 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNL2Repo-Bench: Towards Long-Horizon Repository Generation Evaluation of Coding Agents
Dec 14, 2025Recent advances in coding agents suggest rapid progress toward autonomous software development, yet existing benchmarks fail to rigorously evaluate the long-horizon capabilities required to build complete software systems. Most prior evaluations focus on localized code generation, scaffolded completion, or short-term repair tasks, leaving open the question of whether agents can sustain coherent reasoning, planning, and execution over the extended horizons demanded by real-world repository construction. To address this gap, we present NL2Repo Bench, a benchmark explicitly designed to evaluate the long-horizon repository generation ability of coding agents. Given only a single natural-language requirements document and an empty workspace, agents must autonomously design the architecture, manage dependencies, implement multi-module logic, and produce a fully installable Python library. Our experiments across state-of-the-art open- and closed-source models reveal that long-horizon repository generation remains largely unsolved: even the strongest agents achieve below 40% average test pass rates and rarely complete an entire repository correctly. Detailed analysis uncovers fundamental long-horizon failure modes, including premature termination, loss of global coherence, fragile cross-file dependencies, and inadequate planning over hundreds of interaction steps. NL2Repo Bench establishes a rigorous, verifiable testbed for measuring sustained agentic competence and highlights long-horizon reasoning as a central bottleneck for the next generation of autonomous coding agents.
FinSearchComp: Towards a Realistic, Expert-Level Evaluation of Financial Search and Reasoning
Sep 16, 2025



Search has emerged as core infrastructure for LLM-based agents and is widely viewed as critical on the path toward more general intelligence. Finance is a particularly demanding proving ground: analysts routinely conduct complex, multi-step searches over time-sensitive, domain-specific data, making it ideal for assessing both search proficiency and knowledge-grounded reasoning. Yet no existing open financial datasets evaluate data searching capability of end-to-end agents, largely because constructing realistic, complicated tasks requires deep financial expertise and time-sensitive data is hard to evaluate. We present FinSearchComp, the first fully open-source agent benchmark for realistic, open-domain financial search and reasoning. FinSearchComp comprises three tasks -- Time-Sensitive Data Fetching, Simple Historical Lookup, and Complex Historical Investigation -- closely reproduce real-world financial analyst workflows. To ensure difficulty and reliability, we engage 70 professional financial experts for annotation and implement a rigorous multi-stage quality-assurance pipeline. The benchmark includes 635 questions spanning global and Greater China markets, and we evaluate 21 models (products) on it. Grok 4 (web) tops the global subset, approaching expert-level accuracy. DouBao (web) leads on the Greater China subset. Experimental analyses show that equipping agents with web search and financial plugins substantially improves results on FinSearchComp, and the country origin of models and tools impact performance significantly.By aligning with realistic analyst tasks and providing end-to-end evaluation, FinSearchComp offers a professional, high-difficulty testbed for complex financial search and reasoning.
Inverse IFEval: Can LLMs Unlearn Stubborn Training Conventions to Follow Real Instructions?
Sep 04, 2025Large Language Models (LLMs) achieve strong performance on diverse tasks but often exhibit cognitive inertia, struggling to follow instructions that conflict with the standardized patterns learned during supervised fine-tuning (SFT). To evaluate this limitation, we propose Inverse IFEval, a benchmark that measures models Counter-intuitive Abilitytheir capacity to override training-induced biases and comply with adversarial instructions. Inverse IFEval introduces eight types of such challenges, including Question Correction, Intentional Textual Flaws, Code without Comments, and Counterfactual Answering. Using a human-in-the-loop pipeline, we construct a dataset of 1012 high-quality Chinese and English questions across 23 domains, evaluated under an optimized LLM-as-a-Judge framework. Experiments on existing leading LLMs demonstrate the necessity of our proposed Inverse IFEval benchmark. Our findings emphasize that future alignment efforts should not only pursue fluency and factual correctness but also account for adaptability under unconventional contexts. We hope that Inverse IFEval serves as both a diagnostic tool and a foundation for developing methods that mitigate cognitive inertia, reduce overfitting to narrow patterns, and ultimately enhance the instruction-following reliability of LLMs in diverse and unpredictable real-world scenarios.
