 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaking MLLMs Blind: Adversarial Smuggling Attacks in MLLM Content Moderation
Apr 09, 2026Multimodal Large Language Models (MLLMs) are increasingly being deployed as automated content moderators. Within this landscape, we uncover a critical threat: Adversarial Smuggling Attacks. Unlike adversarial perturbations (for misclassification) and adversarial jailbreaks (for harmful output generation), adversarial smuggling exploits the Human-AI capability gap. It encodes harmful content into human-readable visual formats that remain AI-unreadable, thereby evading automated detection and enabling the dissemination of harmful content. We classify smuggling attacks into two pathways: (1) Perceptual Blindness, disrupting text recognition; and (2) Reasoning Blockade, inhibiting semantic understanding despite successful text recognition. To evaluate this threat, we constructed SmuggleBench, the first comprehensive benchmark comprising 1,700 adversarial smuggling attack instances. Evaluations on SmuggleBench reveal that both proprietary (e.g., GPT-5) and open-source (e.g., Qwen3-VL) state-of-the-art models are vulnerable to this threat, producing Attack Success Rates (ASR) exceeding 90%. By analyzing the vulnerability through the lenses of perception and reasoning, we identify three root causes: the limited capabilities of vision encoders, the robustness gap in OCR, and the scarcity of domain-specific adversarial examples. We conduct a preliminary exploration of mitigation strategies, investigating the potential of test-time scaling (via CoT) and adversarial training (via SFT) to mitigate this threat. Our code is publicly available at https://github.com/zhihengli-casia/smugglebench.
Beyond Semantic Search: Towards Referential Anchoring in Composed Image Retrieval
Apr 07, 2026Composed Image Retrieval (CIR) has demonstrated significant potential by enabling flexible multimodal queries that combine a reference image and modification text. However, CIR inherently prioritizes semantic matching, struggling to reliably retrieve a user-specified instance across contexts. In practice, emphasizing concrete instance fidelity over broad semantics is often more consequential. In this work, we propose Object-Anchored Composed Image Retrieval (OACIR), a novel fine-grained retrieval task that mandates strict instance-level consistency. To advance research on this task, we construct OACIRR (OACIR on Real-world images), the first large-scale, multi-domain benchmark comprising over 160K quadruples and four challenging candidate galleries enriched with hard-negative instance distractors. Each quadruple augments the compositional query with a bounding box that visually anchors the object in the reference image, providing a precise and flexible way to ensure instance preservation. To address the OACIR task, we propose AdaFocal, a framework featuring a Context-Aware Attention Modulator that adaptively intensifies attention within the specified instance region, dynamically balancing focus between the anchored instance and the broader compositional context. Extensive experiments demonstrate that AdaFocal substantially outperforms existing compositional retrieval models, particularly in maintaining instance-level fidelity, thereby establishing a robust baseline for this challenging task while opening new directions for more flexible, instance-aware retrieval systems.
