments across state-of-the-art open- and closed-source models reveal that long-horizon repository generation remains largely unsolved: even the strongest agents achieve below 40% average test pass rates and rarely complete an entire repository correctly. Detailed analysis uncovers fundamental long-horizon failure modes, including premature termination, loss of global coherence, fragile cross-file dependencies, and inadequate planning over hundreds of interaction steps. NL2Repo Bench establishes a rigorous, verifiable testbed for measuring sustained agentic competence and highlights long-horizon reasoning as a central bottleneck for the next generation of autonomous coding agents.
Global Convergence of Four-Layer Matrix Factorization under Random Initialization
Nov 19, 2025Gradient descent dynamics on the deep matrix factorization problem is extensively studied as a simplified theoretical model for deep neural networks. Although the convergence theory for two-layer matrix factorization is well-established, no global convergence guarantee for general deep matrix factorization under random initialization has been established to date. To address this gap, we provide a polynomial-time global convergence guarantee for randomly initialized gradient descent on four-layer matrix factorization, given certain conditions on the target matrix and a standard balanced regularization term. Our analysis employs new techniques to show saddle-avoidance properties of gradient decent dynamics, and extends previous theories to characterize the change in eigenvalues of layer weights.
DiscoX: Benchmarking Discourse-Level Translation task in Expert Domains
Nov 14, 2025



The evaluation of discourse-level translation in expert domains remains inadequate, despite its centrality to knowledge dissemination and cross-lingual scholarly communication. While these translations demand discourse-level coherence and strict terminological precision, current evaluation methods predominantly focus on segment-level accuracy and fluency. To address this limitation, we introduce DiscoX, a new benchmark for discourse-level and expert-level Chinese-English translation. It comprises 200 professionally-curated texts from 7 domains, with an average length exceeding 1700 tokens. To evaluate performance on DiscoX, we also develop Metric-S, a reference-free system that provides fine-grained automatic assessments across accuracy, fluency, and appropriateness. Metric-S demonstrates strong consistency with human judgments, significantly outperforming existing metrics. Our experiments reveal a remarkable performance gap: even the most advanced LLMs still trail human experts on these tasks. This finding validates the difficulty of DiscoX and underscores the challenges that remain in achieving professional-grade machine translation. The proposed benchmark and evaluation system provide a robust framework for more rigorous evaluation, facilitating future advancements in LLM-based translation.
Boomda: Balanced Multi-objective Optimization for Multimodal Domain Adaptation
Nov 11, 2025Multimodal learning, while contributing to numerous success stories across various fields, faces the challenge of prohibitively expensive manual annotation. To address the scarcity of annotated data, a popular solution is unsupervised domain adaptation, which has been extensively studied in unimodal settings yet remains less explored in multimodal settings. In this paper, we investigate heterogeneous multimodal domain adaptation, where the primary challenge is the varying domain shifts of different modalities from the source to the target domain. We first introduce the information bottleneck method to learn representations for each modality independently, and then match the source and target domains in the representation space with correlation alignment. To balance the domain alignment of all modalities, we formulate the problem as a multi-objective task, aiming for a Pareto optimal solution. By exploiting the properties specific to our model, the problem can be simplified to a quadratic programming problem. Further approximation yields a closed-form solution, leading to an efficient modality-balanced multimodal domain adaptation algorithm. The proposed method features \textbf{B}alanced multi-\textbf{o}bjective \textbf{o}ptimization for \textbf{m}ultimodal \textbf{d}omain \textbf{a}daptation, termed \textbf{Boomda}. Extensive empirical results showcase the effectiveness of the proposed approach and demonstrate that Boomda outperforms the competing schemes. The code is is available at: https://github.com/sunjunaimer/Boomda.git.
