 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMobile-Agent-V: Learning Mobile Device Operation Through Video-Guided Multi-Agent Collaboration
Feb 25, 2025



The rapid increase in mobile device usage necessitates improved automation for seamless task management. However, many AI-driven frameworks struggle due to insufficient operational knowledge. Manually written knowledge helps but is labor-intensive and inefficient. To address these challenges, we introduce Mobile-Agent-V, a framework that leverages video guidance to provide rich and cost-effective operational knowledge for mobile automation. Mobile-Agent-V enhances task execution capabilities by leveraging video inputs without requiring specialized sampling or preprocessing. Mobile-Agent-V integrates a sliding window strategy and incorporates a video agent and deep-reflection agent to ensure that actions align with user instructions. Through this innovative approach, users can record task processes with guidance, enabling the system to autonomously learn and execute tasks efficiently. Experimental results show that Mobile-Agent-V achieves a 30% performance improvement compared to existing frameworks. The code will be open-sourced at https://github.com/X-PLUG/MobileAgent.
PC-Agent: A Hierarchical Multi-Agent Collaboration Framework for Complex Task Automation on PC
Feb 21, 2025In the field of MLLM-based GUI agents, compared to smartphones, the PC scenario not only features a more complex interactive environment, but also involves more intricate intra- and inter-app workflows. To address these issues, we propose a hierarchical agent framework named PC-Agent. Specifically, from the perception perspective, we devise an Active Perception Module (APM) to overcome the inadequate abilities of current MLLMs in perceiving screenshot content. From the decision-making perspective, to handle complex user instructions and interdependent subtasks more effectively, we propose a hierarchical multi-agent collaboration architecture that decomposes decision-making processes into Instruction-Subtask-Action levels. Within this architecture, three agents (i.e., Manager, Progress and Decision) are set up for instruction decomposition, progress tracking and step-by-step decision-making respectively. Additionally, a Reflection agent is adopted to enable timely bottom-up error feedback and adjustment. We also introduce a new benchmark PC-Eval with 25 real-world complex instructions. Empirical results on PC-Eval show that our PC-Agent achieves a 32% absolute improvement of task success rate over previous state-of-the-art methods. The code is available at https://github.com/X-PLUG/MobileAgent/tree/main/PC-Agent.
Qwen2.5-VL Technical Report
Feb 19, 2025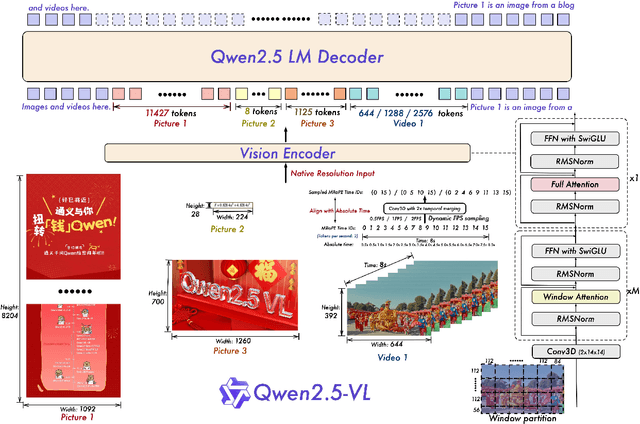
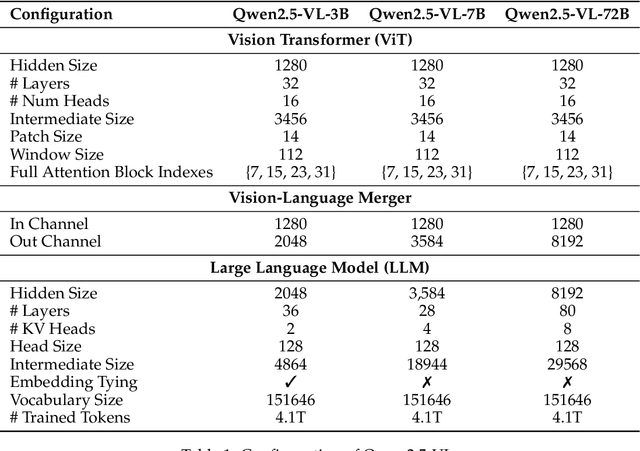
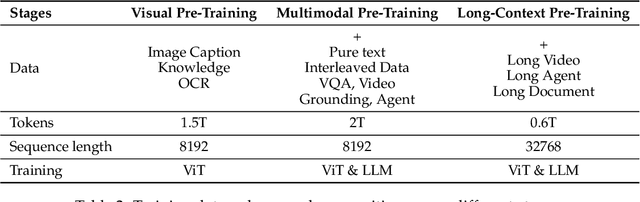
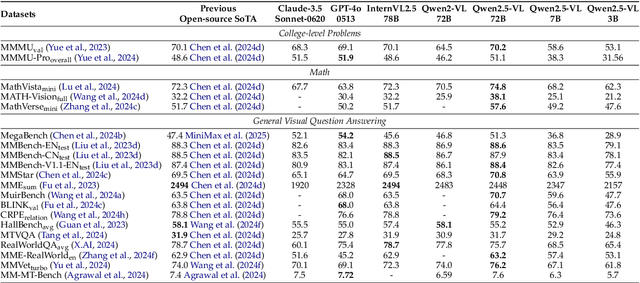
We introduce Qwen2.5-VL, the latest flagship model of Qwen vision-language series, which demonstrates significant advancements in both foundational capabilities and innovative functionalities. Qwen2.5-VL achieves a major leap forward in understanding and interacting with the world through enhanced visual recognition, precise object localization, robust document parsing, and long-video comprehension. A standout feature of Qwen2.5-VL is its ability to localize objects using bounding boxes or points accurately. It provides robust structured data extraction from invoices, forms, and tables, as well as detailed analysis of charts, diagrams, and layouts. To handle complex inputs, Qwen2.5-VL introduces dynamic resolution processing and absolute time encoding, enabling it to process images of varying sizes and videos of extended durations (up to hours) with second-level event localization. This allows the model to natively perceive spatial scales and temporal dynamics without relying on traditional normalization techniques. By training a native dynamic-resolution Vision Transformer (ViT) from scratch and incorporating Window Attention, we reduce computational overhead while maintaining native resolution. As a result, Qwen2.5-VL excels not only in static image and document understanding but also as an interactive visual agent capable of reasoning, tool usage, and task execution in real-world scenarios such as operating computers and mobile devices. Qwen2.5-VL is available in three sizes, addressing diverse use cases from edge AI to high-performance computing. The flagship Qwen2.5-VL-72B model matches state-of-the-art models like GPT-4o and Claude 3.5 Sonnet, particularly excelling in document and diagram understanding. Additionally, Qwen2.5-VL maintains robust linguistic performance, preserving the core language competencies of the Qwen2.5 LLM.
SCCD: A Session-based Dataset for Chinese Cyberbullying Detection
Jan 25, 2025