MMhops-R1: Multimodal Multi-hop Reasoning
Dec 16, 2025


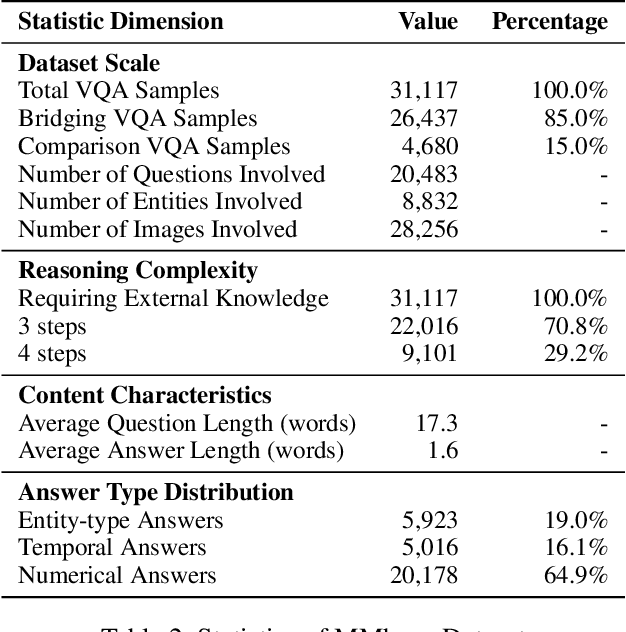
The ability to perform multi-modal multi-hop reasoning by iteratively integrating information across various modalities and external knowledge is critical for addressing complex real-world challenges. However, existing Multi-modal Large Language Models (MLLMs) are predominantly limited to single-step reasoning, as existing benchmarks lack the complexity needed to evaluate and drive multi-hop abilities. To bridge this gap, we introduce MMhops, a novel, large-scale benchmark designed to systematically evaluate and foster multi-modal multi-hop reasoning. MMhops dataset comprises two challenging task formats, Bridging and Comparison, which necessitate that models dynamically construct complex reasoning chains by integrating external knowledge. To tackle the challenges posed by MMhops, we propose MMhops-R1, a novel multi-modal Retrieval-Augmented Generation (mRAG) framework for dynamic reasoning. Our framework utilizes reinforcement learning to optimize the model for autonomously planning reasoning paths, formulating targeted queries, and synthesizing multi-level information. Comprehensive experiments demonstrate that MMhops-R1 significantly outperforms strong baselines on MMhops, highlighting that dynamic planning and multi-modal knowledge integration are crucial for complex reasoning. Moreover, MMhops-R1 demonstrates strong generalization to tasks requiring fixed-hop reasoning, underscoring the robustness of our dynamic planning approach. In conclusion, our work contributes a challenging new benchmark and a powerful baseline model, and we will release the associated code, data, and weights to catalyze future research in this critical area.
BOASF: A Unified Framework for Speeding up Automatic Machine Learning via Adaptive Successive Filtering
Jul 28, 2025Machine learning has been making great success in many application areas. However, for the non-expert practitioners, it is always very challenging to address a machine learning task successfully and efficiently. Finding the optimal machine learning model or the hyperparameter combination set from a large number of possible alternatives usually requires considerable expert knowledge and experience. To tackle this problem, we propose a combined Bayesian Optimization and Adaptive Successive Filtering algorithm (BOASF) under a unified multi-armed bandit framework to automate the model selection or the hyperparameter optimization. Specifically, BOASF consists of multiple evaluation rounds in each of which we select promising configurations for each arm using the Bayesian optimization. Then, ASF can early discard the poor-performed arms adaptively using a Gaussian UCB-based probabilistic model. Furthermore, a Softmax model is employed to adaptively allocate available resources for each promising arm that advances to the next round. The arm with a higher probability of advancing will be allocated more resources. Experimental results show that BOASF is effective for speeding up the model selection and hyperparameter optimization processes while achieving robust and better prediction performance than the existing state-of-the-art automatic machine learning methods. Moreover, BOASF achieves better anytime performance under various time budgets.
DetailFusion: A Dual-branch Framework with Detail Enhancement for Composed Image Retrieval
May 23, 2025Composed Image Retrieval (CIR) aims to retrieve target images from a gallery based on a reference image and modification text as a combined query. Recent approaches focus on balancing global information from two modalities and encode the query into a unified feature for retrieval. However, due to insufficient attention to fine-grained details, these coarse fusion methods often struggle with handling subtle visual alterations or intricate textual instructions. In this work, we propose DetailFusion, a novel dual-branch framework that effectively coordinates information across global and detailed granularities, thereby enabling detail-enhanced CIR. Our approach leverages atomic detail variation priors derived from an image editing dataset, supplemented by a detail-oriented optimization strategy to develop a Detail-oriented Inference Branch. Furthermore, we design an Adaptive Feature Compositor that dynamically fuses global and detailed features based on fine-grained information of each unique multimodal query. Extensive experiments and ablation analyses not only demonstrate that our method achieves state-of-the-art performance on both CIRR and FashionIQ datasets but also validate the effectiveness and cross-domain adaptability of detail enhancement for CIR.
