 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Entity Alignment: Towards Complete Knowledge Graph Alignment via Entity-Relation Synergy
Jul 25, 2024



Knowledge Graph Alignment (KGA) aims to integrate knowledge from multiple sources to address the limitations of individual Knowledge Graphs (KGs) in terms of coverage and depth. However, current KGA models fall short in achieving a ``complete'' knowledge graph alignment. Existing models primarily emphasize the linkage of cross-graph entities but overlook aligning relations across KGs, thereby providing only a partial solution to KGA. The semantic correlations embedded in relations are largely overlooked, potentially restricting a comprehensive understanding of cross-KG signals. In this paper, we propose to conceptualize relation alignment as an independent task and conduct KGA by decomposing it into two distinct but highly correlated sub-tasks: entity alignment and relation alignment. To capture the mutually reinforcing correlations between these objectives, we propose a novel Expectation-Maximization-based model, EREM, which iteratively optimizes both sub-tasks. Experimental results on real-world datasets demonstrate that EREM consistently outperforms state-of-the-art models in both entity alignment and relation alignment tasks.
Dimension Independent Mixup for Hard Negative Sample in Collaborative Filtering
Jun 28, 2023



Collaborative filtering (CF) is a widely employed technique that predicts user preferences based on past interactions. Negative sampling plays a vital role in training CF-based models with implicit feedback. In this paper, we propose a novel perspective based on the sampling area to revisit existing sampling methods. We point out that current sampling methods mainly focus on Point-wise or Line-wise sampling, lacking flexibility and leaving a significant portion of the hard sampling area un-explored. To address this limitation, we propose Dimension Independent Mixup for Hard Negative Sampling (DINS), which is the first Area-wise sampling method for training CF-based models. DINS comprises three modules: Hard Boundary Definition, Dimension Independent Mixup, and Multi-hop Pooling. Experiments with real-world datasets on both matrix factorization and graph-based models demonstrate that DINS outperforms other negative sampling methods, establishing its effectiveness and superiority. Our work contributes a new perspective, introduces Area-wise sampling, and presents DINS as a novel approach that achieves state-of-the-art performance for negative sampling. Our implementations are available in PyTorch.
MetaKRec: Collaborative Meta-Knowledge Enhanced Recommender System
Nov 14, 2022Knowledge graph (KG) enhanced recommendation has demonstrated improved performance in the recommendation system (RecSys) and attracted considerable research interest. Recently the literature has adopted neural graph networks (GNNs) on the collaborative knowledge graph and built an end-to-end KG-enhanced RecSys. However, the majority of these approaches have three limitations: (1) treat the collaborative knowledge graph as a homogeneous graph and overlook the highly heterogeneous relationships among items, (2) lack of design to explicitly leverage the rich side information, and (3) overlook the rich knowledge in user preference. To fill this gap, in this paper, we explore the rich, heterogeneous relationship among items and propose a new KG-enhanced recommendation model called Collaborative Meta-Knowledge Enhanced Recommender System (MetaKRec). In particular, we focus on modeling the rich, heterogeneous semantic relationships among items and construct several collaborative Meta-KGs to explicitly depict the relatedness of the items under the guidance of meta-knowledge. In addition to the knowledge obtained from KG, we leverage user knowledge that extracts from user preference to construct the Meta-KGs. The constructed Meta-KGs can capture the knowledge from both the knowledge graph and user preference. Furthermore. we utilize a light convolution encoder to recursively integrate the item relationship in each collaborative Meta-KGs. This scheme allows us to explicitly gather the heterogeneous semantic relationships among items and encode them into the representations of items. In addition, we propose channel attention to fuse the item and user representations from different Meta-KGs. Extensive experiments are conducted on four real-world benchmark datasets, demonstrating significant gains over the state-of-the-art baselines on both regular and cold-start recommendation settings.