The rampant spread of cyberbullying content poses a growing threat to societal well-being. However, research on cyberbullying detection in Chinese remains underdeveloped, primarily due to the lack of comprehensive and reliable datasets. Notably, no existing Chinese dataset is specifically tailored for cyberbullying detection. Moreover, while comments play a crucial role within sessions, current session-based datasets often lack detailed, fine-grained annotations at the comment level. To address these limitations, we present a novel Chinese cyber-bullying dataset, termed SCCD, which consists of 677 session-level samples sourced from a major social media platform Weibo. Moreover, each comment within the sessions is annotated with fine-grained labels rather than conventional binary class labels. Empirically, we evaluate the performance of various baseline methods on SCCD, highlighting the challenges for effective Chinese cyberbullying detection.
Mobile-Agent-E: Self-Evolving Mobile Assistant for Complex Tasks
Jan 20, 2025



Smartphones have become indispensable in modern life, yet navigating complex tasks on mobile devices often remains frustrating. Recent advancements in large multimodal model (LMM)-based mobile agents have demonstrated the ability to perceive and act in mobile environments. However, current approaches face significant limitations: they fall short in addressing real-world human needs, struggle with reasoning-intensive and long-horizon tasks, and lack mechanisms to learn and improve from prior experiences. To overcome these challenges, we introduce Mobile-Agent-E, a hierarchical multi-agent framework capable of self-evolution through past experience. By hierarchical, we mean an explicit separation of high-level planning and low-level action execution. The framework comprises a Manager, responsible for devising overall plans by breaking down complex tasks into subgoals, and four subordinate agents--Perceptor, Operator, Action Reflector, and Notetaker--which handle fine-grained visual perception, immediate action execution, error verification, and information aggregation, respectively. Mobile-Agent-E also features a novel self-evolution module which maintains a persistent long-term memory comprising Tips and Shortcuts. Tips are general guidance and lessons learned from prior tasks on how to effectively interact with the environment. Shortcuts are reusable, executable sequences of atomic operations tailored for specific subroutines. The inclusion of Tips and Shortcuts facilitates continuous refinement in performance and efficiency. Alongside this framework, we introduce Mobile-Eval-E, a new benchmark featuring complex mobile tasks requiring long-horizon, multi-app interactions. Empirical results show that Mobile-Agent-E achieves a 22% absolute improvement over previous state-of-the-art approaches across three foundation model backbones. Project page: https://x-plug.github.io/MobileAgent.
Gla-AI4BioMed at RRG24: Visual Instruction-tuned Adaptation for Radiology Report Generation
Dec 06, 2024