LPFQA: A Long-Tail Professional Forum-based Benchmark for LLM Evaluation
Nov 09, 2025Large Language Models (LLMs) have made rapid progress in reasoning, question answering, and professional applications; however, their true capabilities remain difficult to evaluate using existing benchmarks. Current datasets often focus on simplified tasks or artificial scenarios, overlooking long-tail knowledge and the complexities of real-world applications. To bridge this gap, we propose LPFQA, a long-tail knowledge-based benchmark derived from authentic professional forums across 20 academic and industrial fields, covering 502 tasks grounded in practical expertise. LPFQA introduces four key innovations: fine-grained evaluation dimensions that target knowledge depth, reasoning, terminology comprehension, and contextual analysis; a hierarchical difficulty structure that ensures semantic clarity and unique answers; authentic professional scenario modeling with realistic user personas; and interdisciplinary knowledge integration across diverse domains. We evaluated 12 mainstream LLMs on LPFQA and observed significant performance disparities, especially in specialized reasoning tasks. LPFQA provides a robust, authentic, and discriminative benchmark for advancing LLM evaluation and guiding future model development.
FinSearchComp: Towards a Realistic, Expert-Level Evaluation of Financial Search and Reasoning
Sep 16, 2025



Search has emerged as core infrastructure for LLM-based agents and is widely viewed as critical on the path toward more general intelligence. Finance is a particularly demanding proving ground: analysts routinely conduct complex, multi-step searches over time-sensitive, domain-specific data, making it ideal for assessing both search proficiency and knowledge-grounded reasoning. Yet no existing open financial datasets evaluate data searching capability of end-to-end agents, largely because constructing realistic, complicated tasks requires deep financial expertise and time-sensitive data is hard to evaluate. We present FinSearchComp, the first fully open-source agent benchmark for realistic, open-domain financial search and reasoning. FinSearchComp comprises three tasks -- Time-Sensitive Data Fetching, Simple Historical Lookup, and Complex Historical Investigation -- closely reproduce real-world financial analyst workflows. To ensure difficulty and reliability, we engage 70 professional financial experts for annotation and implement a rigorous multi-stage quality-assurance pipeline. The benchmark includes 635 questions spanning global and Greater China markets, and we evaluate 21 models (products) on it. Grok 4 (web) tops the global subset, approaching expert-level accuracy. DouBao (web) leads on the Greater China subset. Experimental analyses show that equipping agents with web search and financial plugins substantially improves results on FinSearchComp, and the country origin of models and tools impact performance significantly.By aligning with realistic analyst tasks and providing end-to-end evaluation, FinSearchComp offers a professional, high-difficulty testbed for complex financial search and reasoning.
Inverse IFEval: Can LLMs Unlearn Stubborn Training Conventions to Follow Real Instructions?
Sep 04, 2025Large Language Models (LLMs) achieve strong performance on diverse tasks but often exhibit cognitive inertia, struggling to follow instructions that conflict with the standardized patterns learned during supervised fine-tuning (SFT). To evaluate this limitation, we propose Inverse IFEval, a benchmark that measures models Counter-intuitive Abilitytheir capacity to override training-induced biases and comply with adversarial instructions. Inverse IFEval introduces eight types of such challenges, including Question Correction, Intentional Textual Flaws, Code without Comments, and Counterfactual Answering. Using a human-in-the-loop pipeline, we construct a dataset of 1012 high-quality Chinese and English questions across 23 domains, evaluated under an optimized LLM-as-a-Judge framework. Experiments on existing leading LLMs demonstrate the necessity of our proposed Inverse IFEval benchmark. Our findings emphasize that future alignment efforts should not only pursue fluency and factual correctness but also account for adaptability under unconventional contexts. We hope that Inverse IFEval serves as both a diagnostic tool and a foundation for developing methods that mitigate cognitive inertia, reduce overfitting to narrow patterns, and ultimately enhance the instruction-following reliability of LLMs in diverse and unpredictable real-world scenarios.