Reinforced MOOCs Concept Recommendation in Heterogeneous Information Networks
Apr 13, 2022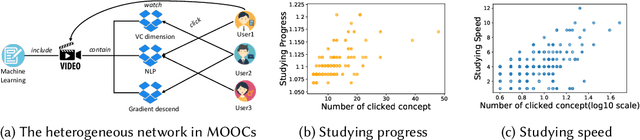

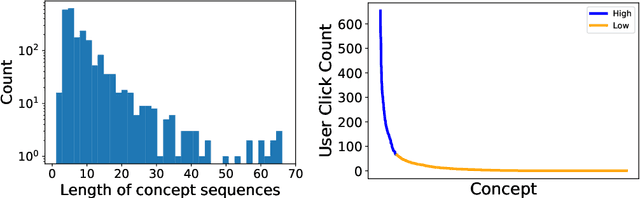
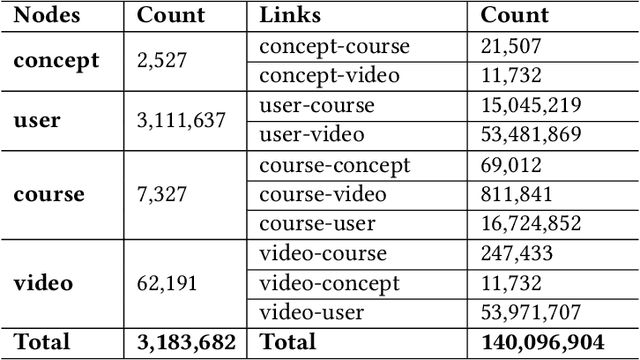
Massive open online courses (MOOCs), which provide a large-scale interactive participation and open access via the web, are becoming a modish way for online and distance education. To help users have a better study experience, many MOOC platforms have provided the services of recommending courses to users. However, we argue that directly recommending a course to users will ignore the expertise levels of different users. To fill this gap, this paper studies the problem of concept recommendation in a more fine-grained view. We propose a novel Heterogeneous Information Networks based Concept Recommender with Reinforcement Learning (HinCRec-RL) incorporated for concept recommendation in MOOCs. Specifically, we first formulate the concept recommendation in MOOCs as a reinforcement learning problem to better model the dynamic interaction among users and knowledge concepts. In addition, to mitigate the data sparsity issue which also exists in many other recommendation tasks, we consider a heterogeneous information network (HIN) among users, courses, videos and concepts, to better learn the semantic representation of users. In particular, we use the meta-paths on HIN to guide the propagation of users' preferences and propose a heterogeneous graph attention network to represent the meta-paths. To validate the effectiveness of our proposed approach, we conduct comprehensive experiments on a real-world dataset from XuetangX, a popular MOOC platform from China. The promising results show that our proposed approach can outperform other baselines.
Attentional Graph Convolutional Networks for Knowledge Concept Recommendation in MOOCs in a Heterogeneous View
Jun 23, 2020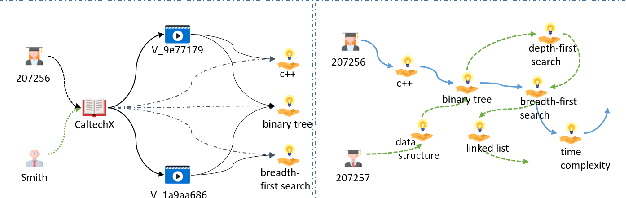
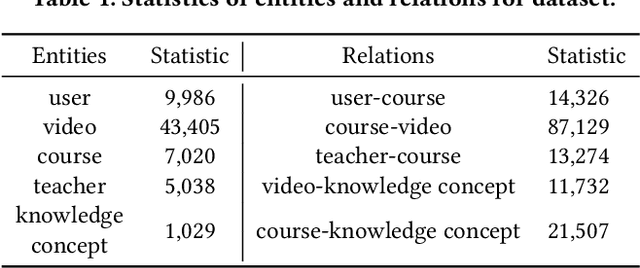
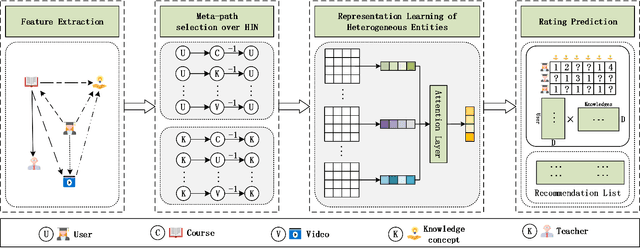
Massive open online courses are becoming a modish way for education, which provides a large-scale and open-access learning opportunity for students to grasp the knowledge. To attract students' interest, the recommendation system is applied by MOOCs providers to recommend courses to students. However, as a course usually consists of a number of video lectures, with each one covering some specific knowledge concepts, directly recommending courses overlook students'interest to some specific knowledge concepts. To fill this gap, in this paper, we study the problem of knowledge concept recommendation. We propose an end-to-end graph neural network-based approach calledAttentionalHeterogeneous Graph Convolutional Deep Knowledge