GoLF-NRT: Integrating Global Context and Local Geometry for Few-Shot View Synthesis
May 26, 2025Neural Radiance Fields (NeRF) have transformed novel view synthesis by modeling scene-specific volumetric representations directly from images. While generalizable NeRF models can generate novel views across unknown scenes by learning latent ray representations, their performance heavily depends on a large number of multi-view observations. However, with limited input views, these methods experience significant degradation in rendering quality. To address this limitation, we propose GoLF-NRT: a Global and Local feature Fusion-based Neural Rendering Transformer. GoLF-NRT enhances generalizable neural rendering from few input views by leveraging a 3D transformer with efficient sparse attention to capture global scene context. In parallel, it integrates local geometric features extracted along the epipolar line, enabling high-quality scene reconstruction from as few as 1 to 3 input views. Furthermore, we introduce an adaptive sampling strategy based on attention weights and kernel regression, improving the accuracy of transformer-based neural rendering. Extensive experiments on public datasets show that GoLF-NRT achieves state-of-the-art performance across varying numbers of input views, highlighting the effectiveness and superiority of our approach. Code is available at https://github.com/KLMAV-CUC/GoLF-NRT.
Depth-Guided Bundle Sampling for Efficient Generalizable Neural Radiance Field Reconstruction
May 26, 2025Recent advancements in generalizable novel view synthesis have achieved impressive quality through interpolation between nearby views. However, rendering high-resolution images remains computationally intensive due to the need for dense sampling of all rays. Recognizing that natural scenes are typically piecewise smooth and sampling all rays is often redundant, we propose a novel depth-guided bundle sampling strategy to accelerate rendering. By grouping adjacent rays into a bundle and sampling them collectively, a shared representation is generated for decoding all rays within the bundle. To further optimize efficiency, our adaptive sampling strategy dynamically allocates samples based on depth confidence, concentrating more samples in complex regions while reducing them in smoother areas. When applied to ENeRF, our method achieves up to a 1.27 dB PSNR improvement and a 47% increase in FPS on the DTU dataset. Extensive experiments on synthetic and real-world datasets demonstrate state-of-the-art rendering quality and up to 2x faster rendering compared to existing generalizable methods. Code is available at https://github.com/KLMAV-CUC/GDB-NeRF.
Omni6DPose: A Benchmark and Model for Universal 6D Object Pose Estimation and Tracking
Jun 06, 2024



6D Object Pose Estimation is a crucial yet challenging task in computer vision, suffering from a significant lack of large-scale datasets. This scarcity impedes comprehensive evaluation of model performance, limiting research advancements. Furthermore, the restricted number of available instances or categories curtails its applications. To address these issues, this paper introduces Omni6DPose, a substantial dataset characterized by its diversity in object categories, large scale, and variety in object materials. Omni6DPose is divided into three main components: ROPE (Real 6D Object Pose Estimation Dataset), which includes 332K images annotated with over 1.5M annotations across 581 instances in 149 categories; SOPE(Simulated 6D Object Pose Estimation Dataset), consisting of 475K images created in a mixed reality setting with depth simulation, annotated with over 5M annotations across 4162 instances in the same 149 categories; and the manually aligned real scanned objects used in both ROPE and SOPE. Omni6DPose is inherently challenging due to the substantial variations and ambiguities. To address this challenge, we introduce GenPose++, an enhanced version of the SOTA category-level pose estimation framework, incorporating two pivotal improvements: Semantic-aware feature extraction and Clustering-based aggregation. Moreover, we provide a comprehensive benchmarking analysis to evaluate the performance of previous methods on this large-scale dataset in the realms of 6D object pose estimation and pose tracking.
