 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeErrorLLM: Modeling SQL Errors for Text-to-SQL Refinement
Mar 04, 2026Despite the remarkable performance of large language models (LLMs) in text-to-SQL (SQL generation), correctly producing SQL queries remains challenging during initial generation. The SQL refinement task is subsequently introduced to correct syntactic and semantic errors in generated SQL queries. However, existing paradigms face two major limitations: (i) self-debugging becomes increasingly ineffective as modern LLMs rarely produce explicit execution errors that can trigger debugging signals; (ii) self-correction exhibits low detection precision due to the lack of explicit error modeling grounded in the question and schema, and suffers from severe hallucination that frequently corrupts correct SQLs. In this paper, we propose ErrorLLM, a framework that explicitly models text-to-SQL Errors within a dedicated LLM for text-to-SQL refinement. Specifically, we represent the user question and database schema as structural features, employ static detection to identify execution failures and surface mismatches, and extend ErrorLLM's semantic space with dedicated error tokens that capture categorized implicit semantic error types. Through a well-designed training strategy, we explicitly model these errors with structural representations, enabling the LLM to detect complex implicit errors by predicting dedicated error tokens. Guided by the detected errors, we perform error-guided refinement on the SQL structure by prompting LLMs. Extensive experiments demonstrate that ErrorLLM achieves the most significant improvements over backbone initial generation. Further analysis reveals that detection quality directly determines refinement effectiveness, and ErrorLLM addresses both sides by high detection F1 score while maintain refinement effectiveness.
The Semantic Lifecycle in Embodied AI: Acquisition, Representation and Storage via Foundation Models
Jan 12, 2026Semantic information in embodied AI is inherently multi-source and multi-stage, making it challenging to fully leverage for achieving stable perception-to-action loops in real-world environments. Early studies have combined manual engineering with deep neural networks, achieving notable progress in specific semantic-related embodied tasks. However, as embodied agents encounter increasingly complex environments and open-ended tasks, the demand for more generalizable and robust semantic processing capabilities has become imperative. Recent advances in foundation models (FMs) address this challenge through their cross-domain generalization abilities and rich semantic priors, reshaping the landscape of embodied AI research. In this survey, we propose the Semantic Lifecycle as a unified framework to characterize the evolution of semantic knowledge within embodied AI driven by foundation models. Departing from traditional paradigms that treat semantic processing as isolated modules or disjoint tasks, our framework offers a holistic perspective that captures the continuous flow and maintenance of semantic knowledge. Guided by this embodied semantic lifecycle, we further analyze and compare recent advances across three key stages: acquisition, representation, and storage. Finally, we summarize existing challenges and outline promising directions for future research.
LLHA-Net: A Hierarchical Attention Network for Two-View Correspondence Learning
Dec 31, 2025Establishing the correct correspondence of feature points is a fundamental task in computer vision. However, the presence of numerous outliers among the feature points can significantly affect the matching results, reducing the accuracy and robustness of the process. Furthermore, a challenge arises when dealing with a large proportion of outliers: how to ensure the extraction of high-quality information while reducing errors caused by negative samples. To address these issues, in this paper, we propose a novel method called Layer-by-Layer Hierarchical Attention Network, which enhances the precision of feature point matching in computer vision by addressing the issue of outliers. Our method incorporates stage fusion, hierarchical extraction, and an attention mechanism to improve the network's representation capability by emphasizing the rich semantic information of feature points. Specifically, we introduce a layer-by-layer channel fusion module, which preserves the feature semantic information from each stage and achieves overall fusion, thereby enhancing the representation capability of the feature points. Additionally, we design a hierarchical attention module that adaptively captures and fuses global perception and structural semantic information using an attention mechanism. Finally, we propose two architectures to extract and integrate features, thereby improving the adaptability of our network. We conduct experiments on two public datasets, namely YFCC100M and SUN3D, and the results demonstrate that our proposed method outperforms several state-of-the-art techniques in both outlier removal and camera pose estimation. Source code is available at http://www.linshuyuan.com.
Macro Graph of Experts for Billion-Scale Multi-Task Recommendation
Jun 12, 2025Graph-based multi-task learning at billion-scale presents a significant challenge, as different tasks correspond to distinct billion-scale graphs. Traditional multi-task learning methods often neglect these graph structures, relying solely on individual user and item embeddings. However, disregarding graph structures overlooks substantial potential for improving performance. In this paper, we introduce the Macro Graph of Expert (MGOE) framework, the first approach capable of leveraging macro graph embeddings to capture task-specific macro features while modeling the correlations between task-specific experts. Specifically, we propose the concept of a Macro Graph Bottom, which, for the first time, enables multi-task learning models to incorporate graph information effectively. We design the Macro Prediction Tower to dynamically integrate macro knowledge across tasks. MGOE has been deployed at scale, powering multi-task learning for the homepage of a leading billion-scale recommender system. Extensive offline experiments conducted on three public benchmark datasets demonstrate its superiority over state-of-the-art multi-task learning methods, establishing MGOE as a breakthrough in multi-task graph-based recommendation. Furthermore, online A/B tests confirm the superiority of MGOE in billion-scale recommender systems.