We introduce a radiology-focused visual language model designed to generate radiology reports from chest X-rays. Building on previous findings that large language models (LLMs) can acquire multimodal capabilities when aligned with pretrained vision encoders, we demonstrate similar potential with chest X-ray images. This integration enhances the ability of model to understand and describe chest X-ray images. Our model combines an image encoder with a fine-tuned LLM based on the Vicuna-7B architecture, enabling it to generate different sections of a radiology report with notable accuracy. The training process involves a two-stage approach: (i) initial alignment of chest X-ray features with the LLM (ii) followed by fine-tuning for radiology report generation.
TSUBF-Net: Trans-Spatial UNet-like Network with Bi-direction Fusion for Segmentation of Adenoid Hypertrophy in CT
Dec 01, 2024Adenoid hypertrophy stands as a common cause of obstructive sleep apnea-hypopnea syndrome in children. It is characterized by snoring, nasal congestion, and growth disorders. Computed Tomography (CT) emerges as a pivotal medical imaging modality, utilizing X-rays and advanced computational techniques to generate detailed cross-sectional images. Within the realm of pediatric airway assessments, CT imaging provides an insightful perspective on the shape and volume of enlarged adenoids. Despite the advances of deep learning methods for medical imaging analysis, there remains an emptiness in the segmentation of adenoid hypertrophy in CT scans. To address this research gap, we introduce TSUBF-Nett (Trans-Spatial UNet-like Network based on Bi-direction Fusion), a 3D medical image segmentation framework. TSUBF-Net is engineered to effectively discern intricate 3D spatial interlayer features in CT scans and enhance the extraction of boundary-blurring features. Notably, we propose two innovative modules within the U-shaped network architecture:the Trans-Spatial Perception module (TSP) and the Bi-directional Sampling Collaborated Fusion module (BSCF).These two modules are in charge of operating during the sampling process and strategically fusing down-sampled and up-sampled features, respectively. Furthermore, we introduce the Sobel loss term, which optimizes the smoothness of the segmentation results and enhances model accuracy. Extensive 3D segmentation experiments are conducted on several datasets. TSUBF-Net is superior to the state-of-the-art methods with the lowest HD95: 7.03, IoU:85.63, and DSC: 92.26 on our own AHSD dataset. The results in the other two public datasets also demonstrate that our methods can robustly and effectively address the challenges of 3D segmentation in CT scans.
Libra: Leveraging Temporal Images for Biomedical Radiology Analysis
Nov 28, 2024



Radiology report generation (RRG) is a challenging task, as it requires a thorough understanding of medical images, integration of multiple temporal inputs, and accurate report generation. Effective interpretation of medical images, such as chest X-rays (CXRs), demands sophisticated visual-language reasoning to map visual findings to structured reports. Recent studies have shown that multimodal large language models (MLLMs) can acquire multimodal capabilities by aligning with pre-trained vision encoders. However, current approaches predominantly focus on single-image analysis or utilise rule-based symbolic processing to handle multiple images, thereby overlooking the essential temporal information derived from comparing current images with prior ones. To overcome this critical limitation, we introduce Libra, a temporal-aware MLLM tailored for CXR report generation using temporal images. Libra integrates a radiology-specific image encoder with a MLLM and utilises a novel Temporal Alignment Connector to capture and synthesise temporal information of images across different time points with unprecedented precision. Extensive experiments show that Libra achieves new state-of-the-art performance among the same parameter scale MLLMs for RRG tasks on the MIMIC-CXR. Specifically, Libra improves the RadCliQ metric by 12.9% and makes substantial gains across all lexical metrics compared to previous models.
Learning Optimal Lattice Vector Quantizers for End-to-end Neural Image Compression
Nov 25, 2024It is customary to deploy uniform scalar quantization in the end-to-end optimized Neural image compression methods, instead of more powerful vector quantization, due to the high complexity of the latter. Lattice vector quantization (LVQ), on the other hand, presents a compelling alternative, which can exploit inter-feature dependencies more effectively while keeping computational efficiency almost the same as scalar quantization. However, traditional LVQ structures are designed/optimized for uniform source distributions, hence nonadaptive and suboptimal for real source distributions of latent code space for Neural image compression tasks. In this paper, we propose a novel learning method to overcome this weakness by designing the rate-distortion optimal lattice vector quantization (OLVQ) codebooks with respect to the sample statistics of the latent features to be compressed. By being able to better fit the LVQ structures to any given latent sample distribution, the proposed OLVQ method improves the rate-distortion performances of the existing quantization schemes in neural image compression significantly, while retaining the amenability of uniform scalar quantization.
Trajectory Flow Matching with Applications to Clinical Time Series Modeling
Oct 28, 2024Modeling stochastic and irregularly sampled time series is a challenging problem found in a wide range of applications, especially in medicine. Neural stochastic differential equations (Neural SDEs) are an attractive modeling technique for this problem, which parameterize the drift and diffusion terms of an SDE with neural networks. However, current algorithms for training Neural SDEs require backpropagation through the SDE dynamics, greatly limiting their scalability and stability. To address this, we propose Trajectory Flow Matching (TFM), which trains a Neural SDE in a simulation-free manner, bypassing backpropagation through the dynamics. TFM leverages the flow matching technique from generative modeling to model time series. In this work we first establish necessary conditions for TFM to learn time series data. Next, we present a reparameterization trick which improves training stability. Finally, we adapt TFM to the clinical time series setting, demonstrating improved performance on three clinical time series datasets both in terms of absolute performance and uncertainty prediction.