Vision-Based Human Pose Estimation via Deep Learning: A Survey
Aug 26, 2023



Human pose estimation (HPE) has attracted a significant amount of attention from the computer vision community in the past decades. Moreover, HPE has been applied to various domains, such as human-computer interaction, sports analysis, and human tracking via images and videos. Recently, deep learning-based approaches have shown state-of-the-art performance in HPE-based applications. Although deep learning-based approaches have achieved remarkable performance in HPE, a comprehensive review of deep learning-based HPE methods remains lacking in the literature. In this article, we provide an up-to-date and in-depth overview of the deep learning approaches in vision-based HPE. We summarize these methods of 2-D and 3-D HPE, and their applications, discuss the challenges and the research trends through bibliometrics, and provide insightful recommendations for future research. This article provides a meaningful overview as introductory material for beginners to deep learning-based HPE, as well as supplementary material for advanced researchers.
Concealed Object Detection for Passive Millimeter-Wave Security Imaging Based on Task-Aligned Detection Transformer
Dec 01, 2022Passive millimeter-wave (PMMW) is a significant potential technique for human security screening. Several popular object detection networks have been used for PMMW images. However, restricted by the low resolution and high noise of PMMW images, PMMW hidden object detection based on deep learning usually suffers from low accuracy and low classification confidence. To tackle the above problems, this paper proposes a Task-Aligned Detection Transformer network, named PMMW-DETR. In the first stage, a Denoising Coarse-to-Fine Transformer (DCFT) backbone is designed to extract long- and short-range features in the different scales. In the second stage, we propose the Query Selection module to introduce learned spatial features into the network as prior knowledge, which enhances the semantic perception capability of the network. In the third stage, aiming to improve the classification performance, we perform a Task-Aligned Dual-Head block to decouple the classification and regression tasks. Based on our self-developed PMMW security screening dataset, experimental results including comparison with State-Of-The-Art (SOTA) methods and ablation study demonstrate that the PMMW-DETR obtains higher accuracy and classification confidence than previous works, and exhibits robustness to the PMMW images of low quality.
SPCNet: Stepwise Point Cloud Completion Network
Sep 05, 2022
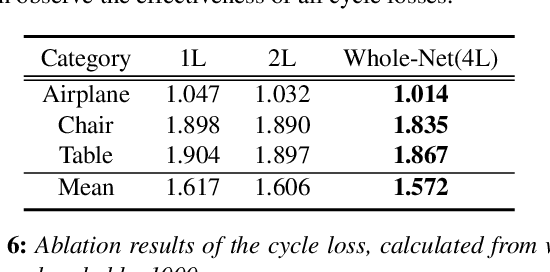
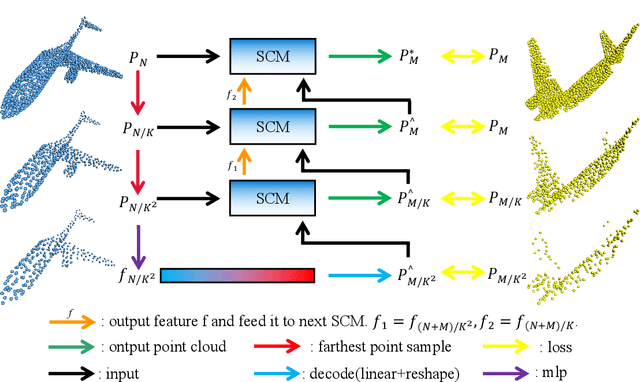
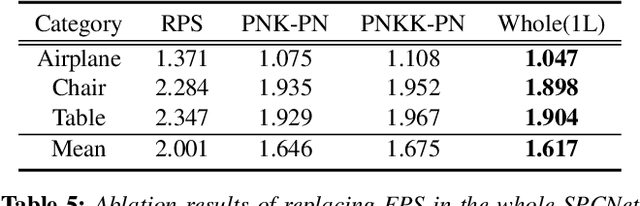
How will you repair a physical object with large missings? You may first recover its global yet coarse shape and stepwise increase its local details. We are motivated to imitate the above physical repair procedure to address the point cloud completion task. We propose a novel stepwise point cloud completion network (SPCNet) for various 3D models with large missings. SPCNet has a hierarchical bottom-to-up network architecture. It fulfills shape completion in an iterative manner, which 1) first infers the global feature of the coarse result; 2) then infers the local feature with the aid of global feature; and 3) finally infers the detailed result with the help of local feature and coarse result. Beyond the wisdom of simulating the physical repair, we newly design a cycle loss %based training strategy to enhance the generalization and robustness of SPCNet. Extensive experiments clearly show the superiority of our SPCNet over the state-of-the-art methods on 3D point clouds with large missings.