Fact in Fragments: Deconstructing Complex Claims via LLM-based Atomic Fact Extraction and Verification
Jun 09, 2025Fact verification plays a vital role in combating misinformation by assessing the veracity of claims through evidence retrieval and reasoning. However, traditional methods struggle with complex claims requiring multi-hop reasoning over fragmented evidence, as they often rely on static decomposition strategies and surface-level semantic retrieval, which fail to capture the nuanced structure and intent of the claim. This results in accumulated reasoning errors, noisy evidence contamination, and limited adaptability to diverse claims, ultimately undermining verification accuracy in complex scenarios. To address this, we propose Atomic Fact Extraction and Verification (AFEV), a novel framework that iteratively decomposes complex claims into atomic facts, enabling fine-grained retrieval and adaptive reasoning. AFEV dynamically refines claim understanding and reduces error propagation through iterative fact extraction, reranks evidence to filter noise, and leverages context-specific demonstrations to guide the reasoning process. Extensive experiments on five benchmark datasets demonstrate that AFEV achieves state-of-the-art performance in both accuracy and interpretability.
CheatAgent: Attacking LLM-Empowered Recommender Systems via LLM Agent
Apr 13, 2025Recently, Large Language Model (LLM)-empowered recommender systems (RecSys) have brought significant advances in personalized user experience and have attracted considerable attention. Despite the impressive progress, the research question regarding the safety vulnerability of LLM-empowered RecSys still remains largely under-investigated. Given the security and privacy concerns, it is more practical to focus on attacking the black-box RecSys, where attackers can only observe the system's inputs and outputs. However, traditional attack approaches employing reinforcement learning (RL) agents are not effective for attacking LLM-empowered RecSys due to the limited capabilities in processing complex textual inputs, planning, and reasoning. On the other hand, LLMs provide unprecedented opportunities to serve as attack agents to attack RecSys because of their impressive capability in simulating human-like decision-making processes. Therefore, in this paper, we propose a novel attack framework called CheatAgent by harnessing the human-like capabilities of LLMs, where an LLM-based agent is developed to attack LLM-Empowered RecSys. Specifically, our method first identifies the insertion position for maximum impact with minimal input modification. After that, the LLM agent is designed to generate adversarial perturbations to insert at target positions. To further improve the quality of generated perturbations, we utilize the prompt tuning technique to improve attacking strategies via feedback from the victim RecSys iteratively. Extensive experiments across three real-world datasets demonstrate the effectiveness of our proposed attacking method.
FilterLLM: Text-To-Distribution LLM for Billion-Scale Cold-Start Recommendation
Feb 24, 2025Large Language Model (LLM)-based cold-start recommendation systems continue to face significant computational challenges in billion-scale scenarios, as they follow a "Text-to-Judgment" paradigm. This approach processes user-item content pairs as input and evaluates each pair iteratively. To maintain efficiency, existing methods rely on pre-filtering a small candidate pool of user-item pairs. However, this severely limits the inferential capabilities of LLMs by reducing their scope to only a few hundred pre-filtered candidates. To overcome this limitation, we propose a novel "Text-to-Distribution" paradigm, which predicts an item's interaction probability distribution for the entire user set in a single inference. Specifically, we present FilterLLM, a framework that extends the next-word prediction capabilities of LLMs to billion-scale filtering tasks. FilterLLM first introduces a tailored distribution prediction and cold-start framework. Next, FilterLLM incorporates an efficient user-vocabulary structure to train and store the embeddings of billion-scale users. Finally, we detail the training objectives for both distribution prediction and user-vocabulary construction. The proposed framework has been deployed on the Alibaba platform, where it has been serving cold-start recommendations for two months, processing over one billion cold items. Extensive experiments demonstrate that FilterLLM significantly outperforms state-of-the-art methods in cold-start recommendation tasks, achieving over 30 times higher efficiency. Furthermore, an online A/B test validates its effectiveness in billion-scale recommendation systems.
Knapsack Optimization-based Schema Linking for LLM-based Text-to-SQL Generation
Feb 18, 2025



Generating SQLs from user queries is a long-standing challenge, where the accuracy of initial schema linking significantly impacts subsequent SQL generation performance. However, current schema linking models still struggle with missing relevant schema elements or an excess of redundant ones. A crucial reason for this is that commonly used metrics, recall and precision, fail to capture relevant element missing and thus cannot reflect actual schema linking performance. Motivated by this, we propose an enhanced schema linking metric by introducing a restricted missing indicator. Accordingly, we introduce Knapsack optimization-based Schema Linking Agent (KaSLA), a plug-in schema linking agent designed to prevent the missing of relevant schema elements while minimizing the inclusion of redundant ones. KaSLA employs a hierarchical linking strategy that first identifies the optimal table linking and subsequently links columns within the selected table to reduce linking candidate space. In each linking process, it utilize a knapsack optimization approach to link potentially relevant elements while accounting for a limited tolerance of potential redundant ones.With this optimization, KaSLA-1.6B achieves superior schema linking results compared to large-scale LLMs, including deepseek-v3 with state-of-the-art (SOTA) schema linking method. Extensive experiments on Spider and BIRD benchmarks verify that KaSLA can significantly improve the SQL generation performance of SOTA text-to-SQL models by substituting their schema linking processes.