UGM2N: An Unsupervised and Generalizable Mesh Movement Network via M-Uniform Loss
Aug 12, 2025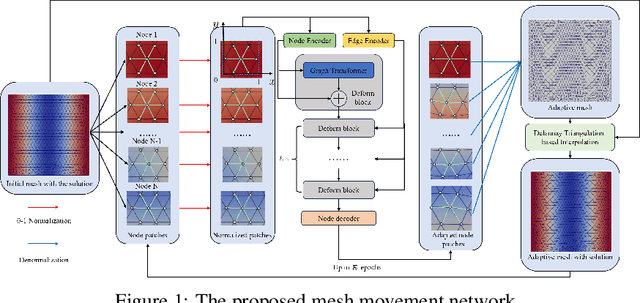
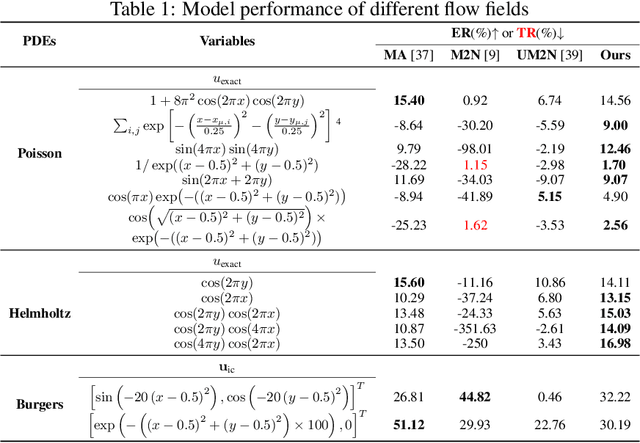
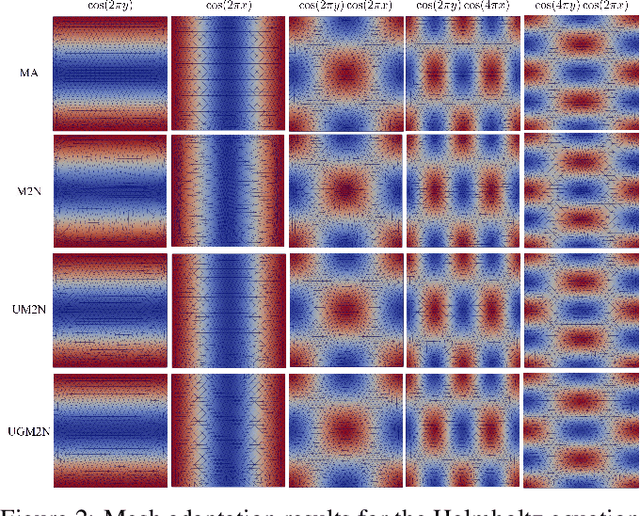
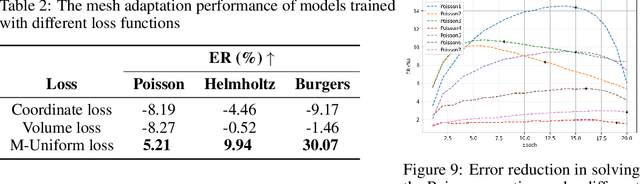
Partial differential equations (PDEs) form the mathematical foundation for modeling physical systems in science and engineering, where numerical solutions demand rigorous accuracy-efficiency tradeoffs. Mesh movement techniques address this challenge by dynamically relocating mesh nodes to rapidly-varying regions, enhancing both simulation accuracy and computational efficiency. However, traditional approaches suffer from high computational complexity and geometric inflexibility, limiting their applicability, and existing supervised learning-based approaches face challenges in zero-shot generalization across diverse PDEs and mesh topologies.In this paper, we present an Unsupervised and Generalizable Mesh Movement Network (UGM2N). We first introduce unsupervised mesh adaptation through localized geometric feature learning, eliminating the dependency on pre-adapted meshes. We then develop a physics-constrained loss function, M-Uniform loss, that enforces mesh equidistribution at the nodal level.Experimental results demonstrate that the proposed network exhibits equation-agnostic generalization and geometric independence in efficient mesh adaptation. It demonstrates consistent superiority over existing methods, including robust performance across diverse PDEs and mesh geometries, scalability to multi-scale resolutions and guaranteed error reduction without mesh tangling.