AGConv: Adaptive Graph Convolution on 3D Point Clouds
Jun 09, 2022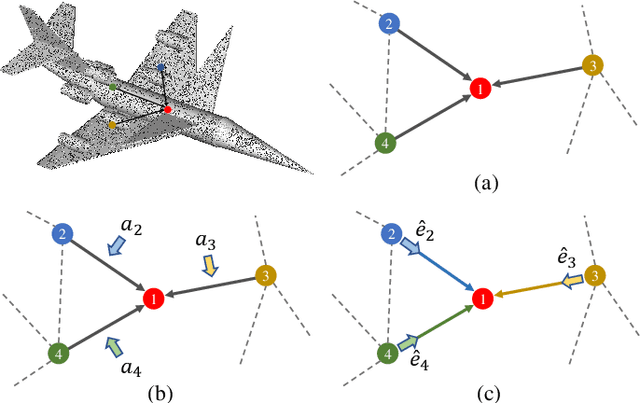
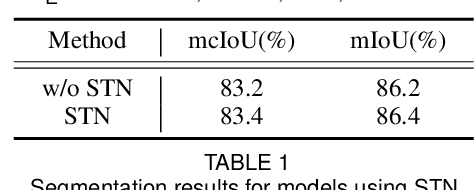

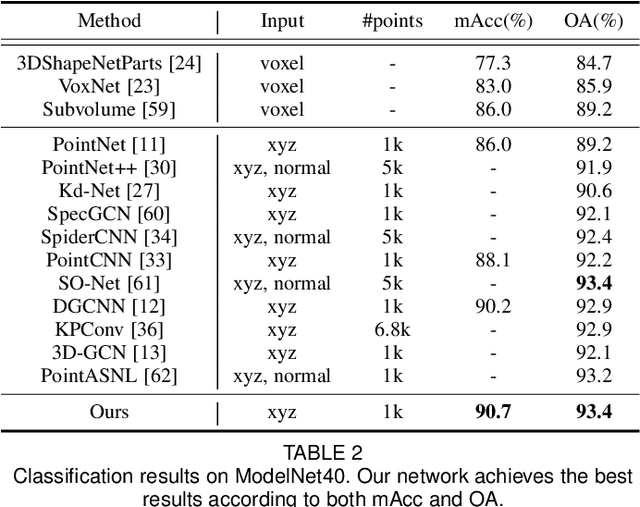
Convolution on 3D point clouds is widely researched yet far from perfect in geometric deep learning. The traditional wisdom of convolution characterises feature correspondences indistinguishably among 3D points, arising an intrinsic limitation of poor distinctive feature learning. In this paper, we propose Adaptive Graph Convolution (AGConv) for wide applications of point cloud analysis. AGConv generates adaptive kernels for points according to their dynamically learned features. Compared with the solution of using fixed/isotropic kernels, AGConv improves the flexibility of point cloud convolutions, effectively and precisely capturing the diverse relations between points from different semantic parts. Unlike the popular attentional weight schemes, AGConv implements the adaptiveness inside the convolution operation instead of simply assigning different weights to the neighboring points. Extensive evaluations clearly show that our method outperforms state-of-the-arts of point cloud classification and segmentation on various benchmark datasets.Meanwhile, AGConv can flexibly serve more point cloud analysis approaches to boost their performance. To validate its flexibility and effectiveness, we explore AGConv-based paradigms of completion, denoising, upsampling, registration and circle extraction, which are comparable or even superior to their competitors. Our code is available at https://github.com/hrzhou2/AdaptConv-master.