Benchmarking Large Language Models via Random Variables
Jan 20, 2025With the continuous advancement of large language models (LLMs) in mathematical reasoning, evaluating their performance in this domain has become a prominent research focus. Recent studies have raised concerns about the reliability of current mathematical benchmarks, highlighting issues such as simplistic design and potential data leakage. Therefore, creating a reliable benchmark that effectively evaluates the genuine capabilities of LLMs in mathematical reasoning remains a significant challenge. To address this, we propose RV-Bench, a framework for Benchmarking LLMs via Random Variables in mathematical reasoning. Specifically, the background content of a random variable question (RV question) mirrors the original problem in existing standard benchmarks, but the variable combinations are randomized into different values. LLMs must fully understand the problem-solving process for the original problem to correctly answer RV questions with various combinations of variable values. As a result, the LLM's genuine capability in mathematical reasoning is reflected by its accuracy on RV-Bench. Extensive experiments are conducted with 29 representative LLMs across 900+ RV questions. A leaderboard for RV-Bench ranks the genuine capability of these LLMs. Further analysis of accuracy dropping indicates that current LLMs still struggle with complex mathematical reasoning problems.
Cold-Start Recommendation towards the Era of Large Language Models (LLMs): A Comprehensive Survey and Roadmap
Jan 03, 2025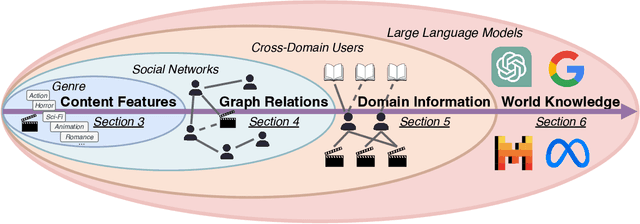
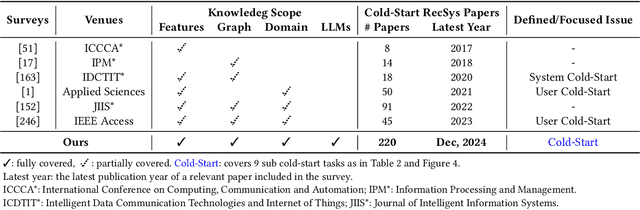
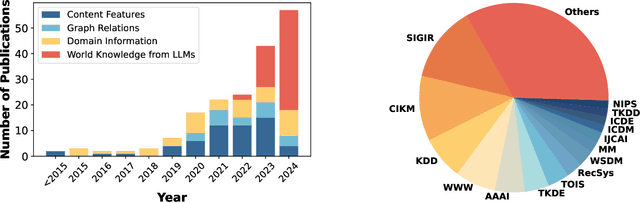
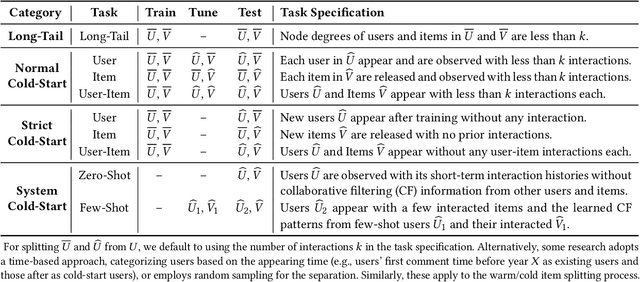
Cold-start problem is one of the long-standing challenges in recommender systems, focusing on accurately modeling new or interaction-limited users or items to provide better recommendations. Due to the diversification of internet platforms and the exponential growth of users and items, the importance of cold-start recommendation (CSR) is becoming increasingly evident. At the same time, large language models (LLMs) have achieved tremendous success and possess strong capabilities in modeling user and item information, providing new potential for cold-start recommendations. However, the research community on CSR still lacks a comprehensive review and reflection in this field. Based on this, in this paper, we stand in the context of the era of large language models and provide a comprehensive review and discussion on the roadmap, related literature, and future directions of CSR. Specifically, we have conducted an exploration of the development path of how existing CSR utilizes information, from content features, graph relations, and domain information, to the world knowledge possessed by large language models, aiming to provide new insights for both the research and industrial communities on CSR. Related resources of cold-start recommendations are collected and continuously updated for the community in https://github.com/YuanchenBei/Awesome-Cold-Start-Recommendation.