PC-Agent: A Hierarchical Multi-Agent Collaboration Framework for Complex Task Automation on PC
Feb 21, 2025In the field of MLLM-based GUI agents, compared to smartphones, the PC scenario not only features a more complex interactive environment, but also involves more intricate intra- and inter-app workflows. To address these issues, we propose a hierarchical agent framework named PC-Agent. Specifically, from the perception perspective, we devise an Active Perception Module (APM) to overcome the inadequate abilities of current MLLMs in perceiving screenshot content. From the decision-making perspective, to handle complex user instructions and interdependent subtasks more effectively, we propose a hierarchical multi-agent collaboration architecture that decomposes decision-making processes into Instruction-Subtask-Action levels. Within this architecture, three agents (i.e., Manager, Progress and Decision) are set up for instruction decomposition, progress tracking and step-by-step decision-making respectively. Additionally, a Reflection agent is adopted to enable timely bottom-up error feedback and adjustment. We also introduce a new benchmark PC-Eval with 25 real-world complex instructions. Empirical results on PC-Eval show that our PC-Agent achieves a 32% absolute improvement of task success rate over previous state-of-the-art methods. The code is available at https://github.com/X-PLUG/MobileAgent/tree/main/PC-Agent.
SA-GNAS: Seed Architecture Expansion for Efficient Large-scale Graph Neural Architecture Search
Dec 03, 2024



GNAS (Graph Neural Architecture Search) has demonstrated great effectiveness in automatically designing the optimal graph neural architectures for multiple downstream tasks, such as node classification and link prediction. However, most existing GNAS methods cannot efficiently handle large-scale graphs containing more than million-scale nodes and edges due to the expensive computational and memory overhead. To scale GNAS on large graphs while achieving better performance, we propose SA-GNAS, a novel framework based on seed architecture expansion for efficient large-scale GNAS. Similar to the cell expansion in biotechnology, we first construct a seed architecture and then expand the seed architecture iteratively. Specifically, we first propose a performance ranking consistency-based seed architecture selection method, which selects the architecture searched on the subgraph that best matches the original large-scale graph. Then, we propose an entropy minimization-based seed architecture expansion method to further improve the performance of the seed architecture. Extensive experimental results on five large-scale graphs demonstrate that the proposed SA-GNAS outperforms human-designed state-of-the-art GNN architectures and existing graph NAS methods. Moreover, SA-GNAS can significantly reduce the search time, showing better search efficiency. For the largest graph with billion edges, SA-GNAS can achieve 2.8 times speedup compared to the SOTA large-scale GNAS method GAUSS. Additionally, since SA-GNAS is inherently parallelized, the search efficiency can be further improved with more GPUs. SA-GNAS is available at https://github.com/PasaLab/SAGNAS.