Recommender(ACKRec) for knowledge concept recommendation in MOOCs. Like other recommendation problems, it suffers from sparsity issues. To address this issue, we leverage both content information and context information to learn the representation of entities via graph convolution network. In addition to students and knowledge concepts, we consider other types of entities (e.g., courses, videos, teachers) and construct a heterogeneous information network to capture the corresponding fruitful semantic relationships among different types of entities and incorporate them into the representation learning process. Specifically, we use meta-path on the HIN to guide the propagation of students' preferences. With the help of these meta-paths, the students' preference distribution with respect to a candidate knowledge concept can be captured. Furthermore, we propose an attention mechanism to adaptively fuse the context information from different meta-paths, in order to capture the different interests of different students. The promising experiment results show that the proposedACKRecis able to effectively recommend knowledge concepts to students pursuing online learning in MOOCs.
Mobile APP User Attribute Prediction by Heterogeneous Information Network Modeling
Oct 06, 2019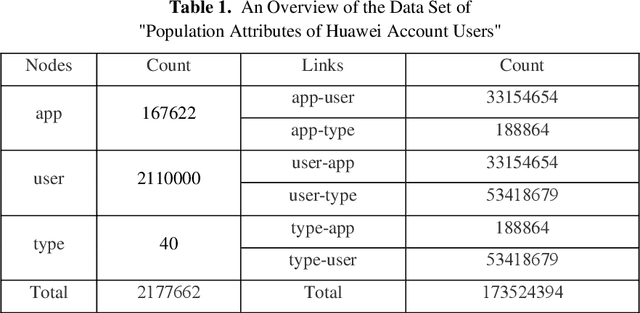
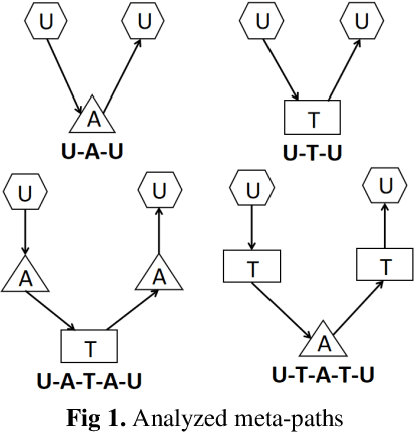
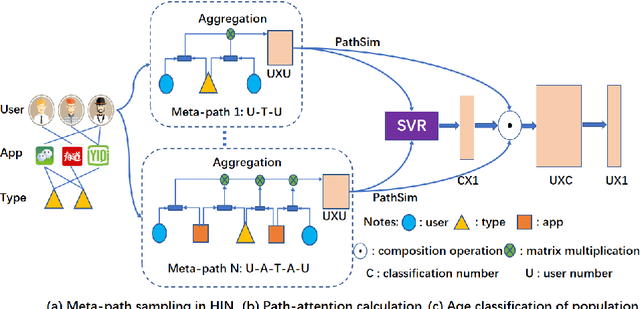
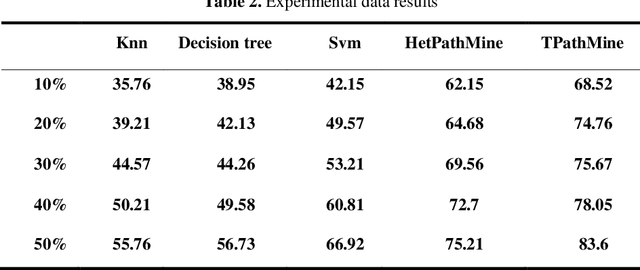
User-based attribute information, such as age and gender, is usually considered as user privacy information. It is difficult for enterprises to obtain user-based privacy attribute information. However, user-based privacy attribute information has a wide range of applications in personalized services, user behavior analysis and other aspects. this paper advances the HetPathMine model and puts forward TPathMine model. With applying the number of clicks of attributes under each node to express the user's emotional preference information, optimizations of the solution of meta-path weight are also presented. Based on meta-path in heterogeneous information networks, the new model integrates all relationships among objects into isomorphic relationships of classified objects. Matrix is used to realize the knowledge dissemination of category knowledge among isomorphic objects. The experimental results show that: (1) the prediction of user attributes based on heterogeneous information networks can achieve higher accuracy than traditional machine learning classification methods; (2) TPathMine model based on the number of clicks is more accurate in classifying users of different age groups, and the weight of each meta-path is consistent with human intuition or the real world situation.