mR$^2$AG: Multimodal Retrieval-Reflection-Augmented Generation for Knowledge-Based VQA
Nov 22, 2024



Advanced Multimodal Large Language Models (MLLMs) struggle with recent Knowledge-based VQA tasks, such as INFOSEEK and Encyclopedic-VQA, due to their limited and frozen knowledge scope, often leading to ambiguous and inaccurate responses. Thus, multimodal Retrieval-Augmented Generation (mRAG) is naturally introduced to provide MLLMs with comprehensive and up-to-date knowledge, effectively expanding the knowledge scope. However, current mRAG methods have inherent drawbacks, including: 1) Performing retrieval even when external knowledge is not needed. 2) Lacking of identification of evidence that supports the query. 3) Increasing model complexity due to additional information filtering modules or rules. To address these shortcomings, we propose a novel generalized framework called \textbf{m}ultimodal \textbf{R}etrieval-\textbf{R}eflection-\textbf{A}ugmented \textbf{G}eneration (mR$^2$AG), which achieves adaptive retrieval and useful information localization to enable answers through two easy-to-implement reflection operations, preventing high model complexity. In mR$^2$AG, Retrieval-Reflection is designed to distinguish different user queries and avoids redundant retrieval calls, and Relevance-Reflection is introduced to guide the MLLM in locating beneficial evidence of the retrieved content and generating answers accordingly. In addition, mR$^2$AG can be integrated into any well-trained MLLM with efficient fine-tuning on the proposed mR$^2$AG Instruction-Tuning dataset (mR$^2$AG-IT). mR$^2$AG significantly outperforms state-of-the-art MLLMs (e.g., GPT-4v/o) and RAG-based MLLMs on INFOSEEK and Encyclopedic-VQA, while maintaining the exceptional capabilities of base MLLMs across a wide range of Visual-dependent tasks.
SEAGULL: No-reference Image Quality Assessment for Regions of Interest via Vision-Language Instruction Tuning
Nov 15, 2024



Existing Image Quality Assessment (IQA) methods achieve remarkable success in analyzing quality for overall image, but few works explore quality analysis for Regions of Interest (ROIs). The quality analysis of ROIs can provide fine-grained guidance for image quality improvement and is crucial for scenarios focusing on region-level quality. This paper proposes a novel network, SEAGULL, which can SEe and Assess ROIs quality with GUidance from a Large vision-Language model. SEAGULL incorporates a vision-language model (VLM), masks generated by Segment Anything Model (SAM) to specify ROIs, and a meticulously designed Mask-based Feature Extractor (MFE) to extract global and local tokens for specified ROIs, enabling accurate fine-grained IQA for ROIs. Moreover, this paper constructs two ROI-based IQA datasets, SEAGULL-100w and SEAGULL-3k, for training and evaluating ROI-based IQA. SEAGULL-100w comprises about 100w synthetic distortion images with 33 million ROIs for pre-training to improve the model's ability of regional quality perception, and SEAGULL-3k contains about 3k authentic distortion ROIs to enhance the model's ability to perceive real world distortions. After pre-training on SEAGULL-100w and fine-tuning on SEAGULL-3k, SEAGULL shows remarkable performance on fine-grained ROI quality assessment. Code and datasets are publicly available at the https://github.com/chencn2020/Seagull.
Granularity Matters in Long-Tail Learning
Oct 21, 2024



Balancing training on long-tail data distributions remains a long-standing challenge in deep learning. While methods such as re-weighting and re-sampling help alleviate the imbalance issue, limited sample diversity continues to hinder models from learning robust and generalizable feature representations, particularly for tail classes. In contrast to existing methods, we offer a novel perspective on long-tail learning, inspired by an observation: datasets with finer granularity tend to be less affected by data imbalance. In this paper, we investigate this phenomenon through both quantitative and qualitative studies, showing that increased granularity enhances the generalization of learned features in tail categories. Motivated by these findings, we propose a method to increase dataset granularity through category extrapolation. Specifically, we introduce open-set auxiliary classes that are visually similar to existing ones, aiming to enhance representation learning for both head and tail classes. This forms the core contribution and insight of our approach. To automate the curation of auxiliary data, we leverage large language models (LLMs) as knowledge bases to search for auxiliary categories and retrieve relevant images through web crawling. To prevent the overwhelming presence of auxiliary classes from disrupting training, we introduce a neighbor-silencing loss that encourages the model to focus on class discrimination within the target dataset. During inference, the classifier weights for auxiliary categories are masked out, leaving only the target class weights for use. Extensive experiments and ablation studies on three standard long-tail benchmarks demonstrate the effectiveness of our approach, notably outperforming strong baseline methods that use the same amount of data. The code will be made publicly available.