W-RNN: News text classification based on a Weighted RNN
Sep 28, 2019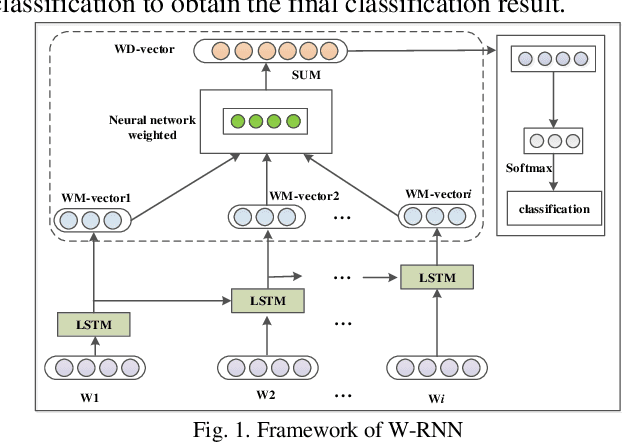
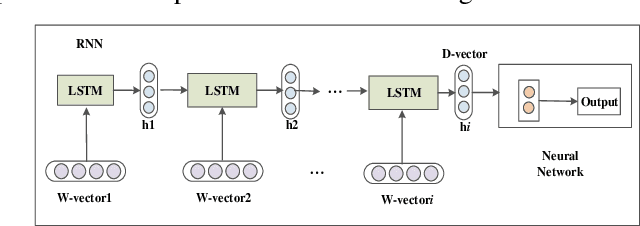
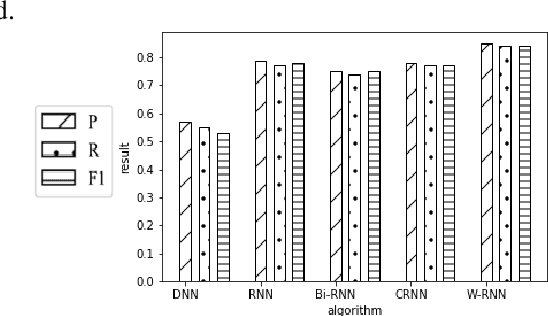
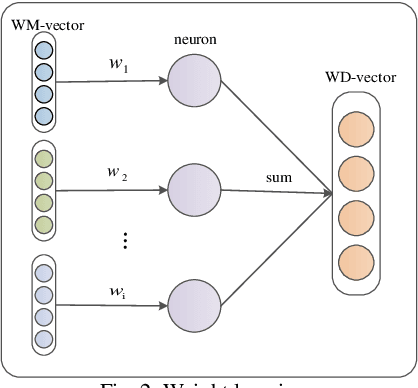
Most of the information is stored as text, so text mining is regarded as having high commercial potential. Aiming at the semantic constraint problem of classification methods based on sparse representation, we propose a weighted recurrent neural network (W-RNN), which can fully extract text serialization semantic information. For the problem that the feature high dimensionality and unclear semantic relationship in text data representation, we first utilize the word vector to represent the vocabulary in the text and use Recurrent Neural Network (RNN) to extract features of the serialized text data. The word vector is then automatically weighted and summed using the intermediate output of the word vector to form the text representation vector. Finally, the neural network is used for classification. W-RNN is verified on the news dataset and proves that W-RNN is superior to other four baseline methods in Precision, Recall, F1 and loss values, which is suitable for text classification.